 TCN应该成为我们未来项目的优先选项
TCN应该成为我们未来项目的优先选项
我们一开始认为,时序问题(如语言、语音等等)天生就是 RNN 的地盘。然而现在这一观点要成为过去式了。时间卷积网络(Temporal Convolutional Nets, TCNs)作为 CNN 家族中的一员健将,拥有许多新特性,如今已经在诸多主要应用领域中击败了 RNN。看起来 RNN 可能要成为历史了。
也就是从 2014、15 年起,我们基于深度神经网络的应用就已经在文本和语音识别领域达到 95% 的准确率,可以用来开发新一代的聊天机器人、个人助理和即时翻译系统等。
卷积神经网络(Convolutional Neural Nets, CNNs)是图像和视频识别领域公认的主力军,而循环神经网络(Recurrent Neural Nets, RNNs)在自然语言处理领域的地位与其是相似的。
但二者的一个主要不同是,CNN 可以识别静态图像(或以帧分割的视频)中的特征,而 RNN 在文本和语音方面表现出色,因为这类问题属于序列或时间依赖问题。也就是说,待预测的后一个字符或单词依赖于前面的(从左到右)字符或单词,因此引入时间的概念,进而考虑到序列。
实际上,RNN 在所有的序列问题上都有良好表现,包括语音 / 文本识别、机器翻译、手写体识别、序列数据分析(预测),甚至不同配置下的自动编码生成等等。
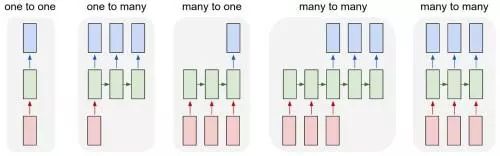
在很短的一段时期里,RNN 的改进版本大行其道,其中包括 LSTM(long short term memory,长短期记忆网络)和 GRU(gated recurring units,门循环单元)。这二者都改进了 RNN 的记忆范围,令数据可以将距离其很远的文本信息利用起来。
解决“才怪”问题
当 RNN 从左到右按顺序读取字符时,上下文就成了一个重要问题。比如,对一条评论进行情感分析时,刚开始的几句话可能是正面的(例如,食物好,气氛好)但以负面评论结束(如服务差,价格高),最后整条评论实际上是负面的。这其实在逻辑上等同于“才怪”的玩笑:“这个领带看着不错……才怪!”
这个问题的解决方案是使用两个 LSTM 编码器,同时从两个方向读取文本(即双向编码器)。这相当于在现在掌握了(文本的)未来信息。这很大程度上解决了问题。精度确实提高了。
Facebook 和 Google 遭遇的一个问题
早些年,当 Facebook 和 Google 发布各自的自动语言翻译系统时,他们意识到了一个问题——翻译耗时太长了。
这实际上是 RNN 在内部设计上存在的一个问题。由于网络一次只读取、解析输入文本中的一个单词(或字符),深度神经网络必须等前一个单词处理完,才能进行下一个单词的处理。
这意味着 RNN 不能像 CNN 那样进行大规模并行处理(massive parallel processing,MPP),特别是在 RNN/LSTM 对文本进行双向处理时。
这也意味着 RNN 极度地计算密集,因为在整个任务运行完成之前,必须保存所有的中间结果。
2017 年初,Google 和 Facebook 针对该问题提出了相似的解决方案——在机器翻译系统中使用 CNN,以便将大规模并行处理的优势发挥出来。在 CNN 中,计算不依赖于之前时间的信息,因此每个计算都是独立的,可以并行起来。
Google 的解决方案叫做 ByteNet,而 Facebook 的称为 FairSeq(这是用 Facebook 内部的人工智能研究团队 FAIR 来命名的)。FairSeq 的代码已发布至 GitHub。
Facebook 称他们的 FairSeq 网络的运行速度比基本的 RNN 快 9 倍。
基本工作原理
CNN 在处理图像时,将图像看作一个二维的“块”(高度和宽度);迁移到文本处理上,就可以将文本看作一个一维对象(高度 1 个单位,长度 n 个单位)。
但 RNN 不能直接预定义对象长度,而 CNN 需要长度信息。因此,要使用 CNN,我们必须不断增加层数,直到整个感受野都被覆盖为止。这种做法会让 CNN 非常深,但是得益于大规模并行处理的优势,无论网络多深,都可以进行并行处理,节省大量时间。
特殊结构:选通 + 跳跃 = 注意力
当然,具体的解决方案不会像上面所说的那样简单。Google 和 Facebook 还向网络中添加了一个特殊结构:“注意力(Attention)”函数。
最初的注意力函数是去年由 Google Brain 和多伦多大学的研究者们提出的,命名为变换器(Transformer)。
原论文链接:
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf。
