 实现故障自愈要攻克的3个问题以及开箱即用的方案
实现故障自愈要攻克的3个问题以及开箱即用的方案

以产品设计理念剖析企业建设故障自动化处理方案的思路
人工处理告警,一直是运维心中的痛。大年初一拜年、结婚、和老婆孩子外出过周末等美好时光,作为运维的你,好像一直心系IT系统,保持与笔记本的安全距离。
为什么这么多年过去了,还是这么苦逼,不是说运维行业转 AIOps了,我竟然还在手工处理告警,我该怎么办?
今天就和大家聊聊实现故障自愈要攻克的3个问题,以及献上开箱即用的方案。
1. 故障自愈的基本流程
自动化的要点是什么?把人的经验抽象、固化为程序处理,工业(第3次工业革命)或互联网都是如此。
举个例子,磁盘出现告警,运维首先想到的是登陆服务器清理磁盘。
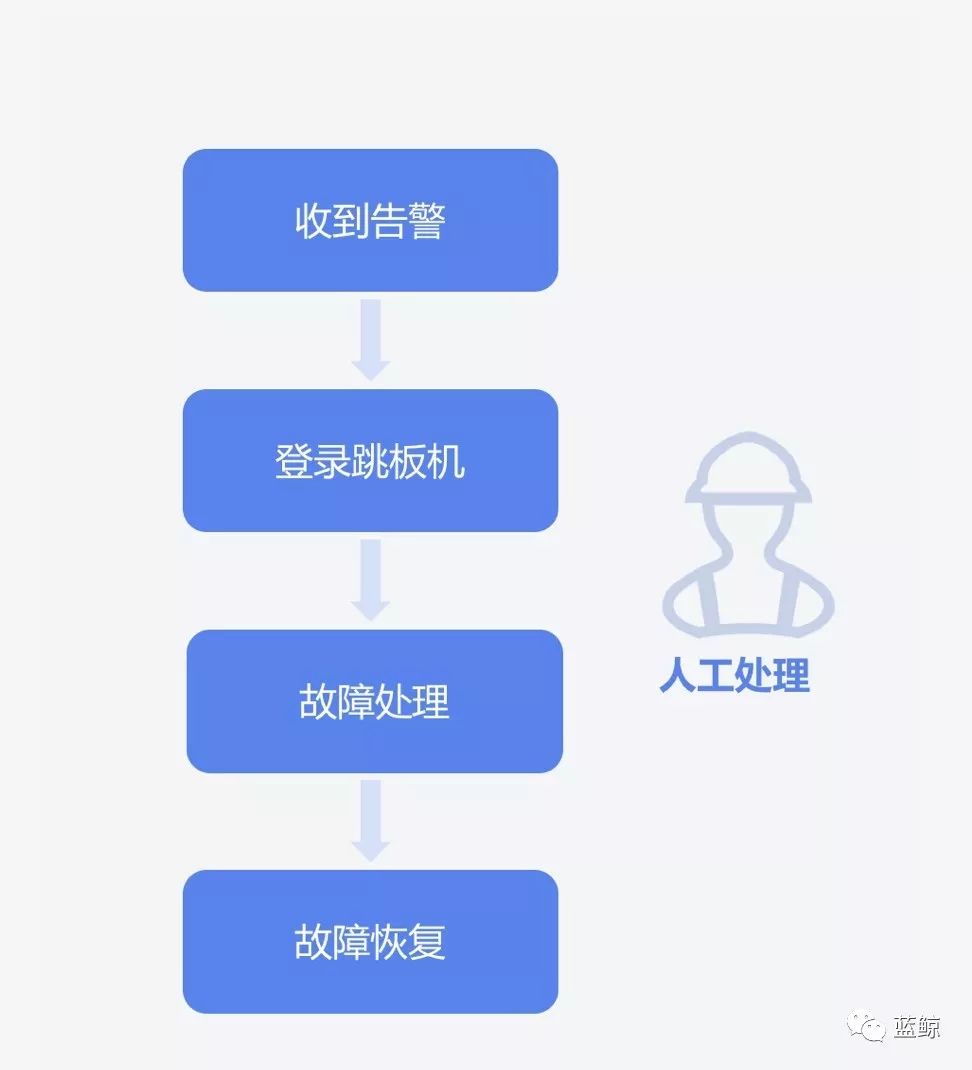
(人工处理告警的流程)
接下来,我们拆解背后的逻辑。
1.1 抽象告警处理流程
1)拉取磁盘告警
2) 编写磁盘清理的脚本或作业任务
3) 设计模块:把拉取到的磁盘告警,与调用脚本的模块串起来

(故障自愈流程 简化版V1)
1.2 通过CMDB做资源清洗
不同模块的磁盘清理方案不一样,如何解决呢?
