 《机器学习训练秘籍》:书中选出了7条非常有用的建议
《机器学习训练秘籍》:书中选出了7条非常有用的建议
《机器学习训练秘籍》(Machine Learning Yearning)是吴恩达的新作,主要讲的是如何应用机器学习算法以及如何构建机器学习项目。本文从这本书中选出了 7 条非常有用的建议。
近年来,人工智能、机器学习和深度学习迅猛发展,给许多行业带来了变革。吴恩达是业内的领军人物之一,他是在线课程项目 Coursera 的联合创始人,前百度 AI Group 领导人,前 Google Brain 项目负责人。目前他正在编写《机器学习训练秘籍》(http://www.mlyearning.org/)这本书,教读者如何组织机器学习项目。
吴恩达在书中写道:
这本书主要是教你如何应用机器学习算法,而不是教你机器学习算法本身。一些AI技术课程会教你算法,而这本书旨在教你如何使用算法这个利器。如果你想成为 AI领域的技术领袖,并希望学习如何为你的团队设定方向,这本书会给你帮助。
我们在阅读这本书的原稿后从中选出了 7 条有趣且实用的建议.
▌1. 选择正确的评估指标
在评估某个算法时,不应该只使用一个公式或指标,而应使用多个评估指标。其中一种方法就是使用“optimizing”和“satisfying”作为指标。
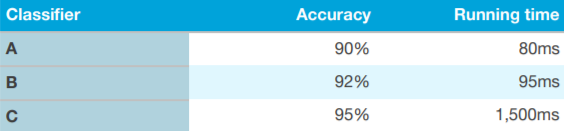
以上图为例,首先定义一个“acceptable”(可接受)的运行时间(例如小于 100 毫秒),作为“satisfying”指标。只要运行时间低于这个指标,你的分类器就「很好」。“准确度”在这里作为“optimizing”指标。这是一种非常有效且容易的算法评估方法。
▌2. 快速选择开发/测试集——如果有必要不要害怕更换
当开始一个新项目时,吴恩达在书中解释道他会很快选择开发集/测试集,因为这样可以给团队制定一个明确的目标。开始时他会先制定第一周的目标,提出一个不太完美的方案并迅速行动起来,比花过多时间思考更好。
如果你突然发现初始的开发/测试集不正确时,不要害怕更改它们。以下是书中给出的开发/训练集不正确的三个可能原因:
要使用的实际数据分布和开发/测试集不同
开发/测试集过度拟合
评估指标衡量的并不是项目所需要优化的东西
请谨记,更改开发/测试集不是什么大问题。放心更改,让你的团队知道你们的新方向。
▌3. 机器学习是一个迭代过程:不要指望第一次就成功
吴恩达写道他开发机器学习软件的过程分三步:
从一个想法开始
用代码实现这个想法
通过实验判断这个想法是否成功
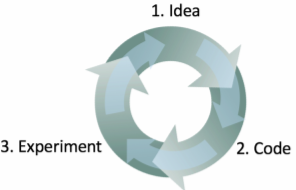
这是一个不断迭代的过程。循环得越快,进展也就越快。这就是为什么提前确定开发/测试集很重要,因为这样做可以在这个迭代过程中省下宝贵的时间。每尝试一个新想法时,在开发/测试集上衡量这个想法的表现,这样你就可以快速判断你是否在朝着正确的方向前进。
▌4. 快速构建第一个系统,然后迭代
在第三条建议中,我们提到构建机器学习算法是一个迭代过程。吴恩达专门用一个章节解释了快速构建第一个系统然后迭代的好处:「不要试图一开始就设计和构建完美的系统。相反,应该快速构建和训练出一个基本系统——也许在短短的几天内。即使这个基本系统与您你构建的“最佳”系统相差甚远,研究基本系统的表现仍非常有参考价值:你很快就会找到线索,以此确定哪个方向最有希望获得成功。」
▌5. 并行评估多个想法
当你的团队针对如何改进某一算法提出了很多想法,你可以高效地并行评估这些想法。举例来说,构建一个能识别猫照片的算法,吴恩达称他通常会创建一个电子表格,浏览大约 100 张分类错误的开发/测试集图像并在表格上记录。

