 基于网络流量的非标准工控协议逆向识别方法
基于网络流量的非标准工控协议逆向识别方法
协议安全是工业控制系统信息安全中的一项重要内容,非标协议格式的正确识别是协议安全分析的基础。基于工控系统行业现状和工控协议的结构确定、传输重复、语义有限的特性,提出了基于网络流量的非标准工控协议逆向识别方法,通过单报文处理进行初步分词聚类,多报文处理进行报文序列比对,关键字段推断语义,最终得到协议格式。验证结果表明,该方法能较好地识别非标工控协议格式。
0 引言
随着2010年“震网病毒”的出现,工业控制系统(Industrial Control Systems,ICS)的安全性越来越受到全球范围的关注[1]。接口环节是ICS中的关键环节,而通信协议又是接口的核心,工控协议的安全性分析已成为等级保护等安全测评中一项重要的内容。各工控厂商或个人出于提供个性化功能、优化通信性能、简化协议实现的复杂度等因素的考虑,导致工控行业中有大量的非标准协议存在。非标工控协议安全性分析采用的模糊测试等方法的前提是已知协议的格式信息,所以非标工控协议格式逆向识别成为了工控信息安全中的一项重要内容。
以往,非标工控协议的格式结构信息主要通过人工逆向的方式来获得,但这种方法往往耗时费力且结果不准确。工控协议与信息系统应用协议的区别导致信息系统应用协议逆向识别方法对非标工控协议的识别度不高。因此,需要研究适用于非标工控协议的格式逆向识别方法。
1 协议逆向技术和工控协议特点
1.1 协议逆向技术介绍
协议逆向工程(Protocol Reverse Engineering,PRE)指在不依赖于协议描述的情况下,通过对协议实体的网络输入输出、系统行为和指令执行流程进行监控和分析,提取协议语法、语义和同步信息的过程[2]。根据分析对象的不同,协议格式逆向分析技术分为基于网络流量和基于执行轨迹的协议格式逆向分析技术。
基于网络流量的协议格式逆向分析技术以网络数据流为分析对象,根据协议字段的取值变化频率和特征推断得到协议格式。其依据是数据流中的单个报文样本是协议格式的一个实例,相同格式的报文样本具有相似性,不同格式的报文样本具有一定的差异性,可以将具有相似性的报文汇集在一起,推断它们所遵循的报文格式。这种分析技术仅依赖于所捕获的网络数据包,具有比较好的通用性,因此应用较广泛。
基于执行轨迹的协议格式逆向分析技术主要对实现协议的二进制可执行程序进行逆向分析,获得程序具体处理网络通信数据包的指令执行序列。其主要依据是程序对数据包的处理按照定义好的数据包格式进行,通过对程序执行的跟踪,可以获得协议的部分或全部语义、语法信息。该技术方法除需获取通信数据包外,还需获得协议的实体可执行程序,这导致该技术在应用范围方面有一定的局限性。表1为基于网络流量和基于执行轨迹两种技术的比较及代表性的项目。

1.2 工业控制协议特点
工控协议是指工业控制网络中现场设备、控制器、操作员站、通信和应用等服务器、工程师站之间数据通信的规定,与系统功能和网络架构密切相关,对成套设施级可编程逻辑控制器(Programmable Logic Controller,PLC)、厂站级分布式控制系统(Distributed Control System,DCS)、广域的数据采集和监控系统(Supervisory Control and Data Acquisition,SCADA),分别发挥提供核心基础能力的作用。随着工控行业的发展,工控协议更多地采用基于以太网的通信协议方式,按照TCP/IP协议体系结构的划分,工控以太网协议主要是应用层协议。
相比较于传统的基于以太网的信息系统应用协议,工业控制协议通常具有以下特点:
(1)传输信息中,以二进制形式表示的模拟量、数字量类型信息比较多,文本类型信息少,视频类信息独立传输;
(2)多数信息有实时性要求,通信过程要在规定的时限内完成,否则就会造成数据质量失效;
(3)有相对明确的数据生成者与使用者,许多传输过程也在确定的物理环境中进行,通常认为通信环境比较清洁,许多通信数据不加密;
(4)协议中采用多种交互控制方式,如请求应答交互、周期主动传输,也提供多种流量优化机制,如变化传输、事件订阅等;
(5)在自动控制层,使用包含工业以太网等多种形式的现场总线,而在本地和远程监控层,基础层多采用基于以太网的TCP、UDP等可路由协议;
(6)出于工业应用的可靠性、安全性要求,通信数据包具有一定的检错、容错,甚至是纠错能力,可保证数据的完整性;
(7)多数情况下,数据包具有相对一致的协议控制结构和数据内容结构,如开始和截止标记、报文发送者和接收者标识、报文功能码、报文长度、校验码等。图1为一些工控协议格式结构示例。