这时需要引入CMDB(设备、人、业务的映射关系),通过CMDB把IP清洗为模块,这样就解决了接入层 和 逻辑层、存储层的告警使用对应的磁盘清理方案。
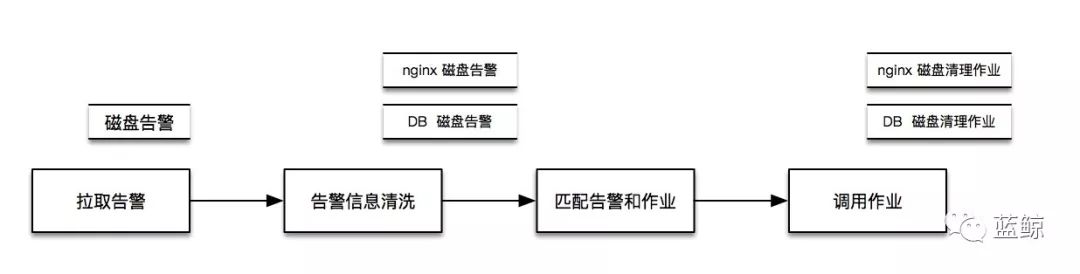
(故障自愈流程 简化版V2)
1.3 对接企业内部网关
故障自愈可能会处理失败,这时需要通知用户。故障自愈的处理方式除了调用作业外,还可能需要调用企业内部的网关,比如服务器重启、申请服务器等。
使用PaaS层的ESB是一种解决思路,通过ESB封装企业内部网关,解决权限校验、频率控制、访问统计、路由分发以及自助接入等功能,不要直接调用裸接口了。
(故障自愈的通知方案)
经过这一轮的探索,故障自愈的架构就是下面这个样子。
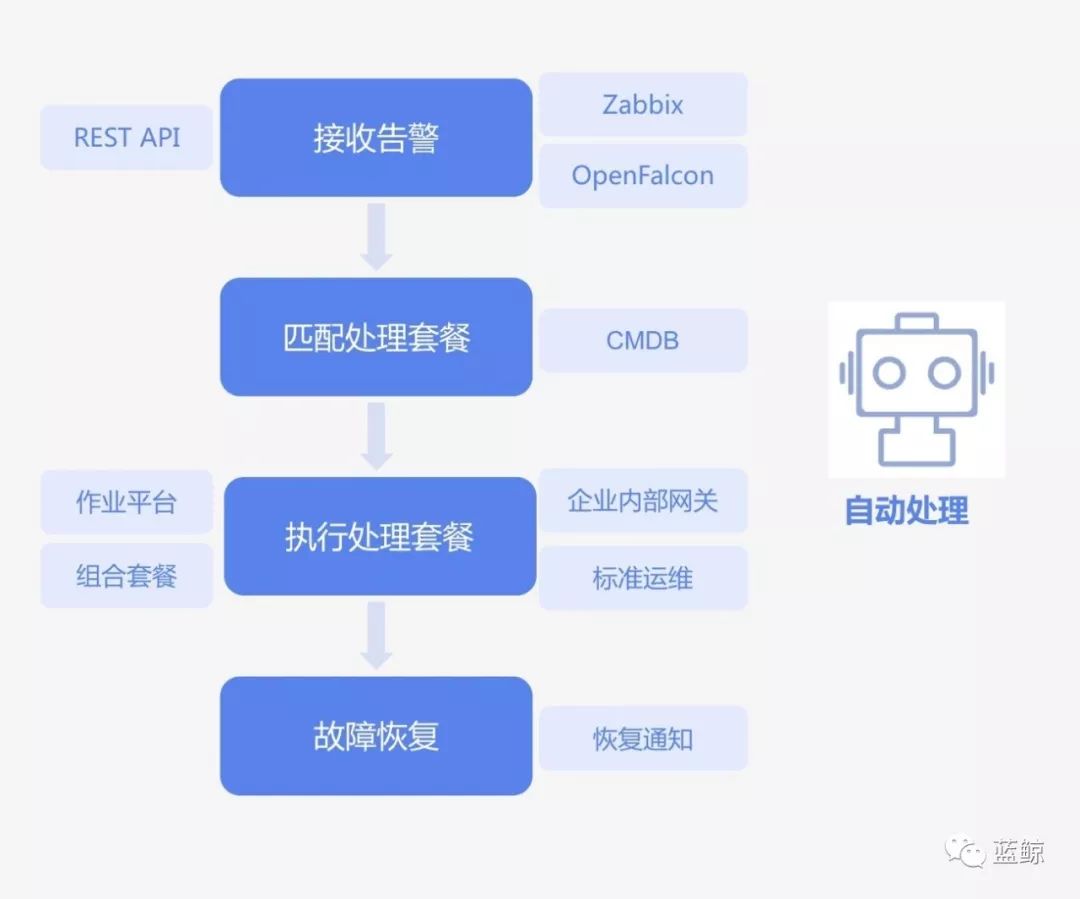
(故障自愈的流程)
1.4 对接企业内部监控产品
