 异步binder call是如何阻塞整个系统的
异步binder call是如何阻塞整个系统的
引言
本文讲解异步binder call是如何阻塞整个系统的,通过ramdump信息以及binder通信协议来演绎并还原定屏现场。
一、背景知识点
解决此问题所涉及到的基础知识点有:Trace、CPU调度、Ramdump推导、Crash工具、GDB工具、Ftrace, 尤其深入理解binder IPC机制。
1.1 工具简介
Trace:分析死锁问题的最基本的技能,通过kill -3可生成相应的traces.txt文件,里面记录着当前时刻系统各线程 所处在的调用栈。
CPU调度:可通过查看schedstat节点,得知该线程是否长时间处于RQ队列的等待
Ramdump:把系统memory中某一个时间点的数据信息保存起来的内存崩溃文件,属于ELF文件格式。 当系统发生致命错误无法恢复的时候,主动触发抓取ramdump能异常现场保留下来,这是属于高级调试秘籍。
Crash工具:用于推导与分析ramdump内存信息。
GDB工具:由GNU开源组织发布的、UNIX/LINUX操作系统下的基于命令行的强大调试工具,比如用于分析coredump
Ftrace:用于分析Linux内核的运行时行为的强有力工具,比如能某方法的耗时数据、代码的执行流情况。
1.2 Binder简介
Binder IPC是最为整个Android系统跨进程通信的基石,整个系统绝大多数的跨进程都是采用Binder,如果对Binder不太了解看本文会非常吃力,在Gityuan.com博客中有大量讲解关于Binder原理的文章,见http://gityuan.com/2015/10/31/binder-prepare/,这里不再赘述。
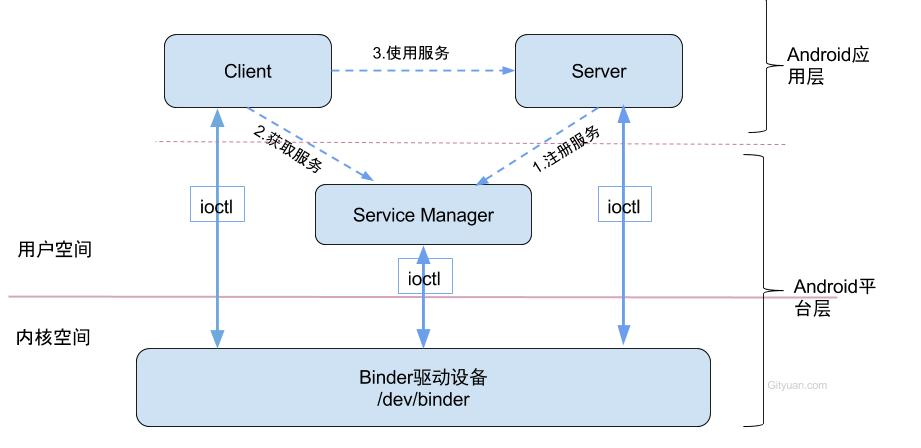
简单列两张关于Binder通信架构的图,
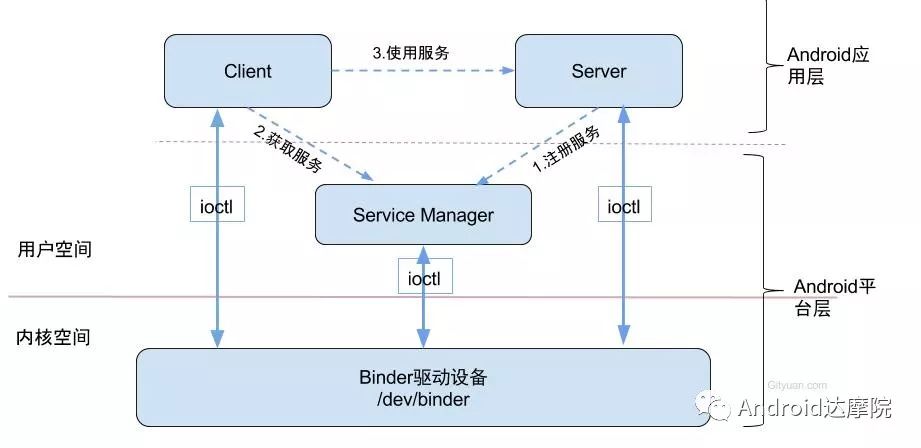
Binder通信采用C/S架构,主要包含Client、Server、ServiceManager以及binder驱动部分,其中ServiceManager用于管理系统中的各种服务。Client向Server通信过程图中画的是虚线,是由于它们彼此之间不是直接交互的,而是采用ioctl的方式跟Binder驱动进行交互的,从而实现IPC通信方式。
