 以人为主体目标的图像理解与编辑任务
以人为主体目标的图像理解与编辑任务
通过对视野内景物位置关系的描写,一幅登高远眺的秋色美景图宛在眼前。而在计算机视觉领域,这几句诗其实体现了场景内物体之间的关系,对于场景理解的重要性。
今天,来自中科院信息工程研究所的刘偲副研究员,将从生成对抗网络(GAN)讲起,讲述如何通过对场景内物体及物体之间关系的梳理,让机器“析毫剖厘”,以实现对场景的理解以及对图像的编辑。
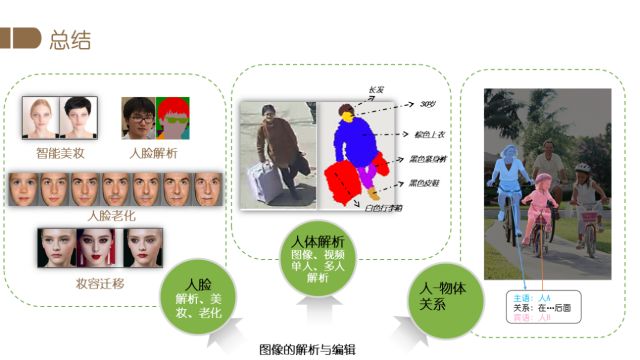
图像理解与编辑涉及两方面的内容:首先获取图像中蕴含的丰富信息,然后按照需求对图像进行编辑。下图展示了图像理解问题的具体示例,对于某个场景,我们提取图像中的背景,如墙壁、桌椅等物体的信息,也可以解析图像中的重要元素——人,即对人的身体、服饰等部件进行分类、分割,进一步的还可对人脸进行解析,定位头发、五官等部位。图像理解与编辑具有广泛的应用场景,比如自动驾驶、娱乐产品、视频监控和增强现实等方面。
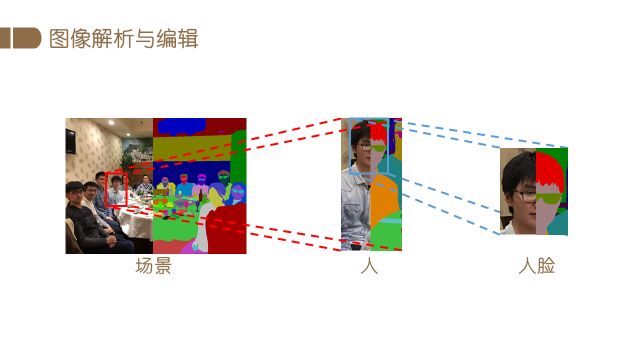
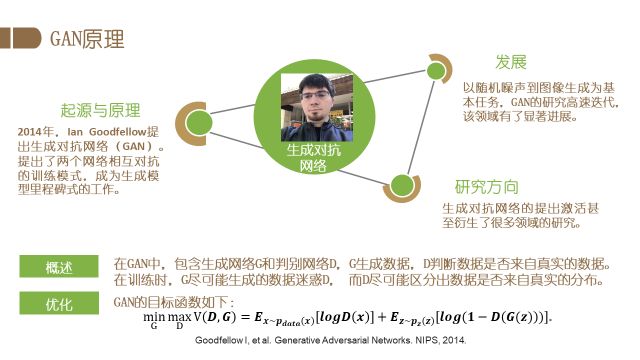
本文将主要介绍以人为主体目标的图像理解与编辑任务。首先介绍人脸编辑。在图像编辑方面,生成对抗网络(GAN)发挥着重要的作用,所以这里首先介绍一下GAN的基本原理以及当前的主要发展方向。GAN由Ian Goodfellow在2014年提出,采用了两个网络相互对抗的训练模式,已成为生成模型中里程碑式的工作。GAN包含生成网络G和判别网络D,G生成数据,D判断数据是否来自真实的数据。在训练时,G尽可能生成的数据迷惑D,而D尽可能区分出数据是否来自真实的分布,通过这种对抗式学习,模型最终能够生成非常真实的图片。这一工作也得到了Yann Lecun的高度评价,被其称为近十年来机器学习领域中最有趣的想法之一。
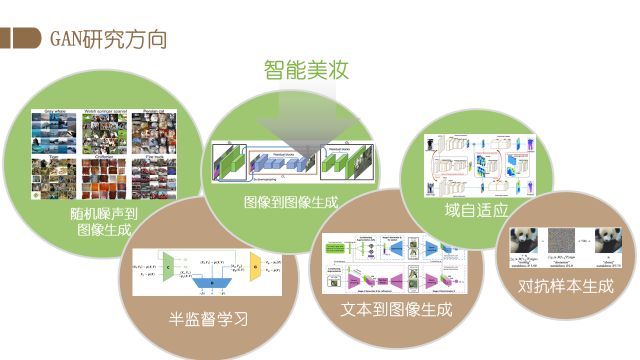
从2014年GAN的提出,实现了从噪声生成图片功能后,生成对抗网络的研究方向越来越多。原始的GAN只是从随机噪声生成图像,缺少对生成图片的控制,所以紧随其后就有研究者提出了Conditional Generative Adversarial Nets。其通过改变输入条件,可以控制图片的生成结果。同时,以DCGAN为代表的一系列工作探索了适用于GAN的网络结构。也有研究者为了解决模式坍塌等问题,提出了更多的网络形式进行对抗学习的研究,如GMAN。 修正GAN的对抗损失函数的工作也在一直进行中,WGAN是其中非常引人瞩目的工作。此外,要拟合真实数据背后的分布度量,常常需要对D网络进行正则化, SN-GAN提出的谱归一化是其中的代表性工作,其可在IMAGENET数据库上训练成功,生成1000类的图像。最后,提高大图像的生成质量也是GAN的一个重点的研究方向。英伟达提出的PG-GAN即是这样的工作,可以生成1024x1024的高清真实图像。