等等,好像还没说如何对接企业内部的监控产品,以Zabbix、Open-Falcon为例。
1.4.1 对接Zabbix
《当Zabbix遇见故障自愈》介绍了拉取Zabbix告警的方案,通过 ActionScript 调用脚本,把 Zabbix 告警推送至自愈的告警拉取模块。
推送(或叫回调)可以保证告警拉取的实时性。
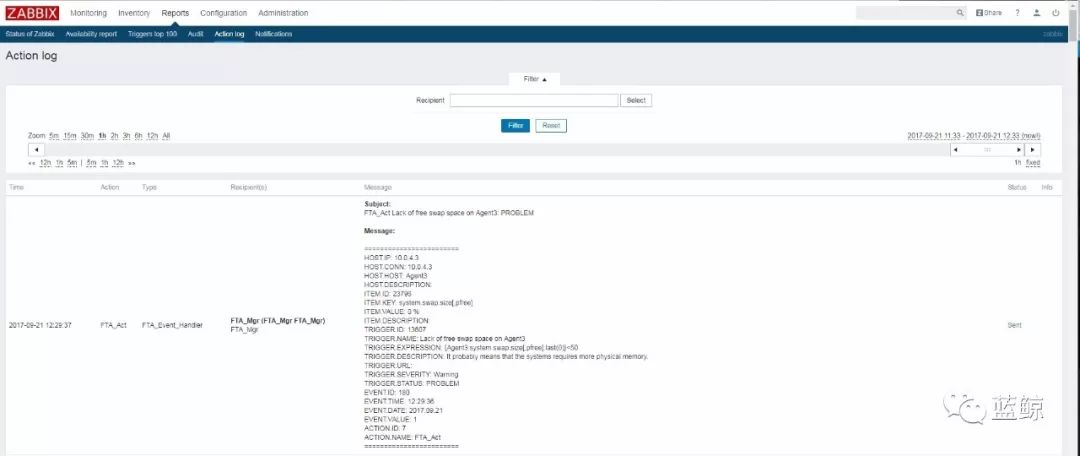
(Zabbix推送告警示例)
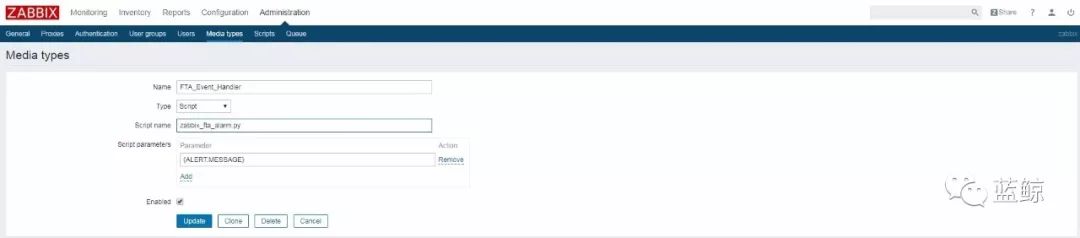
(Zabbix调用推送告警的脚本)
对接Zabbix 的落地案例可以参考陈亮撰写的那些年我们想做的无人值守。
除Zabbix外,Open-Falcon在国内的社区热度也不错,所以也介绍拉取其告警的方案。
1.4.2 对接Open-falcon
