 英特尔推出黑暗中快速成像的系统,效果不错
英特尔推出黑暗中快速成像的系统,效果不错
想在黑暗中看清周围,不可避免地要用到夜视仪。那么如果是想在黑暗中拍照,又没有闪光灯,如何才能排到清晰的照片?在CVPR 2018上,英特尔实验室的Vladlen Koltun和陈启峰带领的团队提出了一种在黑暗中快速成像的系统,效果非常赞。
在暗光下的图像易受到低信噪比和低亮度的影响。短曝光的照片会出现很多早点,而长曝光会让照片变得模糊、不真实。目前已经有很多去噪、去模糊、图像增强的技术,但是在极端条件下,他们的作用就很有限了。为了发展基于学习的低光度图像处理,我们引入了一个数据集,内含有原始短曝光低亮度图片,同时还有对应的长时间曝光的图像。利用该数据集。我们创建了一个机遇端到端训练的全卷积网络,用于处理低亮度图像。网络直接使用原始传感器数据,并替代了大量传统图像处理的流程。最终我们发现新数据集的结果很有前景。

概述
噪点在任何成像系统中都存在,但在亮度较低的环境中成像就更加困难。提高ISO可以增加亮度,但也会造成更多噪点。后期处理也是改善噪点过多的方法,但这并不能解决信噪比(SNR)低的问题。其他手段虽然能提高SNR,但都有各自的缺陷。
的确,在低亮度中快速成像的问题一直没有好的解决方法。研究人员提出了各种去噪、去模糊、提高亮度的技术。但这些技术都是假设照片是在略暗淡、稍有噪点的环境中捕捉到的。相反,我们想研究的是在非常黑暗的情况下的成像效果,例如月光下。在这种条件下,传统相机成像的过程就无能为力了,图片必须用原始传感器数据重新构建。
我们提出的系统效果(最右)如图1所示:
图1
左图中,环境中的亮度极低,相机的亮度小于0.1lux,快门速度为1/30,光圈为f/5.6,ISO为8000(通常这已经很高了)。但是照相机照出来仍然是漆黑一片(这可是用索尼全画幅传感器)。
中间图中,把ISO调到409600,这已经超过了大多数相机的极限了,可以看到照出来的图像了,但是图像显得很暗,噪点较多,色彩失真。
而最右边我们的方法则清晰了许多。具体来说,我们训练了深度神经网络学习处理低亮度原始图像数据的过程,包括色彩转化、去马赛克、减少噪点、图像质量提高等等。
数据集
目前大多数处理低亮度的图片都是在合成数据或没有对应标准的低亮度图像上进行的,据我们所知,没有一个公开数据集可以用来训练或是测试低亮度图像处理。于是,我们就新建了一个数据集,称为See-in-the-Dark(SID)。数据集中共有5094张图像,它们都是在低亮度条件下捕捉到的、快速曝光的原始图像。每个低亮度图片都有对应的长时间曝光高质量图片(注意,一张高质量图片可能对应多张低亮度图片)。
数据集包括室内和室外的图像,室外图像大多于夜晚拍摄,光源来自月光或者路灯。室外场景的相机亮度在0.2lux和5lux之间。室内图像就更暗一些了,通常在0.03lux到0.3lux之间。
输入图像的曝光时间通常在1/30秒到1/10秒之间,相对应的正常图片的曝光时间为10到30秒。数据集的具体参数可看下表:
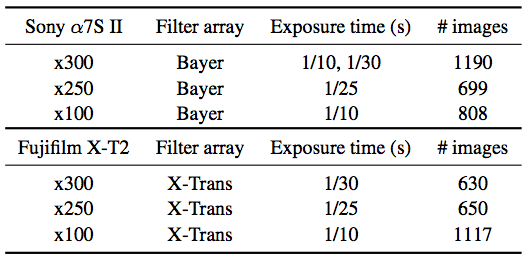
经过长时间曝光的正常图片仍含有少许噪点,但是从视觉上已经达到标准图片的水平了。我们希望我们创建的应用可以在低光度环境下生成表现良好的图像,而不是彻底消除所有噪点或让图像对比度最大化。
模型成像方法
从成像传感器中得到原始数据后,传统图像处理过程会应用一系列模块,例如白平衡、去马赛克、去噪、增加锐度等等。而这些模块只是在某些相机中才有。Jiang等人提出,用本地、线性、可学习的(L3)过滤器来模型现代成像系统中复杂的非线性流程。但是,这些方法都无法成功解决在低亮度中快速成像的问题,还是由于极低的SNR问题。之后,Hasinoff等人对智能手机上的相机提出了bursting imaging成像方法,通过结合多张图像可以生成效果较好的图像,但是复杂程度较高。