总而言之,GAN由最开始的随机噪声生成图片,逐渐在众多领域得到发展。有研究者使用GAN研究半监督学习问题,也有研究者进行图像到图像的生成探索,如给定轮廓图生成正常的图片,另外还有文本到图像的生成以及域自适应任务。域自适应任务旨在提升模型对跨域数据的泛化能力,如在一个数据集上训练好图像分析的模型,通过域适应的方法,在其他不同的数据集上仍然能够表现出较强的能力。此外还有人用GAN来做对抗样本的攻防,旨在解决生成模型的正确性和安全性的问题。
基于GAN,在人脸图像编辑方面,我们课题组主要进行了智能美妆方面的研究,属于图像到图像的生成领域的探索。首先我们构建了一个较大的美妆数据库,包括东方风格和西方风格的子数据库。东方风格包括复古妆、韩妆、日妆、素颜和烟熏妆,西方风格包括彩妆、素颜和烟熏妆。如图所示,每种妆容都有明确的定义。

除数据库外,我们基于生成对抗网络对智能美妆模型做了一定的改进,这项工作目前还在进行中。具体包括两方面改进,第一基于大规模的人脸数据库辅助生成更高质量的美妆图像,目前是基于20万张的celebA人脸图像数据,选取包括是否为浓妆在内的总共三个人脸相关的属性,利用粗标注数据库完成智能美妆任务的辅助训练,从而使美妆属性的编辑更加细致。此外我们提出了新的网络结构。因为人脸编辑任务更多是人脸的微调,希望化完妆人的身份信息保持不变,我们的网络强调保持妆前妆后基本一致,更好的保持了图像的主体信息,更专注地编辑妆容条件。

观察实验结果,各种妆容的编辑结果比较真实、自然,没有明显的网格。各种妆容的特点也比较明显,如亚洲风格妆容中复古妆的腮红、韩妆渐变的咬唇妆,比较淡的日妆以及特征明显的素颜和烟熏妆,同样欧美风格的妆容也有较好的编辑效果。值得一提的是,由于素颜类别的存在,我们的方法也可以实现卸妆的功能。
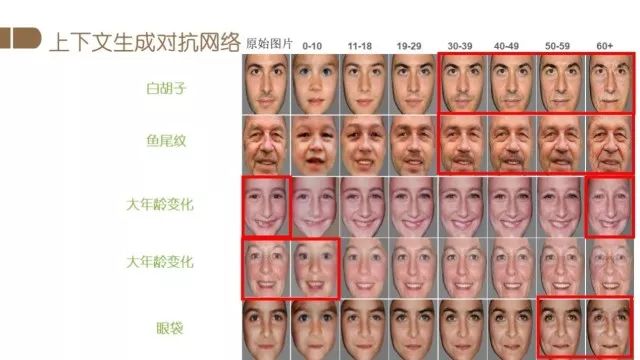
针对人脸编辑的另一个应用是人脸老化。下图中间是当前给定图片,通过人脸老化算法可以生成7个不同年龄段的人脸图像,即可以变年轻如10岁以下,也可以变老如一直到60岁以上。它的应用很广泛,比如可以辅助跨年龄段的人脸识别。身份证照片常常是很多年前拍摄的,长时间没有更新导致人证对比存在一定的难度,那么此时人脸老化的就可以辅助身份证的人证识别。另外比较有用的应用是寻找丢失的儿童,比如小孩走丢了,只有他很小的照片,人脸老化可以辅助生成长大后的样子,我们希望可以通过这样的算法,能够实现跨年龄的身份识别。此外人脸老化编辑还可以应用到互动娱乐应用中。
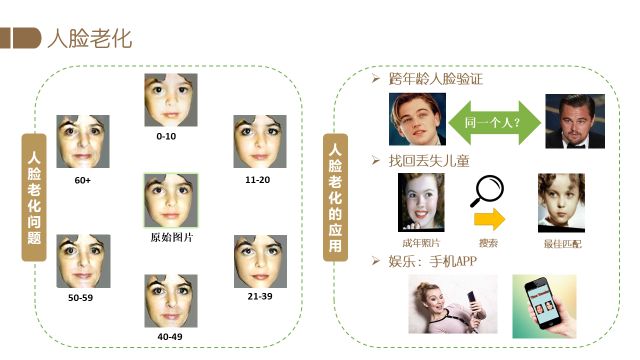
我们提出的方法也是基于GAN的。在传统的conditional GAN的基础上,我们综合考虑了不同年龄段人脸的形状和纹理变化。具体实现细节可参考我们的相关论文。下图是我们的结果,第一列是原始图片,右边七列分别是不同年龄条件下的生成结果。可以看到年龄较小时,脸型都相对较小,皮肤也很光滑,而从30岁到60岁,胡子越来越白,同时会出现鱼尾纹或者皱纹。例如第四行输入是一个老太太,模型能够生成她比较小的样子,皮肤非常光滑,同时很像这个人。