接下来再以startService为例,展示一次Binder通信过程的方法执行流:
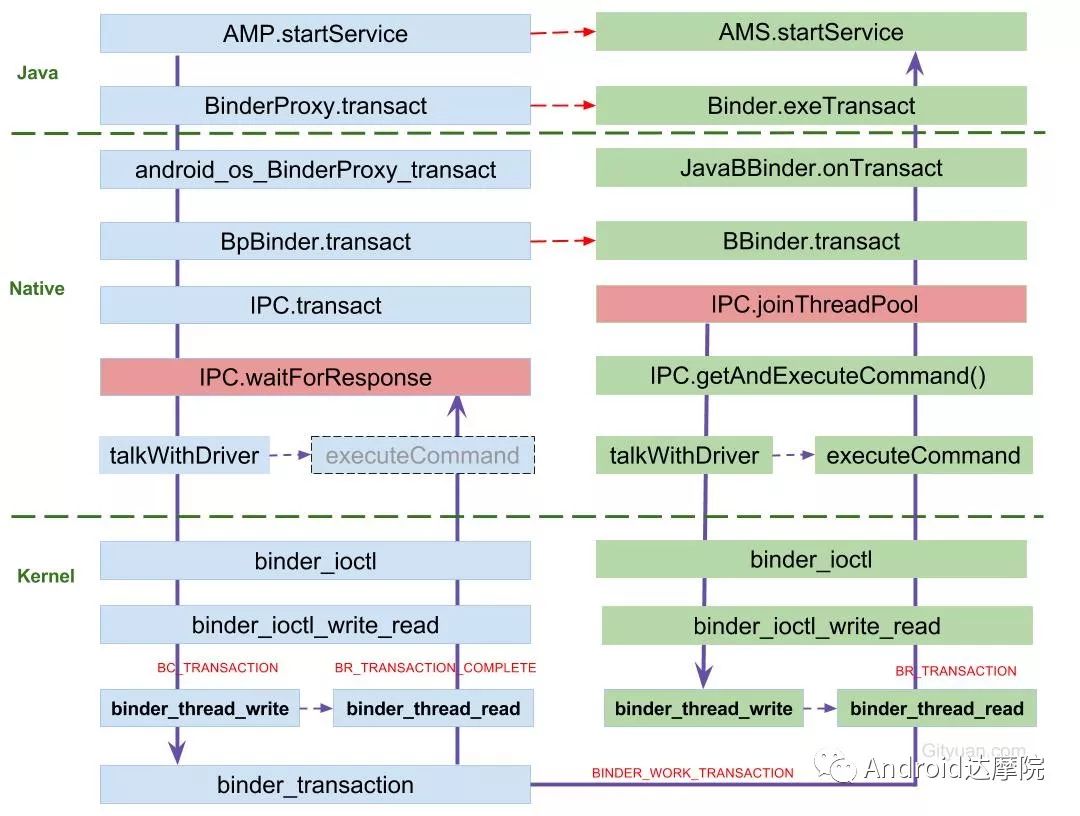
从图中,可见当一次binder call发起后便停在waitForResponse()方法,等待执行完具体工作后才能结束。
那么什么时机binder call端会退出waitForResponse()方法?见下图:

退出waitForResponse场景说明:
1)当Client收到BR_DEAD_REPLY或BR_FAILED_REPLY(往往是对端进程被杀或者transaction执行失败),则无论是同步还是异步的binder call都会结束waitForResponse()方法。
2)正常通信的情况下,当收到BR_TRANSACTION_COMPLETE则结束同步binder call; 当收到BR_REPLY则结束异步binder call。
二、初步分析
有了以上背景知识的铺垫,接下来就进入正式实战分析过程。
2.1 问题描述
Android 8.0系统用几十台手机连续跑几十个小时Monkey的情况下有概率出现定屏问题。
定屏是指屏幕长时间卡住不动,也可以成为冻屏或者hang机,绝大多数情况下都是由于多个线程之间存在直接或者间接死锁而引发,而本案例实属非常罕见例子, 异步方法处于无限等待状态被blocked,从而导致的定屏。
2.2 初步分析
通过查看trace,不难发现导致定屏的原因如下:
system_server的所有binder线程以及其中重要现场都在等待AMS锁, 而AMS锁被线程Binder:12635_C所持有; Binder:12635_C线程正在执行bindApplication()方法,调用栈如下:
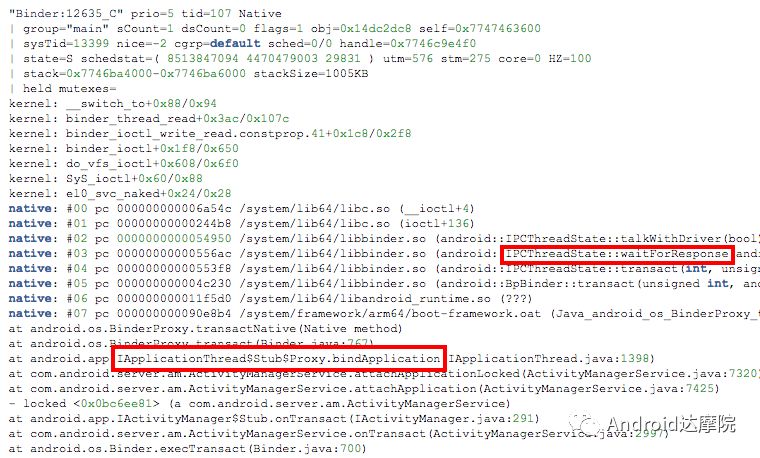
终极难题:attachApplicationLocked()是属于异步binder call,之所以叫异步binder call,就是由于可异步执行而并不会阻塞线程。 但此处却能阻塞整个系统,这一点基本是毁三观的地方。
怀疑1:有同学可能会觉得是不是Binder驱动里的休眠唤醒问题,对端进程出现异常导致无法唤醒该binder线程从而阻塞系统?