2 非标工控协议格式逆向识别方法
工业控制网络中协议处理程序主要集成在ICS厂商提供的专用软件或硬件设备中,所以不易获取协议处理的可执行程序,而获取工控网络中的数据流量相对简单。所以对工控协议的逆向分析多采用基于网络流量的方式。根据工控协议的特点,提出通过主要预处理、单报文处理、多报文处理、语义推断4个阶段逆向分析工控协议的方法,如图2所示。
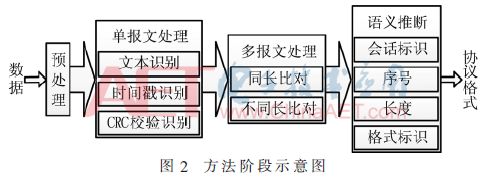
2.1 数据预处理
通过接入工控系统网络中捕获网络中通信数据,作为原始数据源。根据IP地址、端口号等分包过滤出需要分析的特定通信实体间的通信数据,作为逆向分析的报文序列样本集。对报文序列中出现的丢包、重传、乱序等情况进行处理;滤除不含负载的报文;丢弃校验和出错的报文;将IP分片的报文进行重组;对于TCP会话,一个完整会话以SYN报文开始,以FIN/RST报文结束。由于工控数据往往要求实时性,因此本文不考虑单个TCP报文中包含多个应用层协议的情况。
对于应用层协议的逆向,需要将数据包按照TCP/IP协议格式进行自底向上的解除封装,依次去除数据链路层、网络层和传输层的格式封装,得到完整应用层报文。
2.2 单报文处理
单报文处理的作用是对协议数据进行分词,并依据分词结果将协议数据包进行聚类划分。分词是指识别区分出报文中的一些特殊字段。单报文分词指识别出仅单个报文就可识别出的字段,如文本字段、时间戳字段、校验码字段等。根据报文中识别出的字段属性对报文进行聚类划分,可得到不同类型的报文组类。下面主要说明文本字段和时间戳字段的识别。
(1)文本字段识别。将报文字节流中属于ASCII码中可打印字符取值范围内的连续字节,将其识别为文本字段;否则为二进制字段[7]。为了避免将属于二进制字段的字节错误地识别为文本字段,限定文本字段的长度必须超过设定的文本长度最小阈值。由于工控协议中传输文本的数据包相对较少且格式相对单一,因此可将含有文本字段的报文聚为一类进行处理。图3中框中部分为报文中的文本字段。

(2)时间戳字段识别。将报文中连续的4 B或8 B数据按照时间戳(Unix timestamp)的方式进行计算得到时间值,如果该值在报文捕获时间的固定误差范围内,可将该4 B或8 B标识为时间戳字段。图4中框中部分即为小端字序表示的时间戳字段,时间值为2016年11月30日09:51:21.507340209。

