 一个把爬虫下载器和解析器联合在一起的库
一个把爬虫下载器和解析器联合在一起的库
几乎所有玩爬虫的人,一定会用requests库,这个库的作者是大名鼎鼎的Kenneth Reitz 。牛逼的一塌糊涂,最近我浏览它的网站,发现他又出新招,一个把爬虫下载器和解析器联合在一起的库,对爬虫界又是一大福音啊,一起来学习一下吧.
01
Requests-Html
这个库它是requests库的姊妹篇,一般来说我们爬虫,我会直接在下载完网页之后,再去安装一些解析库来解析网页,解析库又有很多种,增加了我们的学习成本。
有没有一种库把这两者融合在一起,并且方便的提供给我们用。但是这个库直接内置了html网页的解析,相当于是自带酒水,非常方便,号称是给人类用的网页解析库。
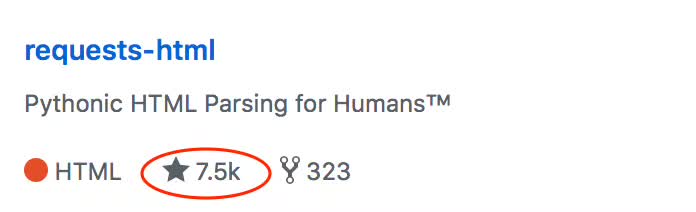
目前这个库已经收获了7500个赞,323fork,相当牛逼!
02
这个库里都有啥
我们只需要用pip 直接install 即可。pip install requests-html,这个库它内置了requests库,pyquery库,bs库,还有一些编码的库。最牛的是,它竟然把随机代理库fake-useragent也集成进来了!
# what packages are required for this module to be executed?

都内置了哪些牛逼的功能:
Full JavaScript support!
CSS Selectors(a.k.a jQuery-style, thanks to PyQuery).
XPath Selectors, for the faint at heart.
Mocked user-agent (like a real web browser).
Automatic following of redirects.
Connection–pooling and cookie persistence.
The Requests experience you know and love, with magical parsing abilities.
03
如何用这个库
1).比如我们爬取一个Python官网网页
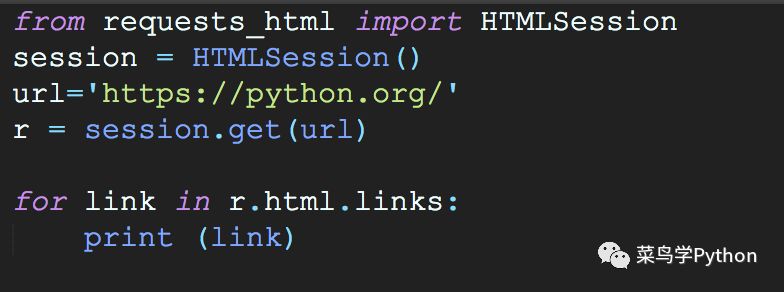
>>/about/quotes//about/success/#software-developmenthttps://mail.python.org/mailman/listinfo/python-dev/downloads/release/python-365//community/logos//community/sigs///jobs.python.orghttp://tornadoweb.orghttps://github.com/python/pythondotorg/issues/about/gettingstarted/...
简单吧,我们也不需要管什么http的请求头,也不需要管什么cookie,更不需要管代理angent.直接初始化一个HTMLSession()类的对象,就可以简简单单的解析网页的内容。一边轻松喝杯茶,一边直接调用r对象里面的方法,比如提取所有网页里面的超链接。
2).看一下HTMLSession对象里面都有哪些好的方法:
print ([e for e in dir(r.html) if not e.startswith('_')])>>['absolute_links', 'add_next_symbol', 'base_url', 'default_encoding', 'element', 'encoding', 'find', 'full_text', 'html', 'links', 'lxml', 'next_symbol', 'page', 'pq', 'raw_html', 'render', 'search', 'search_all','session', 'skip_anchors', 'text', 'url', 'xpath']
里面有很多有用的功能函数,比如find,search,search_all功能,非常方便!上边我们解析了Python官网,接着我们解析官网里面的about :
想要找到about元素里面的文本内容,我们只用find一行代码就可以搞定搞定
about = r.html.find('#about', first=True)print (about.text)>>About Applications Quotes Getting Started Help Python Brochure
#about 是表示网页审查里面id为about (css方式提取),first置为true表示,如果取的元素是一个list,我们只返回第一个元素。
想读取about里面的attr:
print (about.attrs)>>{'id': 'about', 'class': ('tier-1', 'element-1'), 'aria-haspopup': 'true'}
想读取about里面的链接:
about.find('a')>>
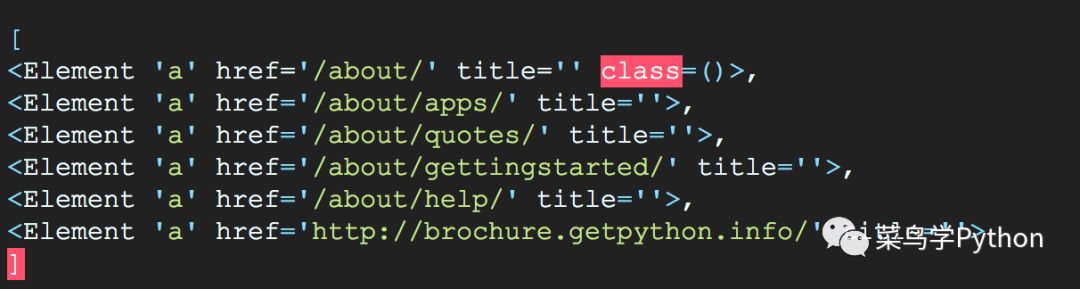
最牛逼的是这About对象已经把各种解析库的对象句柄都完成了初始化,比如大名鼎鼎的pyquery库的解析(css解析器),lxml库的解析。
直接用doc=about.pq,这里的doc其实就是把css解析的内容解析出来,我们可以非常方便的处理.
整个requests_html库相当于一个中间层,把复杂的解析网页的这些繁琐的步骤,再次的封装了,里面还有牛逼的功能,比如支持js页面的动态解析,内置了强大的chromium引擎和异步的解析session(AsyncHTMLSession),这个里面用的是Python非常牛逼的Asyncio库。
总之有了这个requests_html,妈妈再也不用担心我学不会爬虫了。
-
函数
+关注
关注
3文章
4327浏览量
62567 -
python
+关注
关注
56文章
4792浏览量
84623
原文标题:爬虫大神,又出新招
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论