回答1:这个观点咋一看,好像合情合理,还挺能唬人的。接下来,我先来科普一下,以正视听。
如果熟悉Binder原理的同学,应该知道上面说的是不可能发生的事情。oneway binder call,也就是所谓的异步调用, Binder机制设计绝不可能傻到让异步的binder call来需要等待对端进程的唤醒。
真正的oneway binder call, 一旦是事务发送出去。 a)如果成功,则会向自己线程thread->todo队列里面放上BINDER_WORK_TRANSACTION_COMPLETE; b)如果失败,则会向自己线程thread->todo队列里面放上BINDER_WORK_RETURN_ERROR。
紧接着,就会在binder_thread_read()过程把刚才的BINDER_WORK_XXX读取出去,然后调出此次binder call。 之所以要往自己队列放入BINDER_WORK_XXX,为了告知本次事务是否成功的投递到对端进程。但整个过程,无需对端进程的参与。
也就是说bindApplication()方法作为异步binder调用方法,只会等待自己向自己todo队列写入的BR_TRANSACTION_COMPLETE或BR_DEAD_REPLY或BR_FAILED_REPLY。
所以说,对端进程无法唤醒的说法是绝无可能的猜想。
怀疑2:CPU的优先级反转问题,当前Binder线程处于低优先级,无法分配到CPU资源而阻塞系统?
回答2:从bugreport中来分析定屏过程被阻塞线程的cpu调度情况。
先讲解之前,先来补充一点关于CPU解读技巧:

nice值越小则优先级越高。此处nice=-2, 可见优先级还是比较高的;
schedstat括号中的3个数字依次是Running、Runable、Switch,紧接着的是utm和stm
Running时间:CPU运行的时间,单位ns
Runable时间:RQ队列的等待时间,单位ns
Switch次数:CPU调度切换次数
utm: 该线程在用户态所执行的时间,单位是jiffies,jiffies定义为sysconf(_SC_CLK_TCK),默认等于10ms
stm: 该线程在内核态所执行的时间,单位是jiffies,默认等于10ms
可见,该线程Running=186667489018ns,也约等于186667ms。在CPU运行时间包括用户态(utm)和内核态(stm)。 utm + stm = (12112 + 6554) ×10 ms = 186666ms。
结论:utm + stm = schedstat第一个参数值。
有了以上基础知识,再来看bugreport,由于系统被hang住,watchdog每过一分钟就会输出依次调用栈。我们把每一次调用找的schedstat数据拿出来看一下,如下:

可见,Runable时间基本没有变化,也就说明该线程并没有处于CPU等待队列而得不到CPU调度,同时Running时间也几乎没有动。 所以该线程长时间处于非Runable状态,从而排除CPU优先级反转问题。
再看Event Log

疑问:appDiedLock()方法一般是通过BinderDied死亡回调的情况下才执行,但死亡回调肯定是位于其他线程,由于该binder线程正处于繁忙状态,并没有时间处理。 为什么同一个线程正在执行attachApplication()的过程,并没有结束的情况下还能执行appDiedLock()方法?