2.3 多报文处理
多报文处理的作用是在划分出同一报文组中的报文内容固定段与非固定段、定长段和不定长段。序列比对是样本再划段和语义推断的前提。由于工控协议往往具有格式相同或相近、传输信息重复性高、同类型报文长度等长等特性,可以优先进行同长报文比对,按比对结果再分类得到不同格式类型;再将得到的格式类型相或相近的不同长报文进行不同长报文比对。最终得到多个不同格式样本的子集。
同长度报文比对主要是划分出相同长度报文组中报文内容的不变段与变化段。为了避免将同一初始分类组中长度相同但格式不同的报文进行强行比对,影响比对的准确度,需要设定距离阈值,在距离过大时停止比对,并将之再分类。依据比对结果划分标记变化段和不变段。
不同长报文比对主要是识别出长度不同、但格式相同或相近的报文中内容数据定长段和不定长段。采用时间和空间复杂度都相对比较适合的渐进多序列比对算法。参考PI项目中的渐进比对算法,主要包括3个步骤:(1)采用Smith-Waterman算法找出任意两个样本之间的局部最佳比对,据此计算样本间的相似度,并构造样本集的距离矩阵;(2)采用非加权成对群算术平均法(Unweighted Pair Group Method with Arithmetic means,UPGMA)计算子类间的距离,逐步将距离最小的子类进行合并;(3)执行渐进多序列比对,采用Needleman-Wunsch算法进行双序列动态规划比对[8],对未对齐的字节进行补充。为减少算法复杂度,对同长报文比对后分类的各类中选取少数样本组合成作为样本集进行不同长报文比对。
2.4 字段语义推断
字段的语义表示协议将如何使用该字段,包括会话标识符、序号、地址、长度字段、格式标识字段、校验和、时间戳等。以不同字段在协议语法层次中表现出的不同特征作为语义推断的依据,对不同字段按照相应的识别方法进行识别。由于单报文处理中已将文本字段、时间戳字段、校验和字段等进行了识别,因此该阶段主要在二进制数据段内对标识符、序号、长度、地址、功能码、数据等字段进行识别。最后对提取的格式进行整理融合,最终得到协议的格式结构。
序号字段是用于标识报文在一个会话的先后顺序。特征是一般靠近段首,取值一直变化,且与报文的截获先后顺序相对应。可以对未知的数值变化段进行判断,如其取值变化与报文的截获序号成正相关的关系,则判定为序号字段。
长度字段是报文中用于定界的字段,字段长度通常为2 B或4 B,取值与样本中的某一字段或连续的某几个字段的长度相等,作用域通常在该字段之后或包含所有字段。识别策略为判断该字段值与其后的某一字段或连续的某几个字段的长度、或与所有字段总长度是否相等,若相等则判定为长度字段。
格式标识字段是指用于区别报文中部分子格式序列的关键字段,多为协议格式字段或功能码字段,格式标识字段的取值一般类型较少、变化率小,且与后续字段序列的格式相关联,作用域多位于其后区域。如果该字段变化导致后部所有字段格式发生变化,将其识别为协议格式字段。
数据字段是指对报文结构和其他关键字段影响不大或没有直接影响的可变字段,一般指报文的负载。特征是随机性强,且变化无规律可循,长度可能不固定,通常位于协议后部或尾部,对于序列比对中需要插入空位的可变字段,判定为数据字段,文本字段也判定为数据字段。
3 方法验证
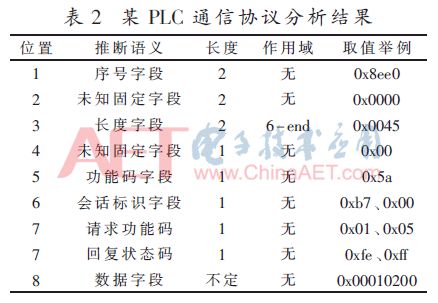
以两种典型ICS系统中的通信数据作为数据源进行验证。以某PLC与工程师站组态软件之间的通信协议数据包为数据源,采用本文所述方法对协议进行逆向识别,识别的格式结果如表2所示。
以某DCS中的通信数据为数据源,对其进行协议的逆向识别,得到3种主要的协议格式类型,如图5所示,格式I、II中请求报文格式和应答报文的格式不同,格式III请求和应答采用同种格式。

4 结论
工控协议逆向格式识别是协议安全性分析的重要前提。本文根据工控协议的特点,提出基于网络流量技术,采用单报文处理、多报文处理、字段语义推断3个阶段进行协议格式逆向识别的方法。通过对两种协议数据源的验证可以看出,本文方法能较好地逆向协议格式,提取出协议格式标识、序号、长度、数据等关键字段。
受基于网络流量逆向分析技术的局限性,本文方法对协议功能码具体语义的识别率较低。未来研究方向为将人工先验知识和机器学习方法引入协议逆向识别中,同时结合协议上下文,实现更高的样本覆盖率,以提高协议逆向识别的准确度,同时得到协议转换的状态机。
-
协议
+关注
关注
2文章
602浏览量
39244 -
通信数据
+关注
关注
0文章
13浏览量
9981 -
工控系统
+关注
关注
1文章
99浏览量
14568
原文标题:【学术论文】非标工业控制协议格式逆向方法研究
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
网络流量监控与网关优化
一种混合颜料光谱分区间识别方法
基于Python的深度学习人脸识别方法
艾体宝干货 IOTA流量分析秘籍第一招:网络基线管理
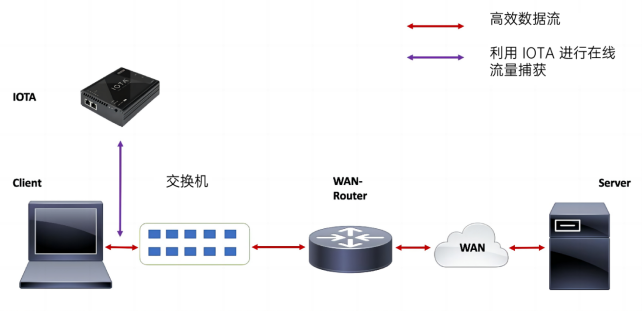
艾体宝干货 | 教程:使用ntopng和nProbe监控网络流量

stm32mp157在linux系统下,串口的波特率如何使用非标准波特率?
询问2.2V的非标准ttl电平转3.3V的cmos电平转换器
TC275D系列的芯片支持标准CANFD能配置成非标准CANFD的吗?
贴片电感的识别方法及故障更换方法
网络监控工具有哪些 网络监控用几芯网线
虹科分享 | 实现网络流量的全面访问和可视性——Profitap和Ntop联合解决方案






 工商网监
工商网监
评论