当时,Facebook 和 Google 使用的函数几乎一模一样,因此该函数备受关注,被称为“注意力”函数。该函数有两个独特的特征。
第一个特征被 Facebook 称为“多跳跃”。和传统 RNN 方法的每个句子只“看”一次不同,多跳跃让系统可以“瞥”一个句子“好多眼”。这种行为和人工翻译更相似。
每“一瞥”可能会关注某个名词或动词,而这些词并不一定是一个序列,因此在每一次迭代中可以更深入地理解其含义。每“瞥”之间可能是独立的,也可能依赖于前面的“瞥”,然后去关注相关的形容词、副词或助动词等。
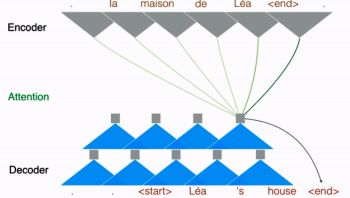
上图是 Facebook 给出的一个法英翻译的例子,展示了第一次迭代的过程。该次迭代编码了每一个法语单词,然后用“多跳跃”的方法选择最合适的英文翻译。
第二个特征是选通(即门控制),用来控制各隐藏层之间的信息流。在上下文理解过程中,门通过对 CNN 的尺度控制,来判断哪些信息能更好地预测下一个单词。
不只是机器翻译——时间卷积网络(TCN)
至 2017 年中旬,Facebook 和 Google 已经通过使用 CNN 和注意力函数,完全解决了机器翻译的时间效率问题。而更重要的一个问题是,这种技术大有用武之地,不能将其埋没在加速机器翻译的小小任务中。我们能否将其推广到所有适用于 RNN 的问题?答案是,当然可以。
2017 年,相关的研究发表了很多;其中有些几乎是和 Facebook、Google 同时发表的。其中一个叙述比较全面的论文是 Shaojie Bai、J. Zico Kolter 和 Vladlen Koltun 发表的“An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling”。
原文链接:https://arxiv.org/pdf/1803.01271.pdf。
有些同仁将这种新架构命名为时间卷积网络。当然随着工业上的应用,这个名称有可能会被更改。
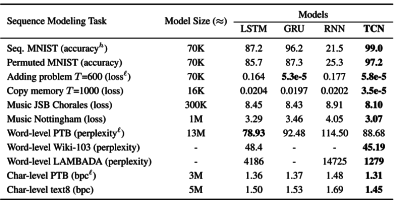
上述论文所做的工作是在 11 个不同的、非语言翻译类的工业标准 RNN 问题上,将 TCN 与 RNN、LSTM、GRU 进行了直接比较。
研究的结论是:TCN 在其中的 9 个问题中,不仅速度更快,且精度更高;在 1 个问题中与 GRU 打了平手(下表中的粗体文字代表精度最高项。图片截取自原论文)。
TCN 优缺点
Shaojie Bai、J. Zico Kolter 和 Vladlen Koltun 还给出了下面这一实用的列表,列举了 TCN 的优缺点。
速度很重要。更快的网络能使反馈环更短。由于在 TCN 中可以进行大规模并行处理,网络训练和验证的时间都会变短。
TCN 为改变感受野大小提供了更多灵活性,主要是通过堆叠更多的卷积层、使用更大的膨胀系数及增大滤波器大小。这些操作可以更好地控制模型的记忆长短。
TCN 的反向传播路径和序列的时间方向不同。这避免了 RNN 中经常出现的梯度爆炸或梯度消失问题。
训练时需要的内存更少,尤其是对于长输入序列。
然而,作者指出,TCN 在迁移学习方面可能没有 CNN 的适应能力那么强。这是因为在不同的领域,模型预测所需要的历史信息量可能是不同的。因此,在将一个模型从一个对记忆信息需求量少的问题迁移到一个需要更长记忆的问题上时,TCN 可能会表现得很差,因为其感受野不够大。
进一步考虑TCN 已经被应用在很多重要领域,也获得了极大成功,甚至几乎可以解决一切序列问题。因此,我们需要重新考虑我们之前的看法。序列问题不再是 RNN 的专属领域,而 TCN 应该成为我们未来项目的优先选项。
-
神经网络
+关注
关注
42文章
4774浏览量
100898 -
cnn
+关注
关注
3文章
353浏览量
22250
原文标题:时间卷积网络(TCN)在 NLP 多领域发光,RNN 或将没落
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电子元器件筛选方案的设计原则及筛选项目
基于Arduino的灌溉项目的问题解析
APP会成为区块链的未来吗?
如何指定优先级
有历史才有未来,DigiPCBA的项目历史
TCN75A/TCN75中文资料,pdf (数字温度传感器)
探究TCN列车网络的未来发展
关于MPLAB Harmony中项目恢复和备份选项的具体介绍
存储优先架构存在优势 或是AI芯片的未来
区块链项目的治理问题探讨
为什么使用CubeMx配置NVIC时不见子优先级选项





 工商网监
工商网监
评论