 NVIDIA Volta GPU中内置的Tensor Core GPU架构是NVIDIA深度学习平台的巨大进步
NVIDIA Volta GPU中内置的Tensor Core GPU架构是NVIDIA深度学习平台的巨大进步
基于深度学习的人工智能如今能够解决一度认为不可能解决的问题,例如计算机理解自然语言并以自然语言对话、自动驾驶等。深度学习在解决诸多挑战时都颇有成效。受此激发,算法的复杂性也呈指数级增长,进而也引发了对更快计算速度的需求。NVIDIA设计的Volta Tensor Core架构即可满足这些需求。
NVIDIA以及许多其他公司和研究人员一直致力于开发计算硬件和软件平台,以满足这一需求。例如,谷歌创建了TPU(tensor processing unit)加速器,该加速器目前支持运行有限数量的神经网络,并表现出了良好的性能。
我们将为大家分享近期的一些进展,这些进展为GPU社群带来了巨大的性能提升。我们已经实现了单芯片和单服务器ResNet-50性能的新纪录。近期,fast.ai公司还宣布在单一云实例上实现了创纪录的性能。
我们的结果表明:
在训练ResNet-50时,单一V100 Tensor Core GPU可达到1075张图像/秒,与前一代Pascal GPU相比,性能提升了4倍。
基于8个Tensor Core V100的单台DGX-1服务器在同样的系统上实现了7850张图像/秒,几乎是一年前(4200张图像/秒)的两倍。
基于8个Tensor Core V100的单一AWS P3云实例可在不到三个小时的时间内训练ResNet-50,比TPU实例快3倍。

图1. Volta Tensor Core GPU在ResNet-50中实现创纪录的速度(AWS P3.16xlarge实例包含8个Tesla V100 GPU)。
NVIDIA GPU基于多样化算法的大规模并行处理性能使其自然而然成为了深度学习的理想之选。但我们并没有停滞于此。利用我们多年的经验以及与全球各地AI研究人员的密切合作,我们创建了针对多种深度学习模式进行了优化的新架构——NVIDIA Tensor Core GPU。
将NVLink高速互联与所有当前框架内的深度优化相结合,我们实现了领先的性能。NVIDIA CUDA GPU的可编程性可确保多样化的现代网络性能,同时提供了一个平台以助力新兴框架和未来深度网络领域的创新。
创下单一处理器速度纪录
NVIDIA Volta GPU中内置的Tensor Core GPU架构是NVIDIA深度学习平台的巨大进步。这一新硬件加速了矩阵乘法与卷积的计算,这也是训练神经网络时的计算操作的重头。