对此,我们提出了的端到端的学习方法,即训练一个全卷积网络(FCN)进行图像处理。图2展示了我们所提出的图像处理架构:
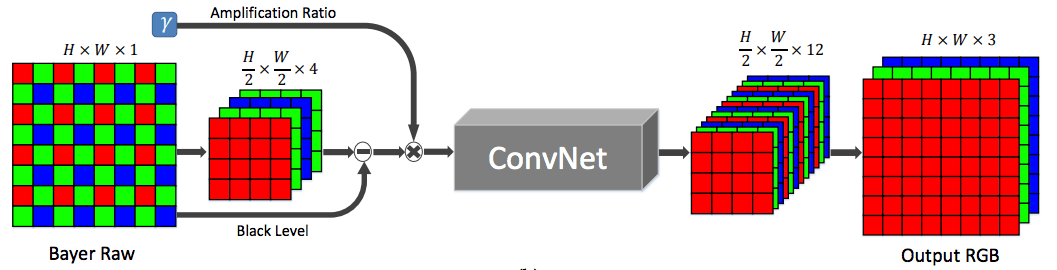
图2
对于拜耳阵列,我们将输入的图像打包到四个通道中,并相应地将空间分辨率在每个维度上降低。对于X-Trans阵列(图中未显示),原始数据是按6×6排列的,我们将其打包放到9个通道中。打包后的数据输入到全卷积网络中,输出一个有12通道的图像,空间向量仅为一半。而这个半尺寸的输出被次像素图层处理后,可以恢复到原始分辨率。
基本介绍之后,我们要重点了解一下网络中两个重要的结构:一个多尺寸文本聚合网络(CAN)和U-net。其他工作研究了残差连接,但是我们认为这对我们的模型用处不大,可能是因为我们的输入和输出在不同的颜色空间中表示。另一个影响模型结构选择的是内存消耗,我们的架构可以在GPU上处理全分辨率的图像。由此避免了全连接的图层,他们还需要处理小的图像补丁,然后重新进行组合。我们默认的架构是u-net。
放大比例决定了输出图像的亮度。在我们的图像生成流程中,放大比例是外部决定的,并且是作为图像流程的输入,类似于相机的ISO。图3显示了不同的放大倍数的结果,用户可以自己调整以改变亮度。
图3
最终网络利用L1损失和Adam优化器从零开始训练。
实验过程
首先,将我们提出的方法与传统方法的对比,得到以下结果:
图4
图5
图6
可以看出,我们的方法生成的图片比传统方法优秀得多。
同时,我们认为专门用特定的相机传感器进行训练的网络总能达到最佳效果。但是,最初的实验表明这不是一定的。我们将一个在索尼套件上训练的模型应用于由iPhone 6S拍摄出的相片上,其中通要包含一个拜耳过滤阵列和14位的原始数据。我们用一款app手动设置ISO和其他参数,输出原始数据用于处理。最终的结果如图5所示。传统方法处理的数据有很多噪点,色差较大。而我们的网络生成的图片对比度较强、噪点少并且颜色正常。
结语
由于极少的光子数量和极低的信噪比,在黑暗环境中成像一直是个大难题。想以视频速率在黑暗中成像,对于传统的信号处理方法来说几乎是不可能的。而我们提出的See-in-the-Dark数据集、全卷机的网络证明了这种在极端条件下成像的可能。最后的实验也证明这种方法行之有效,我们希望这项工作能在未来提供更多帮助。
-
英特尔
+关注
关注
61文章
10025浏览量
172494 -
ISO
+关注
关注
0文章
267浏览量
39697
原文标题:CVPR 2018 | 英特尔推出黑暗中也能清晰成像的系统,效果出色
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
世纪大并购!传高通有意整体收购英特尔,英特尔最新回应

英特尔推出全新英特尔锐炫B系列显卡

英特尔考虑出售Altera股权
英特尔至强品牌新战略发布
英特尔推出全新实感深度相机模组D421
Inflection AI携手英特尔推出企业级AI系统
英特尔是如何实现玻璃基板的?
英特尔发布AI创作应用AI Playground,将于今夏正式上线!

英特尔CEO:AI时代英特尔动力不减
英特尔率先推出业界高数值孔径 EUV 光刻系统


英特尔首推面向AI时代的系统级代工
英特尔首推面向AI时代的系统级代工—英特尔代工






 工商网监
工商网监
评论