 AI的定位和导航类似于大脑的位置细胞和网格细胞
AI的定位和导航类似于大脑的位置细胞和网格细胞
近日,DeepMind 在 Nature 上发表的一篇论文引起 AI 领域和神经科学领域的极大震撼:AI 展现出与人脑 “网格细胞” 高度一致的空间导航能力。甚至有些学者认为,凭着这篇论文,DeepMind 的作者有可能问鼎诺贝尔奖。本文作者邓侃博士对这篇突破性的论文进行了解读。
Google 麾下的 DeepMind 公司,不仅会下围棋,而且写的论文也顶呱呱。
2018/5/10,今天的微信朋友圈,被DeepMind 一篇论文刷屏了。论文发表在最近一期 Nature 杂志上,题目是Vector-based navigation using grid-like representations in artificial agents [1]。

有些学者认为,凭着这篇论文,DeepMind 的作者有可能问鼎诺贝尔奖[2]。
重要意义:AI的定位和导航类似于大脑的位置细胞和网格细胞
其实这篇论文是DeepMind 人工智能团队,与 University College of London(UCL) 的生物学家,合作的产物。
对空间的定位和导航能力,是生物的本能。早在 1971 年,UCL 的生理学教授 John O'Keefe 在大脑海马体中,发现了位置细胞(Place Cell)。随后 O'Keefe 的学生,Moser 夫妇于 2005 年发现,在大脑内嗅皮层,存在一种更为神奇的神经元,网格细胞(Grid Cell)。在运动过程中,生物的网格细胞,把空间分割为蜂窝那样的六边形,并且把运动轨迹记录在蜂窝状的网格上。
2014 年的诺贝尔生理学/医学奖,颁发给了John O'Keefe 和Moser 夫妇。
人工智能深度学习模型,经常被诟病的一大软肋,是缺乏生理学理论基础。深度学习模型中的隐节点的物理意义,也无法解释。
DeepMind 和 UCL 合著的 Nature 论文,发现深度学习模型中隐节点,与脑内的位置细胞和网格细胞,这两者的激活机制和数值分布,非常相似,几乎呈一一对应的关系。
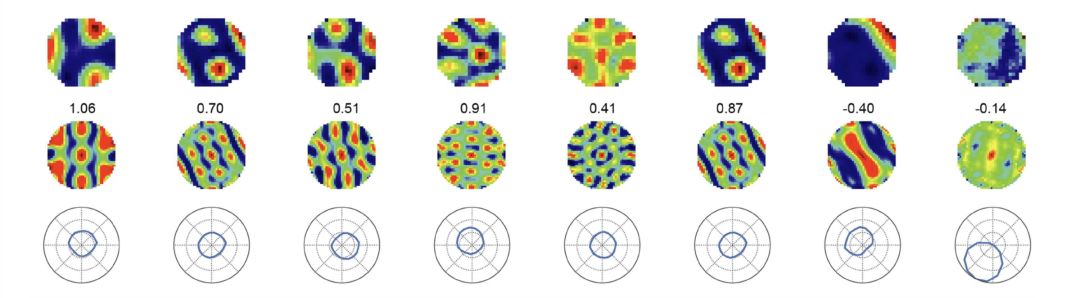
Extended Data Fig 3.d:第一行,深度学习模型的隐节点的激活机制和数值分布。第二行,Moser 夫妇发现的网格细胞的蜂窝状数值分布。深度学习隐节点与网格细胞的数值分布,极为相似。第三行,数值分布所揭示的空间定位及运动方向。
这篇论文,之所以引起学界轰动,原因在于证明了,把深度学习模型用于空间的定位和导航,其隐节点的物理意义,类似于大脑的位置细胞和网格细胞。进一步猜想,深度学习模型的定位和导航的计算过程,很可能与大脑的定位和导航的生理机制,也极为相似。
为什么DeepMind 热衷于玩游戏?
面向空间定位和导航的深度学习模型,有哪些应用场景呢?DeepMind 把这个技术用于玩电子游戏,类似于 “反恐精英”(Counter Strike)那样的走迷宫射杀***的游戏。
DeepMind 下完围棋以后,玩初级电子游戏,现在升级了,改玩高级游戏了。为什么DeepMind 那么热衷于游戏呢?