观察多份定屏的EventLog,最后时刻都会先执行attachApplication(),然后执行appDiedLock()。
此处怀疑跟杀进程有关或者是在某种Binder嵌套调用的情况下,将这两件事情合在binder线程?这些都只是猜疑,本身又是概率问题,需要更深入地分析才能解答这些疑团。
三、ramdump分析
有效的信息太少,基本无法采用进一步分析,只能通过抓取ramdump希望能通过里面的蛛丝马迹来推出整个过程。
抓取的ramdump是只是触发定屏后的最后一刻的异常现场,这就好比犯罪现场最后的画面,我们无法得知案发的动机是什么, 更无法得知中间到底发生了哪些状态。要基于ramdump的静态画面,去推演整个作案过程,需要强大的推演能力。 先来分析这个ramdump信息,找到尽可能多的有效信息。
3.1 结构体binder_thread
从ramdump中找到当前处于blocked线程的调用栈上的方法binder_ioctl_write_read(), 该方法的的第4个参数指向binder_read结构体。
利用crash工具便可进一步找到binder_thread的结构体如下:
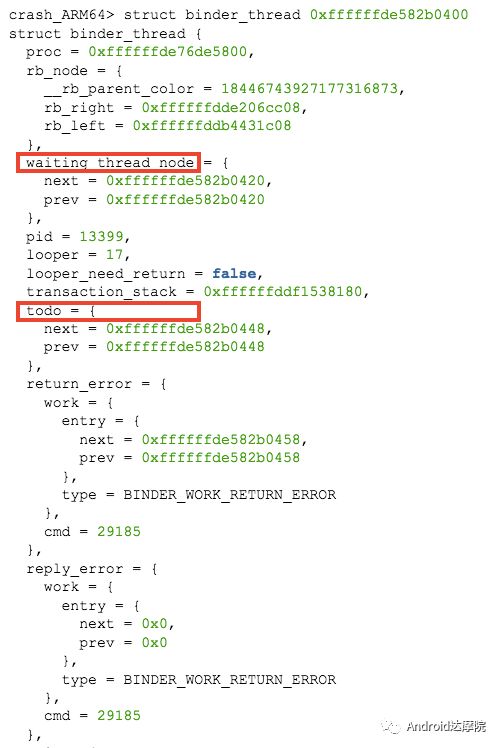
解读:
waiting_thread_node为空,则说明binder线程的 thread→transaction_stack不为空 或者 thread→todo不为空;
todo为空,结合前面的waiting_thread_node,则说明thread→transaction_stack一定不为空;
return_error和reply_error的cmd等于29185, 转换为16进制等于0x7201, 代表的命令为BR_OK = _IO(‘r’, 1), 说明该binder线程的终态并没有error,或者中间发生error并且已被消耗掉;
looper = 17, 说明该线程处于等待状态BINDER_LOOPER_STATE_WAITING
3.2 binder_transaction结构体
既然thread→transaction_stack不为空,根据结构体binder_thread的成员transaction_stack = 0xffffffddf1538180, 则解析出binder_transaction结构体:

解读:
from = 0x0, 说明发起端进程已死
sender_euid=10058, 这里正是event log中出现的被一键清理所杀的进程,这里隐约能感受到此次异常跟杀进程有关
to_thread所指向的是当前system_server的binder线程,说明这是远端进程向该进程发起的请求
flags = 16, 说明是同步binder call
code = 11,说明该调用attachApplication(),此处虽无法完成确定,但从上下文以及前面的stack,基本可以这么认为,后续会论证。
到这里,想到把binder接口下的信息也拿出来,看看跟前面基本是吻合的code=b, 也应该是attachApplication(), 如下:
thread 13399: l 11 need_return 0 tr 0 incoming transaction 2845163: ffffffddf1538180 from 0:0 to 12635:13399 code b flags 10 pri 0:120 r1 node 466186 size 92:8 data ffffff8014202c98
3.3 特殊的2916
看一下kernel Log,被hang住的binder线程有一个Binder通信失败的信息:
binder : release 6686:6686 transaction 2845163 out, still active binder : 12635:13399 transaction failed 29189/-22, size 3812-24 line 2916
29189=0x7205代表的是BR_DEAD_REPLY = _IO(‘r’, 5), 则代表return_error=BR_DEAD_REPLY,发生错误行是2916,什么场景下代码会走到2916行呢, 来看Binder Driver的代码:
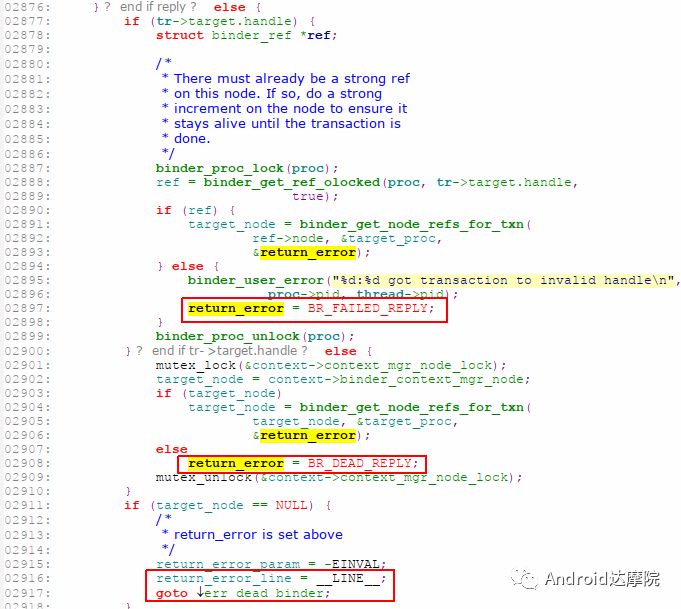
根据return_error=BR_DEAD_REPLY,从2916往回看则推测代码应该是走到2908行代码; 往上推说明target_node = context→binder_context_mgr_node,这个target_node是指service_manager进程的binder_node。 那么binder_context_mgr_node为空的场景,只有触发servicemanger进程死亡,或者至少重启过;但通过查看servicemanger进程并没有死亡和重启; 本身走到2900行, tr->target.handle等于空,在这个上下文里面就难以解释了,现在这个来看更是矛盾。