方案类似Zabbix,不过Open-falcon 直接提供了callback功能,简化了流程。
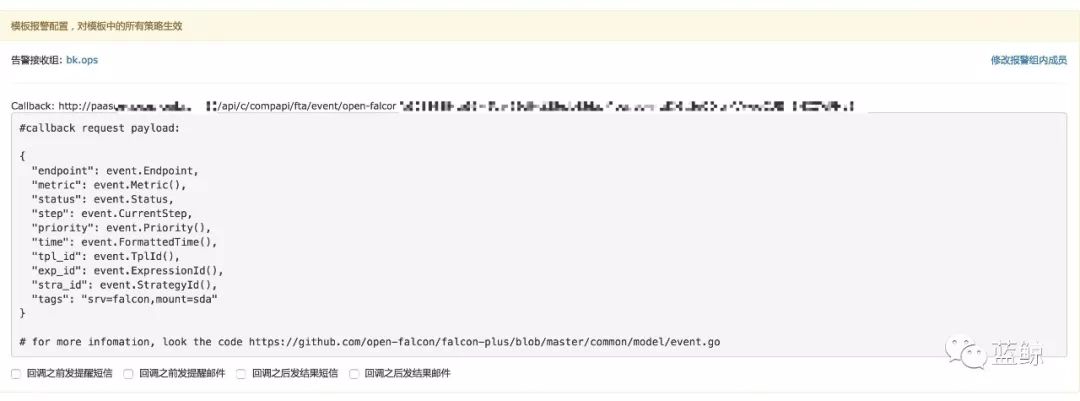
(Open-Falcon配置Callback地址)
收到了Open-Falcon 推送的告警后,解析对应的字段即可。
如果企业内部的CMDB以IP来标识主机,需要再做一层转换,因为Open-Falcon 的资源标识endpoint默认是主机名,那么就需要使用CMDB的自动发现功能自动上报主机名,同时提供把主机名清洗为IP的功能。
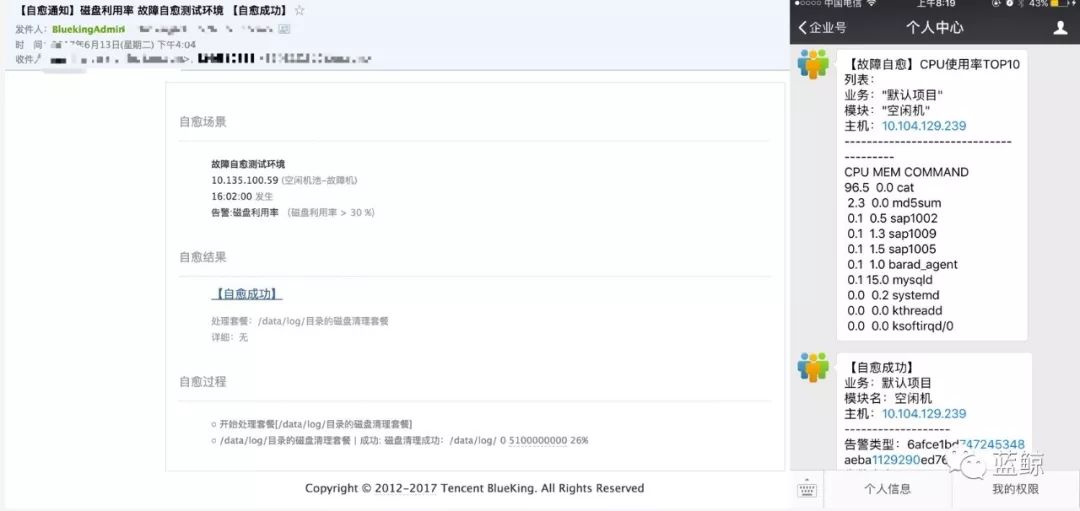
下面是Nginx模块磁盘告警的自愈示例,匹配Nginx模块的磁盘清理套餐,清理Nginx模块的日志文件,整个过程不到30秒。

(磁盘告警的自愈示例)
2. 故障自愈的两面性
故障自动处理就像一把刀,有其两面性。