接下来介绍整个框架第二部分,就是人的部分。人体解析定义是这样的,给定一张图,去解析人的头发、人脸、胳膊(手)等部位,以及上衣、裤子、鞋等衣着。人体解析的相关工作非常多,由于篇幅限制不再详细说明。而数据集方面主要是中山大学发表在CVPR2017上的Look into person,它应该是目前最大的人体解析数据库。
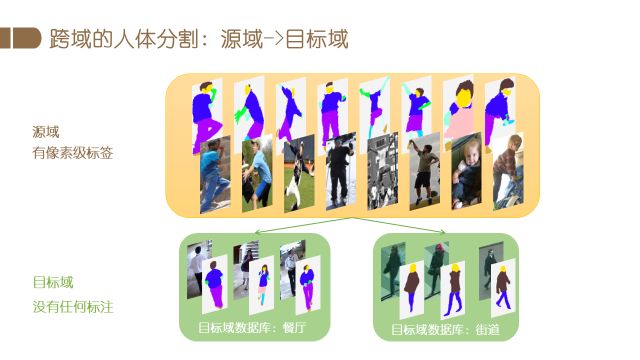
我们在人体解析方面的最新研究是有关跨域人体解析。因为比如想在多个城市建立图像分析系统,不可能在每个场景都标注很多数据,但是不同应用场景很多条件确实不一样。所以我们希望一旦建立了较好的模型,通过跨域的方法,该模型放在其他的特定场景中也可以使用。比如数据库标了很细致像素级的分类,这些库姿态多变,光照很多,数据量大。我们在实际应用的时候,比如想应用在室内餐厅,或者室外街道,这种情况下重新标注数据的代价是非常大的,而直接使用预先训好的模型效果又不是特别好。我们想研究的就是已经训练好的模型怎么使用。
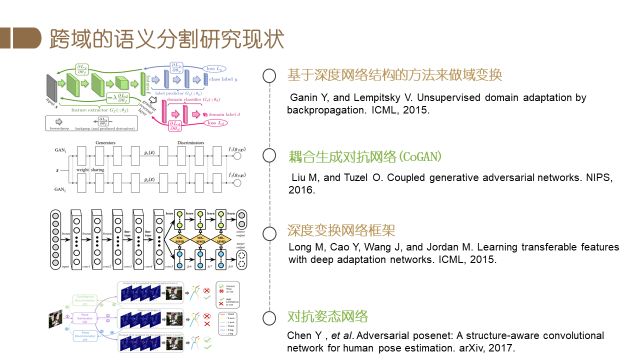
跨域学习是近年来的一个研究热点,相关论文很多。比如,Ganin等人提出了一种新的基于深度网络结构的方法来做域变换,该方法促进网络学习一种深度特征:既能对主要的学习任务上得到区分,又能在不同域之间达到一致。MY Liu等人提出了一个耦合生成对抗网络(coupled generative adversarial network, CoGAN)来学习关于多个域图片的联合分布。Long等人提出的一种新的深度变换网络框架,通过MK-MMD将适应于特定任务的深度特征进行变换,而Chen等人提出了对抗姿态网络,潜在地考虑到了人物的结构。
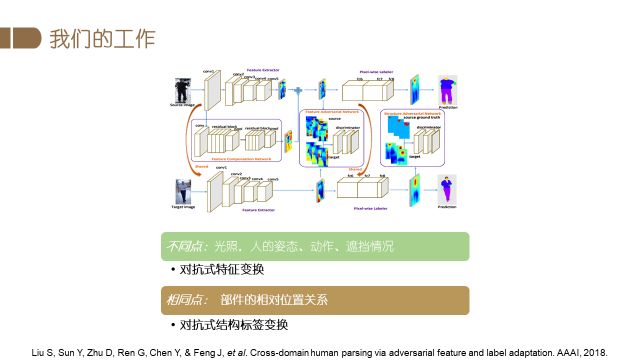
当前已经存在的域变换方法,都是单一考虑特征变换或者简单地考虑结构性的标签变换,而我们同时考虑了特征变换和结构性的标注变换。首先一方面,每个域的特征空间是不同的。例如餐厅中的图片光照比室外中的光照要暗很多,监控图片的视角和手持相机拍摄也是不同。因此我们通过对抗特征变换最小化这种差异。然后另一方面源域和目标域中的人物都有着固有的相同点,例如人体部件的关系大概是相同的,左右胳膊、腿分布在身体的两侧等。因此我们通过对抗式结构标签变换来最大化这种共性。
最后一个任务是综合考虑到人和场景。今年ECCV的一项竞赛就是我们和奇虎360公司以及新加坡国立大学(NUS)一起举办的。比赛的主要任务还是集中于人这一目标,希望能够获取图像中最重要的元素——人的信息。