到此,不得不怀疑推理存在纰漏,甚至怀疑日志输出机制。经过反复验证,才发现原来忽略了2893行的binder_get_node_refs_for_txn(),代码如下:

一切就豁然开朗,由于对端进程被杀,那么note→proc==null, 从而有了return_error=BR_DEAD_REPLY。
3.4 binder_write_read结构体
看完被阻塞的binder线程和事务结构体,接着需要看一下数据情况,调用栈上的binder_ioctl_write_read()方法的第三个参数便指向binder_write_read结构体, 用crash工具解析后,得到如下信息:

解读:
write_size=0, 看起来有些特别,本次通信过程不需要往Binder Driver写数据,常规transaction都有命令需写入Binder Driver;
read_size=256,本次通信过程需要读取数据;
那么什么场景下,会出现write_size等于0,而read_size不等于0呢? 需要查看用户空间跟内核空间的Binder Driver交互的核心方法talkWithDriver(),代码如下:
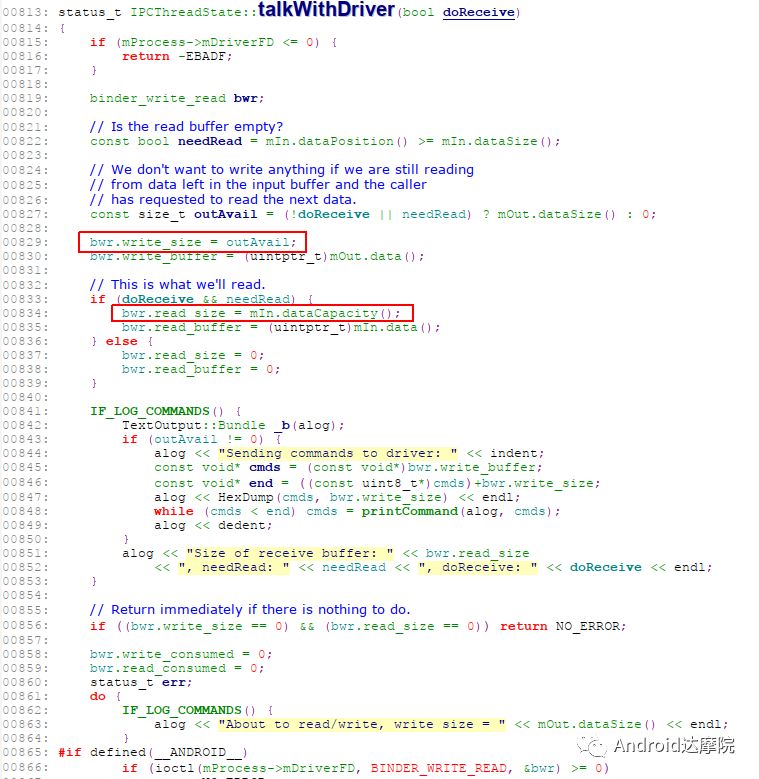
从上述代码可知:read_size不等于0,则doReceive=true, needRead=true,从而mIn等于空; 再加上write_size=0则mOut为空。 也就是说该blocked线程最后一次跟Binder驱动交互时的mIn和mOut都为空。
而目前的线程是卡在attachApplicationLocked()过程,在执行该方法的过程一定是会向mOut里面写入数据的。但从案发后的最后一次现场来看mOut里面的数据却为空, 这是违反常规的操作,第一直觉可能会怀疑是不是出现了内存踩踏之类的,但每次都这么凑巧地能只踩踏这个数据,是不太可能的事。为了进一步验证,再把mOut和mIn这两个buffer的数据拿出来。
3.5 mOut && mIn
IPCThreadState结构体在初始化的时候,分别设置mOut和mIn的size为256。Binder IPC过程便是利用mOut和mIn 分别承担向Binder驱动写数据以及从Binder驱动读数据的功能。
虽然在反复使用的过程中会出现老的命令被覆盖的情况, 但还是可能有一些有用信息。
mOut和mIn是用户空间的数据,并且是IPCThreadState对象的成员变量。程序在用户空间停在IPCThreadState的waitForResponse()过程, 采用GDB打印出当前线程用户空间的this指针的所有成员,即可找到mOut和mIn

解读: mIn缓存区,mDataSize = 16, mDataPos = 16, 说明最后的talkWithDriver产生了两个BR命令,并且已处理;mOut缓存区,mDataSize = 0, mDataPos = 0,说明BC_XXX都已被消耗
再来进一步看看这两个缓存区中的数据,从上图可知mIn和mOut的mData地址分别为0x7747500300、0x7747500400,缓存区大小都等于256字节; mIn缓存区中存放都是BR_XXX命令(0x72);mOut缓存区中存放都是BC_XXX命令(0x63)。 再来分别看看两个缓存区中的数据:
mIn缓存区数据:

解读:BR_NOOP = 0x720c, BR_CLEAR_DEATH_NOTIFICATION_DONE = 0x7210,可知mIn数据区中最后一次talkWithDriver的过程产生了两个BR命令依次是: BR_NOOP, BR_CLEAR_DEATH_NOTIFICATION_DONE
mOut缓存区数据:

解读:BC_FREE_BUFFER = 0x6303, BC_DEAD_BINDER_DONE = 0x6310,可知mOut数据区最后一次talkWithDriver的过程,所消耗掉的BC命令依次是:BC_FREE_BUFFER, BC_DEAD_BINDER_DONE
分析两份ramdump里面的mOut和mIn数据区内容内容基本完全一致,缓存区中的BC和BR信息完全一致。整个过程,通过ramdump推导发现被阻塞线程的todo队列居然为空,最后一次处理过的transaction是BC_FREE_BUFFER、BC_DEAD_BINDER_DONE和BR_NOOP、BR_CLEAR_DEATH_NOTIFICATION_DONE,能解读出来对本案例有所关联线索也就只有这么多。
3.6 疑难悬案
解决系统疑难问题可能不亚于去案件侦破,而本案就好比是密室杀人案。
案发后第一时间去勘察现场(抓取ramdump),从房门和窗口都是由内部紧锁的(mIn缓存区的write_size等于0),凶手作案后是如何逃离现场的(todo队列为空)?从被害人(blocked线程)身体留下的剑伤并不会致命(异步线程不会被阻塞),那到底死因是什么呢?