因为要确保告警的真实性,一旦把假告警也自动处理了,就很悲催了…
举个例子。网络波动,批量出现PING告警。实际上服务器运行正常,这时你把服务器都重启了,那就GG了。
如何解决呢?分析事物的规律。
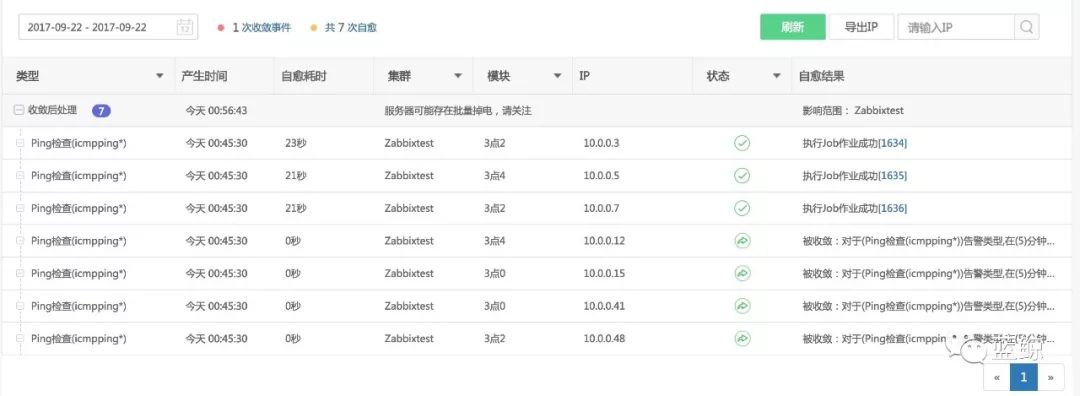
批量出现告警,那可以在告警拉取模块后面,增加一个收敛模块。
比如,在X时间内出现Y个告警,打电话给运维审批。
X时间内同一主机出现使用相同套餐的告警,则收敛时间窗口中后面的告警则跳过,比如同时收到进程告警 和 端口告警,就不用拉2次进程了。
还有就是,原有监控系统没有收敛能力,那么可以借用这个功能来做告警汇总,因为收敛逻辑一样,只是收敛的处理方式有差异。
3. 复杂告警的处理方案 - 组合套餐
上面提到的技术方案是用来处理逻辑简单的告警,那么故障替换这种复杂的场景如何解决呢?