NVIDIA Tensor Core GPU架构使我们能够同时提供比单一功能的ASIC更高的性能,但可针对不同的工作负载进行编程。例如,每个Tesla V100 Tensor Core GPU可为深度学习提供125 teraflops的性能,而谷歌的TPU芯片为45 teraflops。“Cloud TPU”中的四个TPU芯片可达到180 teraflops的性能;相比之下,四个V100芯片能实现500 teraflops的性能。
NVIDIA的CUDA平台使每个深度学习框架都能充分利用Tensor Core GPU,加速扩展神经网络类型,如CNN、RNN、GAN、RL,以及每年涌现的数千种变体。
让我们深入研究一下Tensor Core架构,以了解其独特功能。图2显示了Tensor Core在精度较低的FP16中存储张量,而使用更高精度FP32进行计算,在保持必要精度的同时实现吞吐量最大化。
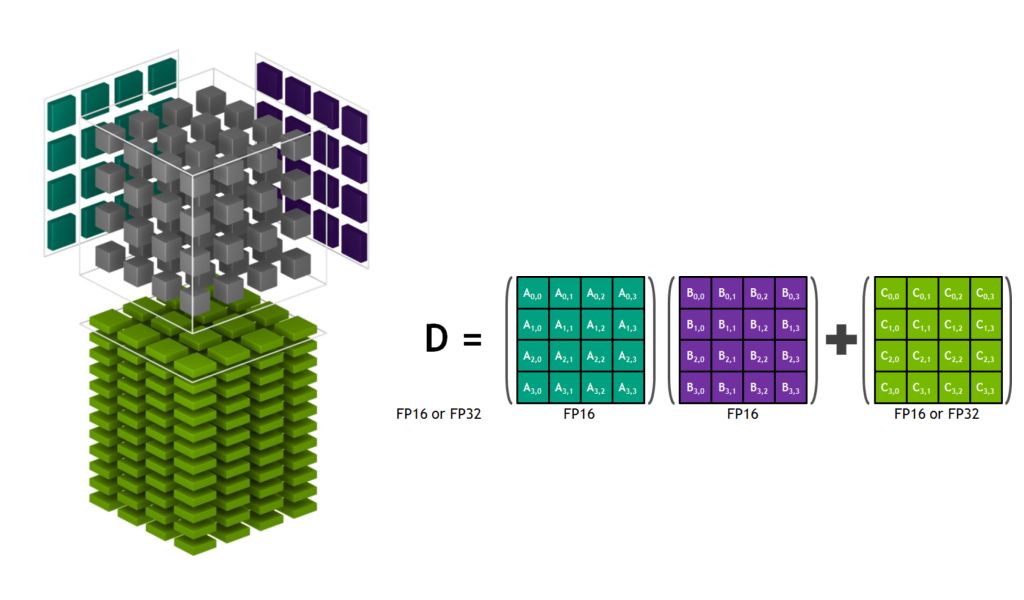
图2: Volta Tensor Core矩阵乘法与堆积
通过最近的软件改进,在独立测试中,如今ResNet-50训练可在单一V100上做到1360张图像/秒。我们现在正努力将这一训练软件集成到广泛采用的框架中,如下所述。
Tensor Core所运行的张量应位于存储器的channel-interleaved型数据布局(数量-高度-宽度-通道数,通常称为NHWC),以实现最佳性能。训练框架预期的内存布局是通道主序的数据布局(数量-通道数-宽度-高度,通常称为NCHW)。因此,cuDNN库执行NCHW和NHWC之间的张量转置操作,如图3所示。如前所述,由于如今卷积本身如此之快,因此这些转置显然会占运行时间的一部分。
为避免此类转置,我们通过直接在NHWC格式中代替RN-50模型图中的每个张量来消除转置,这是MXNet框架可支持的特性。此外,我们为MXNet添加了优化的NHWC实施,为所有其它非卷积层添加了cuDNN,从而消除了训练期间对任何张量转置的需求。
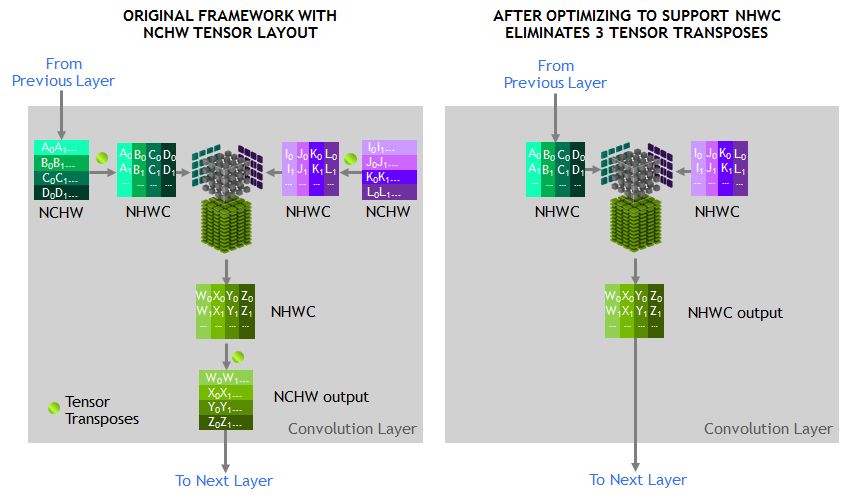
图3.优化的NHWC格式消除了张量转置
Amdahl定律也给了我们另一种优化的机会,该定律预测了并行处理的理论加速。由于Tensor Core显著加快了矩阵乘法和卷积层,因此训练负载中的其它层在运行时间中的占比就更高了。所以我们确定了这些新的性能瓶颈,并对其进行了优化。
如图4所示,向DRAM以及从DRAM转移数据导致许多非卷积层的性能受限。将连续层融合在一起的做法可利用片上存储器并避免DRAM流量。例如,我们在MXNet中创建了一个图形优化许可来检测连续的ADD和ReLu图层,并尽可能通过融合实施将其替换。使用NNVM(神经网络虚拟机)在MXNet中实施此类优化非常简单。