从现场种种迹象来看(ramdump推导)很有可能是这并非第一案发现场(BUG不是发现在当前binder transaction过程),极有可能是凶手在它处作案(其他transaction)后,再移尸到当前案发现场(binder嵌套结束后回到上一级调用处),那么真正的第一案发现场又在哪里呢?
Trace、Log、Ramdump推导、Crash工具、GDB工具等十八般武艺都用过一轮了,已经没有更多的信息可以挖掘了,这个问题几乎要成为无头公案。
四、真相大白
4.1 案件侦破
此案一日不破,有如鲠在噎,寝食难安。脑中反复回放案发现场的周边布置,有一个非常重大的疑点进入脑海,其中有一个物件(BC_DEAD_BINDER_DONE协议)正常应该在其他房间(binder死亡讣告相关),可为何会出现在案发现场(bindApplication的waitForResponse过程)呢?
基于最后的现场,顺着这个线索通过逆向推理分析,去试图推演凶手的整个作案过程。但对于如此错终复杂的案情(binder通信系统每时每刻都有大量的事transaction发生着,协议之间的转换也比较复杂)。
这个逆向推理过程非常复杂,通过不断逆向与正向结合分析,每一层逆向回推,都会有N种可能性,尽可能多地排除完全不可能的分支,保留可能的分支再继续回推,在整个推演过程最为烧脑与费时,见封面照片有大量的推理过程。最终奇迹般地找到了第一案发现场,也找到了复现方法,为了节省篇幅,此处省略一万字。
直接拿出结论,真正的第一案发现场如下:在进程刚启动不久,执行到linkToDeath()方法前的瞬间将其杀掉则能复现定屏:
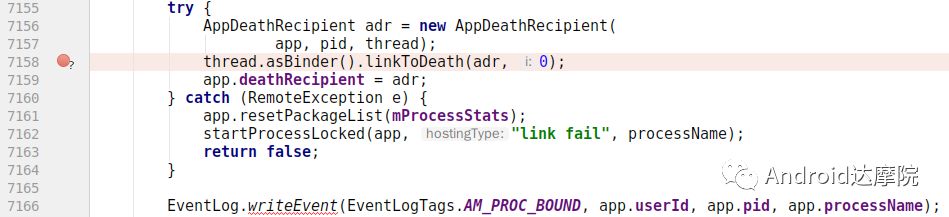
4.2 案卷解读
这个问题的复杂在于,即便找到了第一个案发现场以及复现路径,要完全理解中间的每一次协议转换过程,也是比较复杂的。 通过如下命令打开binder driver的ftrace信息,用于输出每次binder通信协议与数据。

整个binder通信会不断地在用户空间与内核空间之间进行切换, Binder IPC通信过程的数据流向说明:( BINDER_WORK_XXX简称为BW_XXX)
mOut:记录用户空间向Binder Driver写入的命令
通过binder_thread_write()和binder_transaction()方法消费BC命令,并产生相应的BW_XXX命令,也可能不产生BW命令
当thread->return_error.cmd != BR_OK,则不会执行binder_thread_write()过程
thread→todo: 记录等待当前binder线程需要处理的BINDER_WORK
通过binder_thread_read()方法消费BW命令,并生产相应的BR_XX命令,也可能不产生BR命令
一般情况,没有BC_TRANSACION或者BC_REPLY,则不读取; BW_DEAD_BINDER例外;
mIn: 记录Binder Driver传到用户空间的命令
通过waitForResponse()和executeCommand()方法消费BR命令
另外,关于talkWithDriver, 当mIn有数据,意味着先不需要从binder driver读数据。原因:needRead=0,则read_buffer size设置为0,当doReceive=true,则write_buffer size也设置为0。从而此次不会跟driver交互。