举个例子,A模块是重要模块,出现PING不可达告警,首先要校验A模块是否真的故障,如果真的故障,接下来是从资源池中获取备机 … 故障替换等等,期间每个环节都有可能出错,那就要考虑异常分支的场景。
树结构可以解决该问题,二叉树足以满足大部分场景(成功、失败两种分支)。

( 组合套餐的示例)
上面这张图,是一个自愈处理方案,可以称之为组合套餐。
这里同时引入了原子的概念,通过组装原子来满足各种需求场景, 和资源编排说的是同一个理儿。
注:如果你想使用三叉树,其实可以把组合套餐也作为一个原子套餐(节点)。
4. 故障自愈的技术架构
经过前面对故障自愈的基本流程、故障自愈的两面性、复杂的故障处理方案的层层梳理,我们有了一张故障自愈的技术架构图。
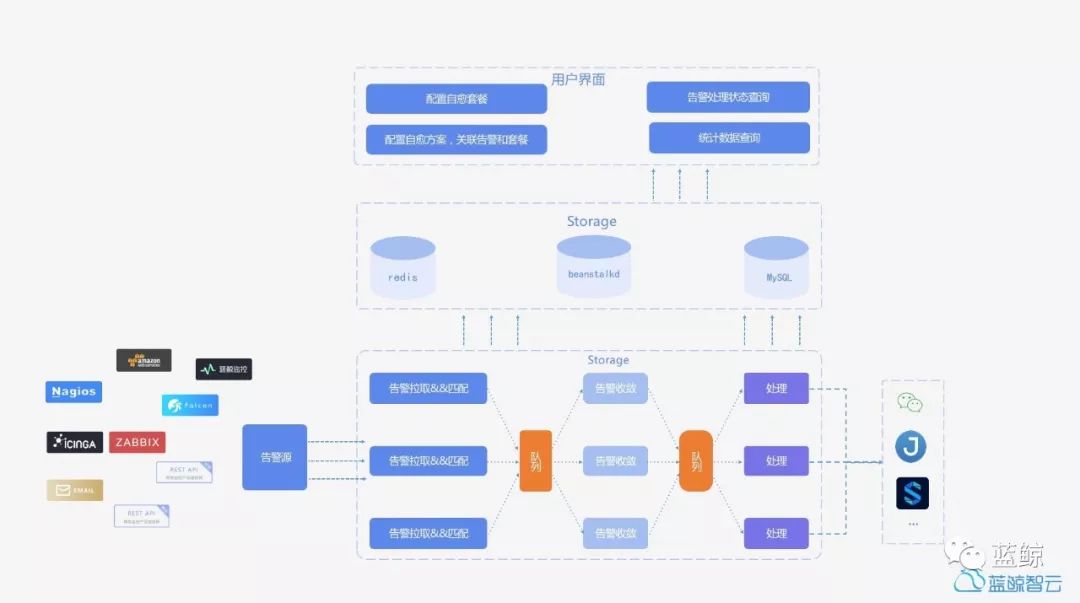
相信这次以经行业验证的故障自愈做技术剖析,能对大家建设企业内部的故障自动处理方案提供参考思路。
5. 收尾
当 AIOps大行其道的时候,我们需要克制,优先解决主要矛盾,而不是构建高大上的空中楼阁。
如同产品路线图,优先解决可用性,接下来是体验,最后才是可扩展性和生态,依次落地。
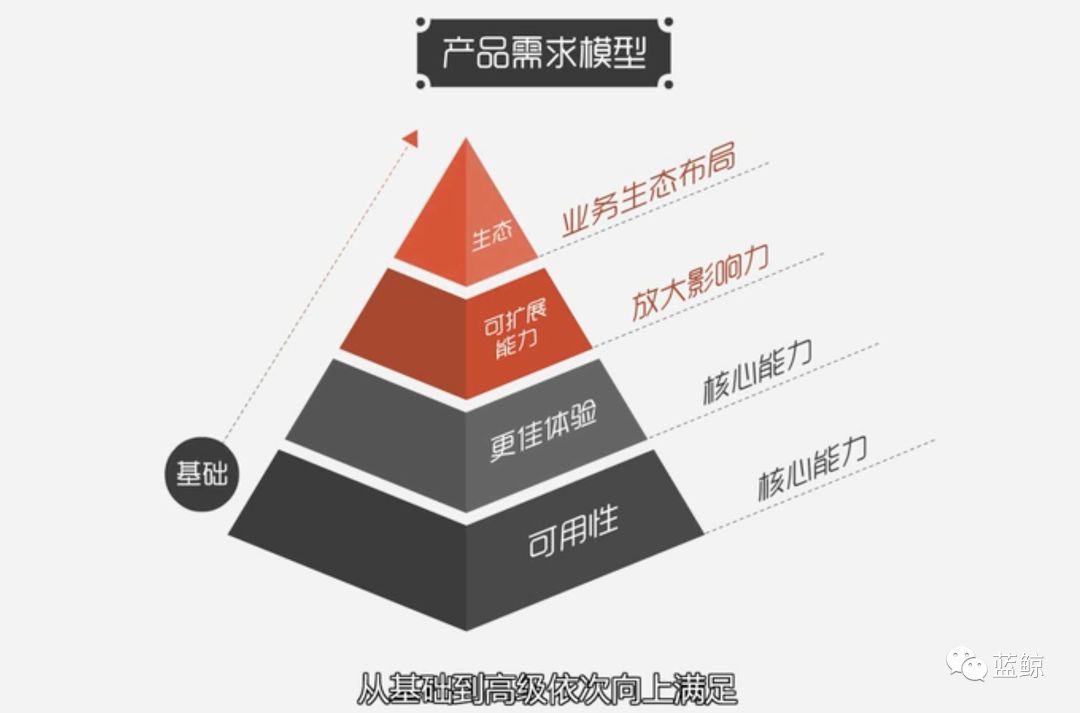
最后,希望广大的运维兄弟姐妹能尽早脱离原始运维的苦海,抓住行业发展趋势,掌握核心技术,在变革中实现自身价值!
-
故障处理
+关注
关注
2文章
22浏览量
9746 -