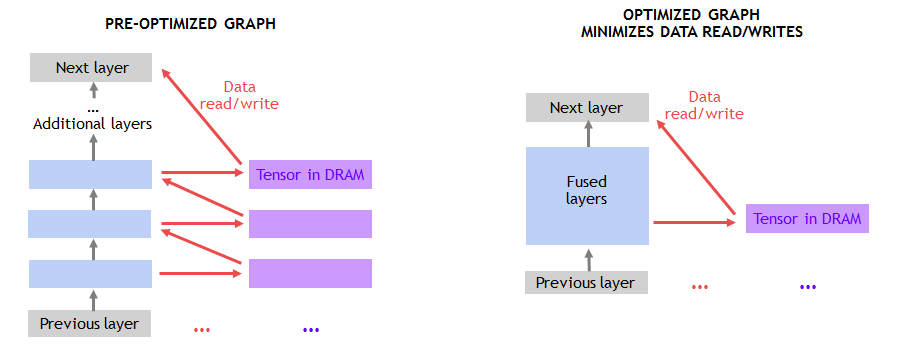
图4.融合层消除数据读/写
最后,我们通过为常见卷积类型创建额外的专用内核来继续优化单一卷积。
当前,我们针对多种深度学习框架进行了此类优化,包括TensorFlow、PyTorch和MXNet。基于针对MXNet的优化,利用标准的90次迭代训练进度,我们在一台Tensor Core V100上实现了1075张图像/秒,同时达到了与单精度训练相同的Top-1分类精度(超过75%)。这为我们留下了进一步提升的巨大空间,因为我们可在独立测试中做到1360张图像/秒。这些性能提升在NGC(NVIDIA GPU Cloud)的NVIDIA优化深度学习框架容器中即可获得。
最快的单节点速度纪录
多个GPU可作为单一节点运行,以实现更高的吞吐量。但是,扩展至可在单一服务器节点中协同工作的多个GPU,需要GPU之间具有高带宽/低延迟通信路径。我们的NVLink高速互联结构使我们能够将性能扩展至单一服务器中的8个GPU。如此大规模加速的服务器提供了全面的petaflop级的深度学习性能,且可广泛用于云端和本地部署。
但是,扩展至8个GPU可大大提高训练性能,以至于框架中主机CPU执行的其它工作成为了限制性能的因素。具体而言,为框架中的GPU提供数据的管线需要大幅提升性能。
数据管线从磁盘读取编码的JPEG样本,对其进行解码,调整大小并增强图像(见图5)。这些增强操作提高了神经网络的学习能力,从而实现对训练模型更高精度的预测。鉴于8个GPU在处理框架的训练部分,这些重要的操作会限制整体性能。

图5:图像解码和增强的数据管线
为解决这一问题,我们开发了DALI(Data Augmentation Library),这是一个独立于框架的库,用于将工作从CPU分载至GPU上。如图6所示,DALI将部分JPEG解码工作、调整大小、以及所有其它增强功能一起转移到了GPU中。在GPU上进行这些操作要比CPU的执行速度快得多,因此可将工作负载从CPU分载出去。DALI使得CUDA通用并行性能更加突出。消除CPU瓶颈让我们能够在单一节点上保持7850张图像/秒的性能。
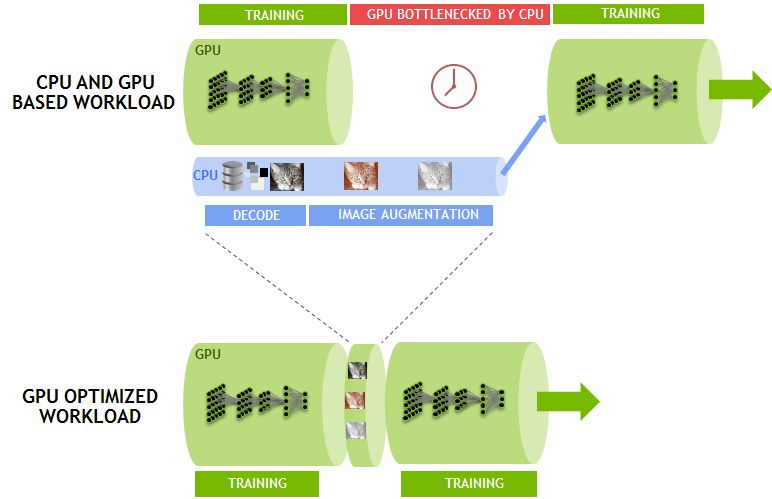
图6:使用DALI的GPU优化工作负载
NVIDIA正在助力将DALI整合到所有主要的AI框架中。该解决方案还使我们能够扩展至8个以上GPU的性能,例如最近推出的配备16个Tesla V100 GPU的NVIDIADGX-2系统。
最快的单一云实例速度纪录