游戏是仿真系统,一切尽在掌控之中,想要什么数据,就能获取什么数据。所以,每条数据,都很全面,不会有数据丢失。
同时,只要多雇一些玩家,多花一点时间,要多少训练数据,就有多少训练数据。
用游戏来验证深度学习模型,非常方便。这是 DeepMind 热衷于玩游戏的原因。同时,因为能够快速地获取数据,DeepMind 对于深度学习和强化学习研究,领先世界。
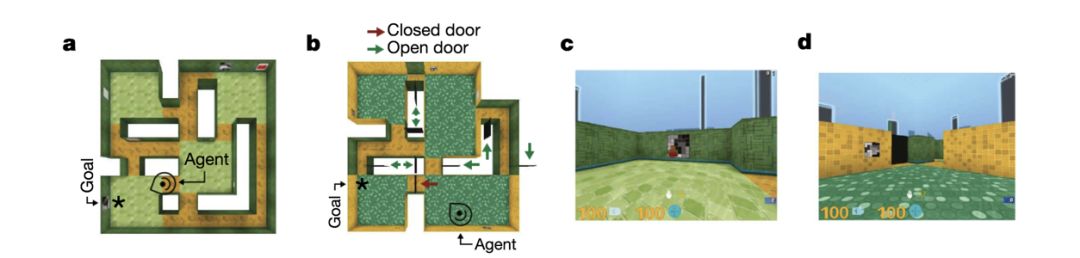
Figure 3. DeepMind 把基于深度学习的空间定位和导航技术,应用于反恐精英(Counter Strike)游戏。
问题是,把适用于游戏的深度学习模型,移用到真实世界,解决实际问题,是否仍然有效?
同是 Google 麾下兄弟,Google Brain 更注重解决实际问题,兄弟俩各有千秋。Google Brain 开发的 Tensorflow成为工程利器,而 DeepMind 的论文,提供新方法,引领研究前沿。
深度学习仿真位置和网格细胞的论文,技术上有什么创新?
短的答案,没有独特的创新。
长的答案,得先讲讲马尔科夫和强化学习。
强化学习(Reinforcement Learning)是机器学习的一个重要分支,它试图解决决策优化的问题。所谓决策优化,是指面对特定状态(State,S),采取什么行动方案(Action,A),才能使收益最大(Reward,R)。很多问题都与决策优化有关,从下棋,到投资,到课程安排,到驾车,到走迷宫等等。
AlphaGo 的核心算法,就是强化学习。AlphaGo不仅稳超胜券地战胜了当今世界所有人类高手,而且甚至不需要学习人类棋手的棋谱,完全靠自己摸索,在短短几天内,发现并超越了一千多年来人类积累的全部围棋战略战术。
最简单的强化学习的数学模型,是马尔科夫决策过程(Markov Decision Process,MDP)。之所以说 MDP 是一个简单的模型,是因为它对问题做了很多限制。
1. 面对的状态 s_{t},数量 t = 1... T,T 是有限的。
2. 采取的行动方案 a_{t},数量t = 1... T,T也是有限的。
3.对应于特定状态 s_{t},当下的收益 r_{t} 是明确的。
4. 在某一个时刻 t,采取了行动方案 a_{t},状态从当前的 s_{t} 转换成下一个状态 s_{t+1}。下一个状态s_{t+1}有多种可能,从当前状态 s_{t}转换到下一个状态中的某一种状态的概率,称为转换概率。但是转换概率,只依赖于当前状态 s_{t},而与先前的状态,s_{t-1}, s_{t-2} ... 无关。
解决马尔科夫决策过程问题的常用的算法,是动态规划(Dynamic Programming)。
对马尔科夫决策过程的各项限制,不断放松,研究相应的算法,是强化学习的目标。
例如对状态 s_{t}放松限制,
1. 假如状态 s_{t} 的数量t = 1... T,T虽然有限,但是数量巨大,或者有数量无限,如何改进算法?
2.假如状态 s_{t} 不能完全确定,只能被部分观察到,剩余部分被遮挡或缺失,如何改进算法?
3. 假如转换概率,不仅依赖于当前状态,而且依赖于先前的运动轨迹,如何改进算法?
4. 假如遇到先前没有遇见过的新状态s_{t},有没有可能在以往遇见过的状态中,找到相似状态,从而估算转换概率,估算收益?
