 谷歌说机器学习还能产生“偏见”?你有偏见吗?
谷歌说机器学习还能产生“偏见”?你有偏见吗?

机器学习也会对数据产生偏见,从而导致错误的预测。我们该如何解决这一问题? Google的新论文或许会揭晓答案。 机器学习中的机会均等 随着机器学习计算稳步发展,越来越多人开始关注其对于社会的影响。机器学习的成功分支之一是监督学习。有着足够的历史遗留

机器学习中的机会均等
随着机器学习计算稳步发展,越来越多人开始关注其对于社会的影响。机器学习的成功分支之一是监督学习。有着足够的历史遗留数据和计算资源,学习算法预测未来事件的效果往往令人震惊。以一个假设为例,算法可以被用来高精度预测谁将会偿还他们的贷款。贷款人可能会使用这样的预测,以帮忙决定谁应该首先得到贷款。基于机器学习做出的决定,其实用性往往令人难以置信,并对我们的生活产生了深远的影响。
然而,最好的预测也可能出错。尽管机器学习致力于最小化出错的可能性,但我们该如何防止某些组非均匀的共享这些错误?考虑到一些情况下,我们拥有的数据相对较少,且其特征不同于那些与预测任务相关的大众方法。由于预测精度一般与训练的数据量息息相关,一些组中的错误预测将会更加常见。例如,尽管他们偿还了贷款,预测最后也可能将过多的个体标记到“高违约风险”组中。当组中的成员恰逢一个敏感属性,如种族、性别、残疾、或宗教时,便会导致不公正的或有偏见的结果。
尽管需要,但机器学习中一直缺乏防止这类歧视,且基于敏感属性的审核方法。有一种憨厚的方法是在做任何其他事之前,从数据中删除一组敏感属性。其想法是一种“无意识的不公平”,然而,由于存在“冗余编码”也未能成功。即使在数据中不存在某个特定的属性,其他属性的组合也可以作为代理。
另一个普用方法被称之为“统计平价”,其要求预测必须与敏感属性无关。这直观上听起来是可取的,但结果本身往往与敏感属性相关。例如,男性心脏衰竭的发病率通常比女性更高。当预测这样的医疗情况时,要阻断预测结果和组成员之间的一切相关性,既不现实,也不可龋
机会平等
考虑到这些概念上的困难,我们已经提出了一种方法,用于测量和防止基于一系列敏感属性所产生的歧视。我们还展示了如何调整一个给定的预测,需要的话,它可以更好的权衡分类精度和非歧视。
我们想法的核心是,符合理想结果的个体,应因此而拥有平等正确分类的机会。在我们虚构的贷款例子中,它意味着预测“低风险”会实际偿还贷款的人不应该依赖于敏感属性,如种族或性别。我们称之为监督学习中的机会均等。
实施时,我们的框架还改善了激励机制,将差预测的成本从个人转移到决策者,它可以通过投资提高预测精度以进行响应。完美的预测总能满足我们的概念,这表明建立更精准预测的中心目标与避免歧视的目标一致。
为了方便你自己探索博客文章中的想法,我们的Big Picture团队创造了一个美妙的互动,以视觉化不同的概念和权衡。所以,你可以访问他们的主页了解更多相关资讯。一旦你浏览了演示,请查看论文的完整版,它由得克萨斯大学奥斯汀分校的Eric Price和芝加哥TTI的Nati Srebro共同完成。今年,我们会在巴塞罗召开的神经信息处理系统(NIPS)会议上提交该论文。所以,如果你在附近的话,一定要停下脚步和我们中的一员聊聊天。
我们的论文决不是该重要且复杂话题的终点。它加入了一个正在进行的多学科研究对谈话。我们希望可以鼓舞未来的研究,进一步讨论可实现的方法,以权衡环境歧视和机器学习,并开发有助于从业者应对这些挑战的工具。
-
谷歌
+关注
关注
27文章
6265浏览量
112157 -
机器学习
+关注
关注
67文章
8570浏览量
137391
发布评论请先 登录
意法半导体举办打破偏见STEM主题活动
机器学习中的数据质量双保障:从“验证”到“标记”

解读大型语言模型的偏见
为何你的机器人手臂“知觉”存在偏差?探秘力传感器的奥秘
ETAS如何打破AUTOSAR的固有偏见
强化学习会让自动驾驶模型学习更快吗?