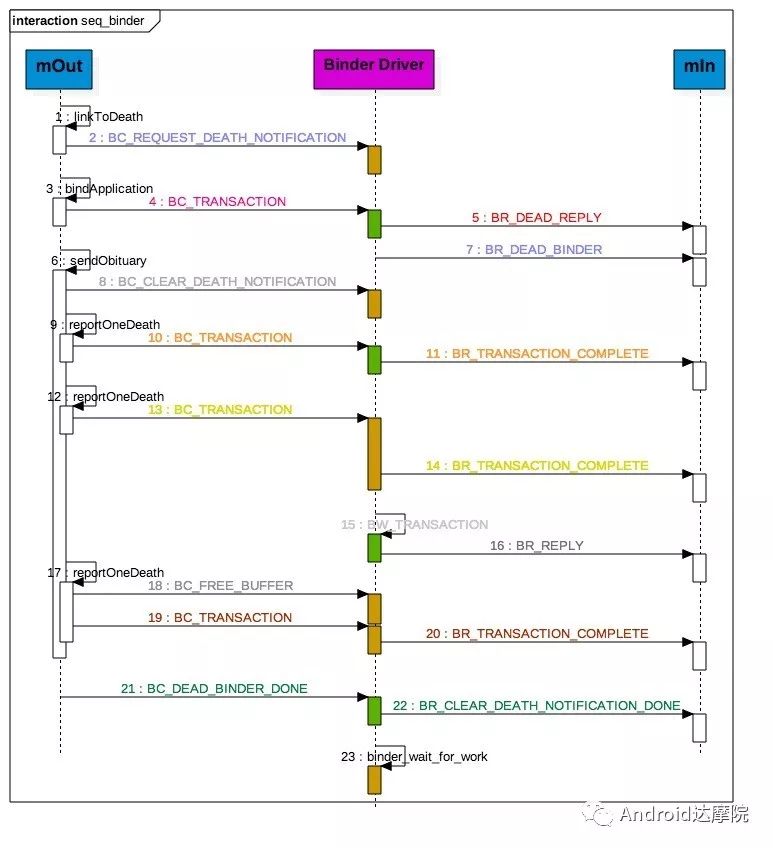
案发过程详细过程:
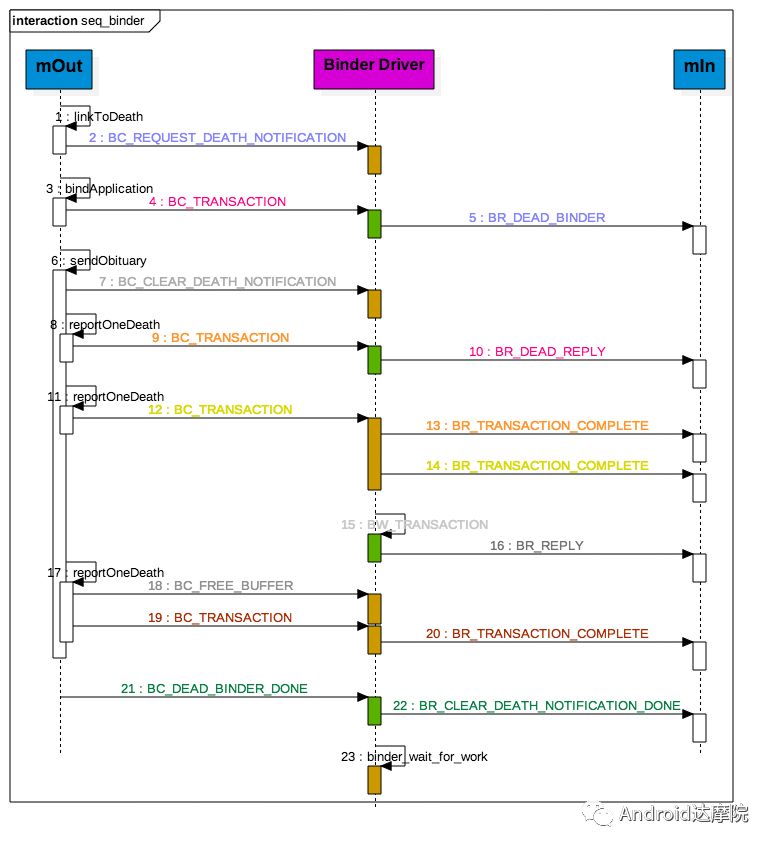
过程解读:(整个过程发生了9次 talkWithDriver)
该线程执行linkToDeath(),采用flush只写不读的方式,向Binder Driver的thread todo队列写入BW_DEAD_BINDER;
执行bindApplication(), 由于目标进程已死,则写入BW_RETURN_ERROR到todo队列,此时return_error.cmd = BR_DEAD_REPLY; 内核空间,将BW_DEAD_BINDER转换为BR_DEAD_BINDER,同步将BW_DEAD_BINDER 放入proc->delivered_death; 回到用户空间,执行sendObituary(), 此时还处于bindApplication()的waitForResponse()。
向mOut添加BC_CLEAR_DEATH_NOTIFICATION,采用flush方式,加上return_error.cmd = BR_DEAD_REPLY,此次不写不读。
执行第一个reportOneDeath(),此时return_error.cmd = BR_DEAD_REPLY则不写入,取出BW_RETURN_ERROR,同时设置return_error.cmd=BR_OK; 回到用户空间,终结第一个reportOneDeath(),错误地消耗了bindApplication()所产生的BR_DEAD_REPLY。
执行第二个reportOneDeath(),同时消耗了第一个和第二个reportOneDeath所产生的BR_TRANSACTION_COMPLETE协议,由于第二个reportOneDeath是同步binder call, 还需继续等待BR_REPLY协议。
此时mOut和mIn都为空,进入内核binder_wait_for_work(),等待目标进程发起BC_REPLY命令,向当前线程todo队列放入BW_TRANSACTION;收到BW_TRANSACTION协议后转换为BR_REPLY,完成第二个reportOneDeath()。
执行第三个reportOneDeath(),收到BR_TRANSACTION_COMPLETE后,完成第二个reportOneDeath()。
到此彻底执行完sendObituary(),则需向mOut添加BC_DEAD_BINDER_DONE协议,收到该协议后,驱动将proc→delivered_death的BW_DEAD_BINDER_AND_CLEAR调整为BW_CLEAR_DEATH_NOTIFICATION,并放入thread->todo队列;然后生成BR_CLEAR_DEATH_NOTIFICATION_DONE,完成本次通信;
回到bindApplication()的waitForResponse,此时mOut和mIn都为空,进入内核binder_wait_for_work(), 该线程不再接收其他事务,也无法产生事务,则永远地被卡住。