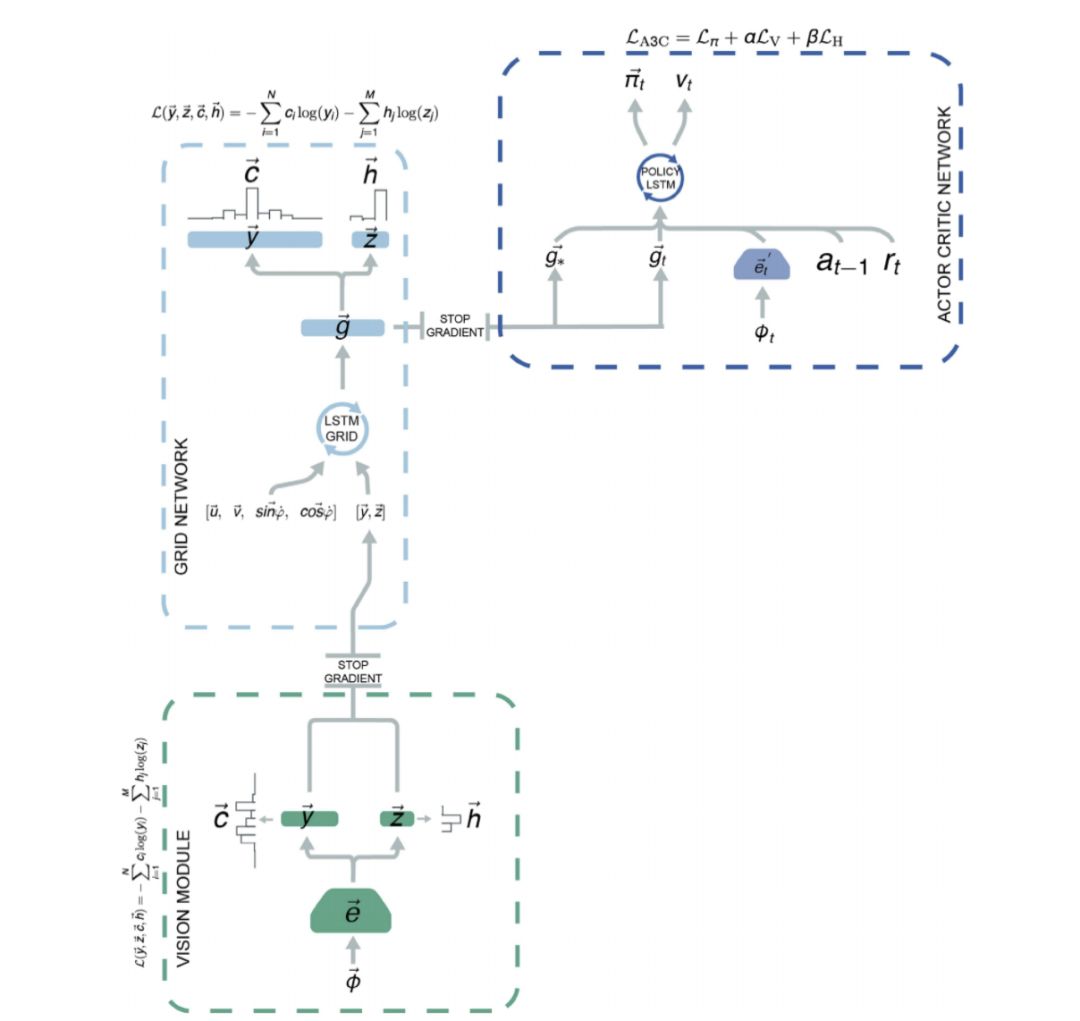
Extended Data Fig 5. 用GridLSTM 来总结以往的运动轨迹,并加上神经网络 g 来判别当前的空间定位和运动方向。然后基于对当前的空间定位和导航的判断,用另一个 LSTM 来估算状态转换概率,从而决定导航策略。
这篇论文用深度学习模型,来仿真位置和网格细胞。具体来说,
1.用 CNN 来处理图像,找到周边环境中的标志物,用于识别当前的空间位置。
2. 把图像处理的结果,与以往的运动轨迹相结合,用GridLSTM 来估算当前的状态。
3. 把GridLSTM 估算出的当前状态,经过一个神经网络 g 的再加工,得到类似于位置细胞和网格细胞的隐节点。
4. 把当前的位置和运动方向,以及目标的位置,作为第二个 LSTM 模型的输入,确定导航决策。
上述所有模块,都是现成技术的集成,并无显著创新。
-
导航
+关注
关注
7文章
537浏览量
42737 -
人工智能
+关注
关注
1800文章
48098浏览量
242237 -
深度学习
+关注
关注
73文章
5527浏览量
121893
原文标题:专家解读DeepMind最新论文:深度学习模型复现大脑网格细胞
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人类首创能生成神经细胞的“迷你大脑”,更精确模拟神经网络!
人工智能可助辨识细胞结构
细胞融合与单克隆抗体
血细胞的产生与美国科学家成功制造出具有造血干细胞功能的细胞
首次创造出能生成神经细胞的3D版“迷你大脑”
“解码”单细胞测序的故事
基于人类乳腺细胞图谱中各细胞亚型之间的位置关系和空间联系

单细胞细胞注释详解之singleR细胞注释
活细胞的“聚光灯”——前沿活细胞成像的案例分享






 工商网监
工商网监
评论