CMDB
+关注
关注
0文章
8浏览量
6886
原文标题:故障自愈:解决运维的主要矛盾才能AIOps
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
快速开箱即用体验 AMD / Xilinx Kria™ KD240驱动器入门套件
开箱即用!冠显Type-C评估套件介绍
自愈式电容器的使用误区总结
计算机网络E1链路接口自愈保护解决方案
当智能配电网发生故障时是如何进行自愈控制的?
ABC一体机3.0:AI开箱即用即开发
阿里如何做到百万量级硬件故障自愈?

开箱即用!教你如何正确使用华为云CodeArts IDE Online!

配网调度自动化自愈系统的设计与实现
[技术干货] AI 助手全套开源解决方案,自带运营管理后台,开箱即用
![[技术干货] AI 助手全套开源解决<b class='flag-5'>方案</b>,自带运营管理后台,<b class='flag-5'>开箱</b><b class='flag-5'>即用</b>](https://file1.elecfans.com//web2/M00/C7/0F/wKgZomYQF2iAKeWuAAEJ7QHGrZY892.png)
自愈式电容器型号含义
自愈式电容器容易坏是不是容量小的问题

复合机器人“开箱即用”,交付调试周期大幅缩短至分钟级
国民技术发布一款开箱即用的GMSSL硬件Engine




评论