在表格上记录:对每张图像的分析,造成算法分类错误的原因,以及可能对未来反思有帮助的评论。填完后,你会得出哪种想法可以避免更多错误,然后再去实现它。
▌6. 思考清理贴错标签的开发/测试集是否值得
在错误分析期间,你可能会注意到开发/测试集中的一些样本被错误标注(mislabeled)。也就是说,在用算法处理前之前,图片已经被人类标注员贴上了错误的标签。如果你怀疑有一小部分的图片被错误标注是由于这个原因,那么可以在电子表格中添加再一个类别进行记录:

在完成后,你可以思考修正这些错误是否值得。吴恩达给出了两种可能的场景,让读者判断修正错误是否值得:
示例1:
开发集的整体准确率……90%(整体错误率为 10%)
贴错标签样本导致的错误……0.6%(占开发集错误的 6%)
其他原因导致的错误……9.4%(占开发集错误的 94%)
在这个例子中,相较于你可能改进的 9.4% 的错误,由于错误标注导致的 0.6% 的不准确率就可能没那么重要。手动修正开发集中错误标注的图像并没有什么坏处,但这样做并不是关键:不知道系统的整体错误是 10% 还是 9.4% 可能没什么大不了。
示例 2:
开发集整体准确率……98.0%(整体错误率为 2.0%)
贴错标签样本导致的错误……0.6%(占开发集错误的 30%)
其他原因导致的错误……1.4%(占开发集错误的 70%)
30% 的错误是由于错误标注的开发集图像造成的,这会让准确率的估计值有很大的误差。这种情况下,改进开发集的标注质量很值得。处理错误标注的样本将帮助你算出分类器的错误是接近 1.4% 还是 2%——这是一个相对明显的差异。
▌7. 考虑将开发集分为多个子集
如果你的开发集很大,其中 20% 的样本被算法错误分类,那么你可以将这个开发集分为两个独立的子集:
比方说,你有一个包含 5000 个样本的大开发集,其中 1000 个样本被错误分类。假设我们要手动检查约 100 个错误样本(错误样本的10%),进行错误分析。那么你应该随机选出 10% 的开发集,然后将其放入我们称之为 Eyeball 的开发集(Eyeball dev set)中,以提醒自己你需要观察这些数据。Eyeball 开发集有 500 个样本,我们预计算法错误分类的样本约有 100 个。
开发集的第二个子集叫做 Blackbox 开发集(Blackbox dev set),它包含剩余的 4500 个样本。你可以用 Blackbox 开发集测定图像分类的错误率,以此自动评估分类器。你也可以使用它来选择算法或调整超参数。我们将这个子集称为 “Blackbox”,是因为我们只使用数据集的子集来取得对分类器的“Blackbox”(黑盒)评估。
-
人工智能
+关注
关注
1791文章
46877浏览量
237614 -
机器学习
+关注
关注
66文章
8381浏览量
132425
原文标题:吴恩达《机器学习训练秘籍》:7 条关于项目实践的实用建议
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「时间序列与机器学习」阅读体验】+ 简单建议
对新手非常有用的电子器件基础资料
机器学习训练秘籍——吴恩达
展示Python机器学习开源项目以及在分析过程中发现的非常有趣的见解和趋势

机器学习-8. 支持向量机(SVMs)概述和计算
17个非常有用的 Python 技巧

Vim中默认未启用但实际非常有用的选项
《机器学习训练秘籍》中的六个概念
机器学习/人工智能领域一些非常有创意的突破
机器学习对分析地理空间图像非常有帮助
17个非常有用的Python技巧
一个简单但非常有用的小前置放大器电路
没有什么是完美的,但FPGA可能非常有用





 工商网监
工商网监
评论