共的来说,导致异步binder调用阻塞原因如下:
第一个异步reportOneDeath()消费掉bindApplication()所产生的BW_RETURN_ERROR;
第二个同步reportOneDeath()所消耗掉 第一个异步reportOneDeath()自身残留的BR_TRANSACTION_COMPLETE;
bindApplication()所产生的BW_RETURN_ERROR由于被别人所消费,导致陷入无尽地等待。
4.3 总结
真正分析远比这复杂,鉴于篇幅,文章只讲解其中一个场景,不同的Binder Driver以及不同的Framework代码组合有几种不同的表现与处理流程。不过最本质的问题都是在于在嵌套的binder通信过程,BR_DEAD_REPLY错误地被其他通信所消耗从而导致的异常。
我的解决方案是当transaction发生错误,则将BW_RETURN_ERROR事务放入到当前线程todo队列头部,则保证自己产生的BW_RETURN_ERROR事务一定会被自己所正确地消耗,从而解决异步binder通信在嵌套场景下的无限阻塞的问题,优化后的处理流程图:
当然还有第二个解决方案就是尽可能避免一切binder嵌套,Google在最新的binder driver驱动里面采用将BW_DEAD_BINDER放入proc的todo队列来避免嵌套问题,这个方案本身也可以,但我认为在执行过程出现了BW_RETURN_ERROR还是应该放到队列头部,第一时间处理error,从而也能避免被错误消耗的BUG,另外后续如果binder新增其他逻辑,也有可能会导致嵌套的出现,那么仍然会有类似的问题。
最近跟Google工程师来回多次沟通过这个问题,但他们仍然希望保持每次只往thread todo队列尾部添加事务的逻辑,对于嵌套问题希望通过将其放入proc todo队列的方式来解决。对此,担心后续扩展性方面会忽略或者遗忘,又引发binder嵌套问题,Google工程师表示未来添加新功能,也会杜绝出现嵌套逻辑,保持逻辑与代码的简洁。
最后,这个密室杀人案的确是在它处作案(reportOneDeath消费掉bindApplication所产生的BW_RETURN_ERROR)后,再移尸到当前案发现场(执行完BR_DEAD_BINDER后回到bindApplication的waitForRespone方法),从而导致异步Binder调用也能被阻塞。
-
通信协议
+关注
关注
28文章
892浏览量
40331 -
cpu
+关注
关注
68文章
10874浏览量
212108
原文标题:Binder Driver缺陷导致定屏的实战分析
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Verilog语言中阻塞和非阻塞赋值的不同
【AWorks280试用体验】POLL机制、异步通知、互斥阻塞
什么是ACD (Automatic Call Distrib
详解同步异步和阻塞非阻塞
锂电池测试箱----德国BINDER宾德的详细介绍

时序逻辑中的阻塞和非阻塞
阻塞与非阻塞通信的区别 阻塞和非阻塞应用场景
FutureTask是如何通过阻塞来获取到异步线程执行结果的呢?
Andorid系统中binder是什么意思
网络IO模型:阻塞与非阻塞






 工商网监
工商网监
评论