对于我们的单GPU和单节点运行,我们采用90次迭代的事实标准来训练ResNet-50,使其单GPU和单节点运行的准确度超过75%。然而,通过算法创新和超参数调优,训练时间可进一步减少,从而仅需较少次数的迭代就能实现准确性。GPU为AI研究人员提供了可编程性并支持所有深度学习框架,使其能够探索新的算法方法并充分利用现有方法。
fast.ai团队最近分享了他们的优秀成果。他们使用PyTorch,不到90次迭代就实现了高精度。Jeremy Howard和fast.ai的研究人员将关键算法创新和调优技术整合到了AWS P3实例,三小时内在ImageNet上完成了对ResNet-50的训练,该实例由8个V100 Tensor Core GPU提供支持。ResNet-50的运行速度比基于TPU的云实例快三倍(后者需花费近9小时才能完成ResNet-50的训练)。
我们还期望本文中描述的提高吞吐量的方法也能够应用于像fast.ai等的其它研究方式,且能够帮助他们更快地进行聚集。
提供指数级的性能提升
自Alex Krizhevsky首次采用2个GTX 580 GPU在Imagenet竞赛中取胜以来,我们在加速深度学习方面所取得的进展非常显著。Krizhevsky花了六天的时间训练出了强大的神经网络,名为AlexNet,这在当时胜过了所有其他图像识别方法,开启了深度学习革命。现在用我们最近发布的DGX-2,在18分钟内就能完成对AlexNet的训练。图7显示了性能在短短5年内500倍的提升。
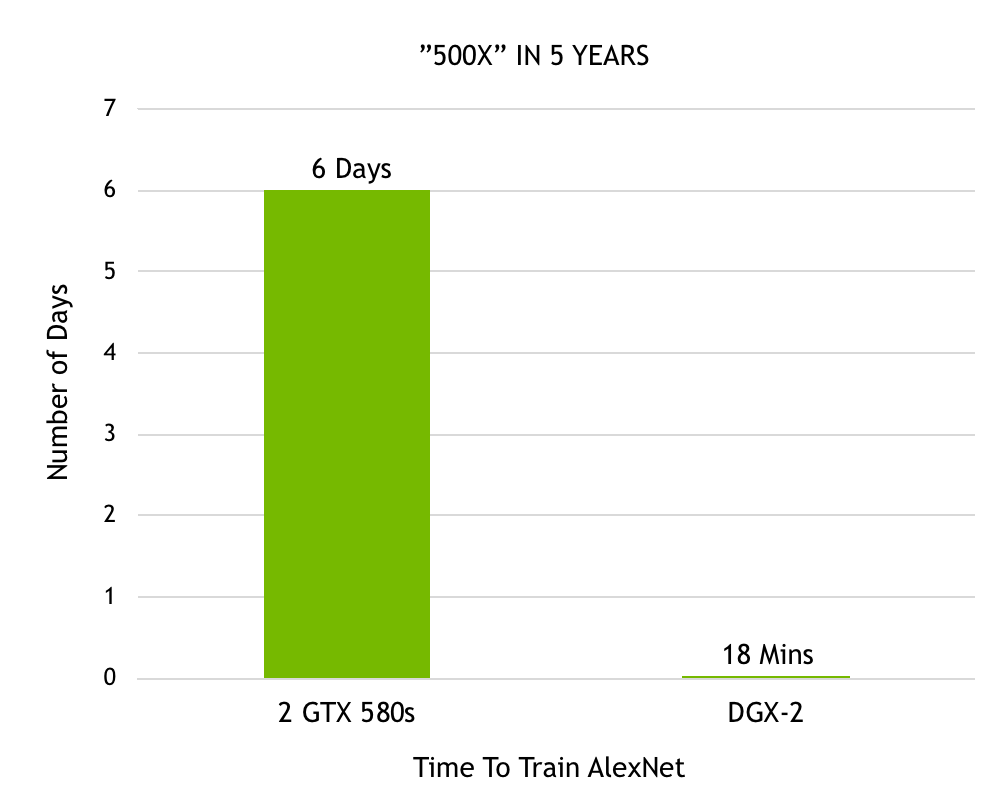
图7.在Imagnet数据集上训练AlexNet所需的时间
Facebook AI Research(FAIR)分享了他们的语言翻译模型Fairseq。我们在不到一年的时间内,通过最近发布的DGX-2,再加之我们众多的软件堆栈改进(见图8),在Fairseq上展现了10倍的性能提升。
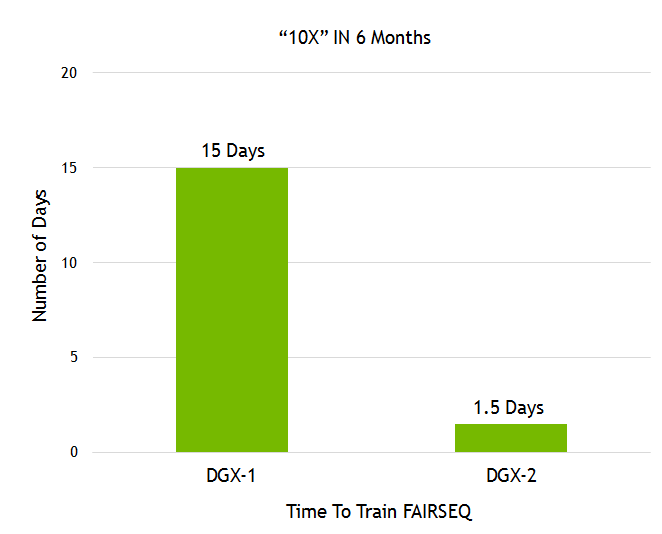
图8. 训练Facebook Fairseq所需的时间。
图像识别和语言翻译仅代表研究人员借助AI的力量解决的无数用例中的一小部分。超过6万个使用GPU加速框架的神经网络项目已发布至Github。我们GPU的可编程性可为AI社群正在构建的各种神经网络提供加速。快速的改进确保了AI研究人员能够就更为复杂的神经网络展开大胆设想,以借助AI应对巨大挑战。
这些优异的表现来自我们GPU加速计算的全堆栈优化方法。从构建最先进的深度学习加速器到复杂系统(HBM、COWOS、SXM、NVSwitch、DGX),从先进的数值库和深度软件堆栈(cuDNN、NCCL、NGC)、到加速所有深度学习框架,NVIDIA对于AI的承诺为AI开发者提供了无与伦比的灵活性。