机器学习和深度学习中需避免的 7 个常见错误与局限性
REF2033 3.3V Vref、低漂移、低功耗、双输出Vref和Vref/2基准电压源数据手册
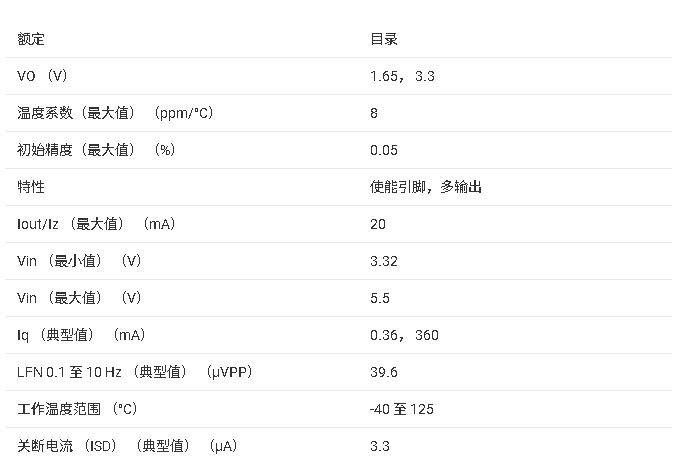
REF2030 3V Vref、低漂移、低功耗、双输出Vref和Vref/2基准电压源数据手册
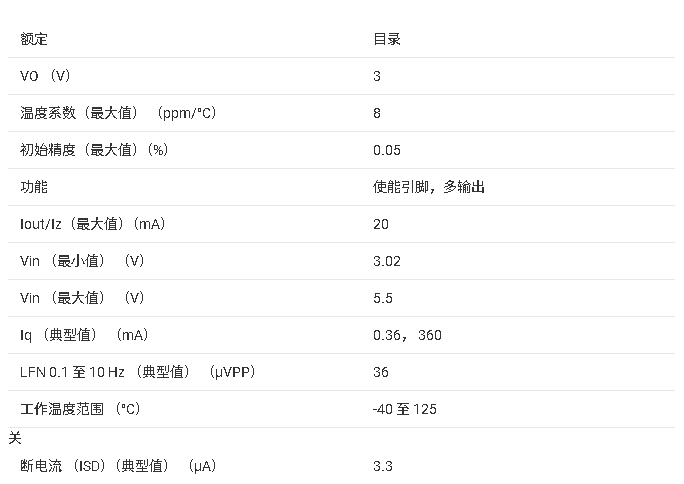
REF1925 2.5V Vref、双输出Vref和Vref/2基准电压源技术手册
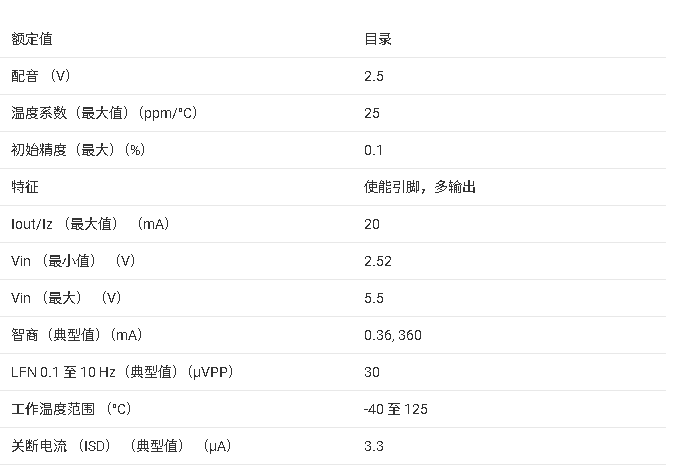