Person In Context (PIC) 2018 (http://www.picdataset.com/) 将于2018年9月9日在德国慕尼黑的ECCV 2018的workshop "1st Person in Context (PIC) Workshop and Challenge" 上举办。我们从真实场景收集了约1.5万张图像,平均每张图包含4个人。这些图像包含复杂的人的姿态、丰富的拍摄视角、不同程度的遮挡和图像分辨率。每一张图片都包含了人和物体像素级别的语义分割、场景分割以及人和人/物体的关系标注。在客观世界不计其数的类别中,人是最特殊的一类。因此本竞赛在任务设定过程中,着重考量了以人为中心的关系分割 (relation segmentation)。传统的关系预测,比如Visual Genome,以及Google 的Open Image Challenge 的关系都是定义在矩形框(bounding box)上的。PIC竞赛的特别之处是,其关系是定义在分割区域(segmentation)上的。
以人为中心的关系分割包括该人的和周围物体的动作关系、位置关系等。以左图为例,人A在人B的旁边。再比如右图,人A在人C的后面。关系分割的形式是<主语,关系,宾语> 形式的三元组。值得一提的是,关系都是建立在人和物体的场景像素级别分割之上的。
以下为数据库的标注展示,可以看到该数据库涵盖了丰富的全景分割和关系分割。
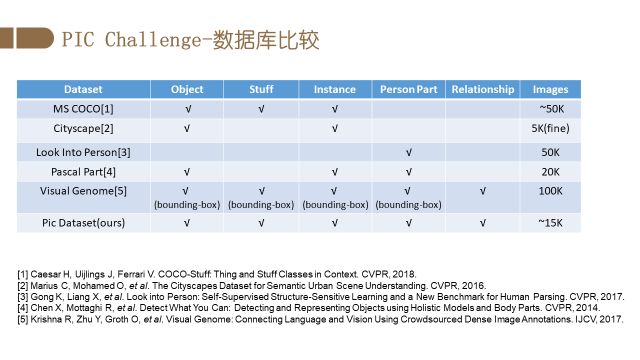
上图是PIC跟现有数据库的区别。Visual Genome是知名的关系数据库。其关系是定义在bounding-box上,PIC库的关系是定义在像素级别的分割之上。这种更细粒度的标注,使得定义的关系更为精确,也更符合实际应用的要求。
我们竞赛时间安排及竞赛信息如下,同时我们还提供了众多显卡作为竞赛奖品。冠军队伍可以获得2块TitanV 显卡。
总结一下,我们的工作由小及大,包含了人脸,人以及人-物关系三个层面的内容。我们会在这些领域继续进行探索。
-
图像
+关注
关注
2文章
1089浏览量
40600 -
GaN
+关注
关注
19文章
1974浏览量
74460
原文标题:让机器“析毫剖厘”:图像理解与编辑|VALSE2018之三
文章出处:【微信号:deeplearningclass,微信公众号:深度学习大讲堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于多智能主体系统的工程机械机群智能化研究
基于FPGA的实时移动目标的追踪
红外图像小目标检测系统该怎么设计?
红外运动弱小目标的动态规划检测
基于视频图像的运动目标检测与识别
基于目标检测的SAR图像匹配算法
基于Opencv的运动目标的检测和跟踪
构建以医院为主体的互联网医疗新模式,进一步改善医疗服务
解析在目标检测中怎么解决小目标的问题?
基于行为主体定位的视频快速检测方法
图像分类任务的各种tricks
高效理解机器学习
导弹制导系统是如何定位目标的?





 工商网监
工商网监
评论