我们将持续优化整个系列,并持续提供指数级的性能提升,为AI社群提供能够推动深度学习创新的工具。
总结
AI持续改变着每个行业,推动了无数用例。理想的AI计算平台需要提供出色的性能,以支持巨大且不断增长的模型规模,还需具有可编程性以应对日益多样化的模型架构。
NVIDIA的Volta Tensor Core GPU是世界上最快的AI处理器,只需一颗芯片即可提供125 teraflops的深度学习性能。我们很快将把16块Tesla V100整合成一个服务器节点,以创建全球速度最快的计算服务器,其可提供2 petaflops的性能。
除了优异的性能,GPU 的可编程性以及它在云、服务器制造商和整个AI社群中的广泛使用,将推动下一场AI变革。
我们能够加速以下所有您常用的框架:Caffe2、Chainer、CognitiveToolkit、Kaldi、Keras、Matlab、MXNET、PaddlePaddle、Pytorch和TensorFlow。此外,NVIDIA GPU与迅速扩展的CNN、RNN、GAN、RL和混合网络架构、以及每年新登场的数千种变体配合运行。AI社群已经出现了众多令人惊叹的应用,我们期待继续赋力AI的未来。
-
gpu
+关注
关注
28文章
4743浏览量
128992 -
人工智能
+关注
关注
1791文章
47350浏览量
238746 -
深度学习
+关注
关注
73文章
5504浏览量
121221
原文标题:又创纪录!Volta Tensor Core GPU实现新的AI性能突破
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA火热招聘深度学习/高性能计算解决方案架构师
NVIDIA火热招聘GPU高性能计算架构师
NVIDIA-SMI:监控GPU的绝佳起点
购买哪款Nvidia GPU
NVIDIA网格GPU-PSOD的支持结构
Nvidia GPU风扇和电源显示ERR怎么解决
在Ubuntu上使用Nvidia GPU训练模型
NVIDIA领先AMD 将在GTC上大谈下一代GPU架构Volta显卡
NVIDIA推出全球最强PC级GPU 可提供110TFLOP深度学习运算
NVIDIA安培大核心GPU已集合多个国内厂商技术
阿里云震旦异构计算加速平台基于NVIDIA Tensor Core GPU
火山引擎机器学习平台与NVIDIA加深合作
Oracle 云基础设施提供新的 NVIDIA GPU 加速计算实例

NVIDIA GPU的核心架构及架构演进





 工商网监
工商网监
评论