REF19xx系列低漂移、低功耗双输出电压参考源技术文档总结
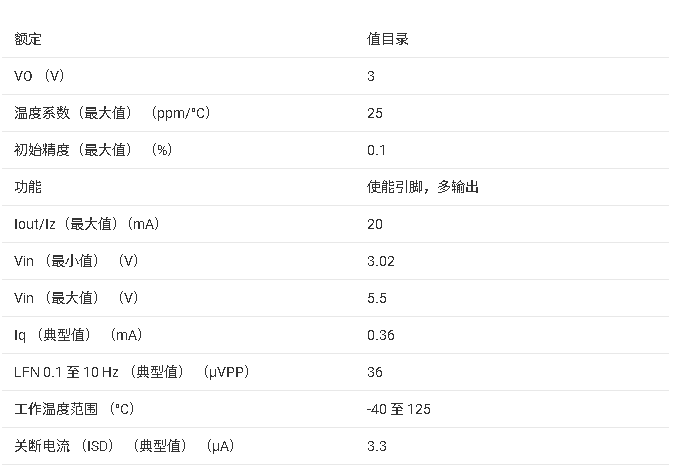
REF1933 3.3V Vref、双输出Vref和Vref/2基准电压源数据手册
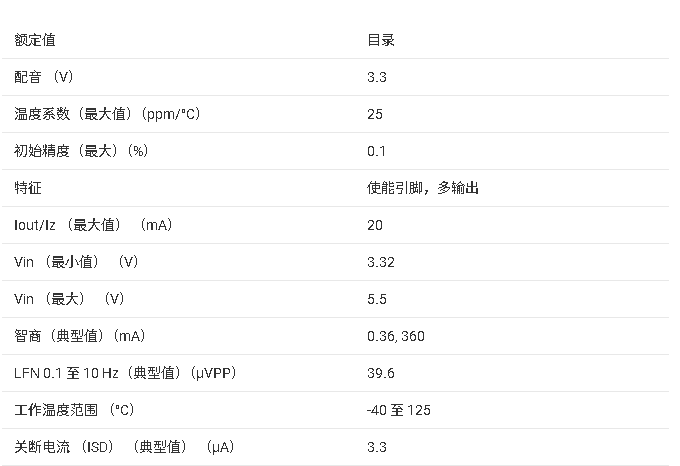
REF20-Q1 低漂移、低功耗双输出电压参考芯片技术文档总结
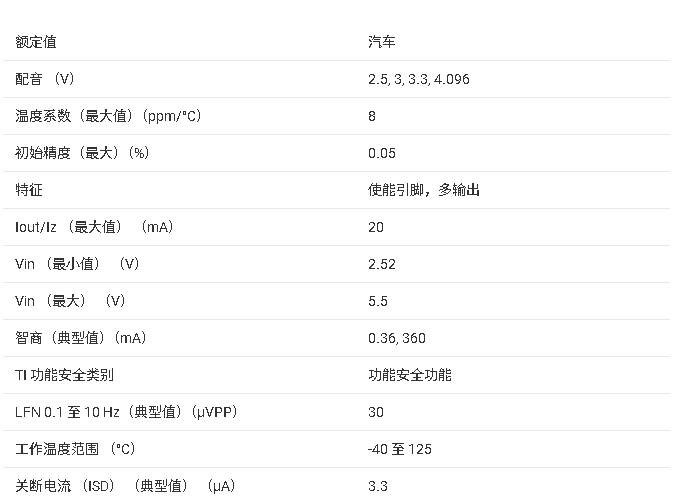
AI输出“偏见”,人类能否信任它的“三观”?




评论