 哈希及哈希算法的介绍
哈希及哈希算法的介绍
聊到区块链的时候也少不了会听到“哈希”、“哈希函数”、“哈希算法”,是不是听得一头雾水?别急,这一讲我们来讲讲什么是哈希算法。
1
哈希是一种加密算法
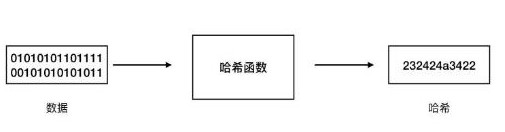
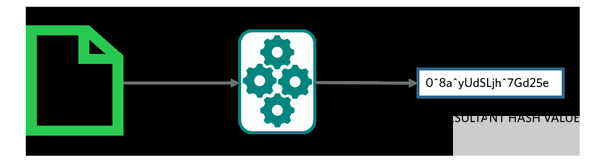
哈希函数(Hash Function),也称为散列函数或杂凑函数。哈希函数是一个公开函数,可以将任意长度的消息M映射成为一个长度较短且长度固定的值H(M),称H(M)为哈希值、散列值(Hash Value)、杂凑值或者消息摘要(Message Digest)。它是一种单向密码体制,即一个从明文到密文的不可逆映射,只有加密过程,没有解密过程。
它的函数表达式为:h=H(m)
无论输入是什么数字格式、文件有多大,输出都是固定长度的比特串。以比特币使用的Sh256算法为例,无论输入是什么数据文件,输出就是256bit。
每个bit就是一位0或者1,256bit就是256个0或者1二进制数字串,用16进制数字表示的话,就是多少位呢?
16等于2的4次方,所以每一位16进制数字可以代表4位bit。那么,256位bit用16进制数字表示,当然是256除以4等于64位。
于是你通常看到的哈希值,就是这样的了:
00740f40257a13bf03b40f54a9fe398c79a664bb21cfa2870ab07888b21eeba8。
这是从btc.com上随便拷贝的一个哈希值,不放心的话你可以数一下,是不是64位~
2
Hash函数的特点
Hash函数具有如下特点。
易压缩:对于任意大小的输入x,Hash值的长度很小,在实际应用中,函数H产生的Hash值其长度是固定的。
易计算:对于任意给定的消息,计算其Hash值比较容易。
单向性:对于给定的Hash值,要找到使得在计算上是不可行的,即求Hash的逆很困难。在给定某个哈希函数H和哈希值H(M)的情况下,得出M在计算上是不可行的。即从哈希输出无法倒推输入的原始数值。这是哈希函数安全性的基础。
抗碰撞性:理想的Hash函数是无碰撞的,但在实际算法的设计中很难做到这一点。
有两种抗碰撞性:一种是弱抗碰撞性,即对于给定的消息,要发现另一个消息,满足在计算上是不可行的;另一种是强抗碰撞性,即对于任意一对不同的消息,使得在计算上也是不可行的。
高灵敏性:这是从比特位角度出发的,指的是1比特位的输入变化会造成1/2的比特位发生变化。消息M的任何改变都会导致哈希值H(M)发生改变。即如果输入有微小不同,哈希运算后的输出一定不同。
3
哈希算法
把网址A,转换成数字1。网址B,转换成数字2。
一个网址X,转换成数字N,根据数字N作为下标,就可以快速地查找出网址X的信息。这个转换的过程就是哈希算法。
比如这里有一万首歌,给你一首新的歌X,要求你确认这首歌是否在那一万首歌之内。
无疑,将一万首歌一个一个比对非常慢。但如果存在一种方式,能将一万首歌的每首数据浓缩到一个数字(称为哈希码)中,于是得到一万个数字,那么用同样的算法计算新的歌X的编码,看看歌X的编码是否在之前那一万个数字中,就能知道歌X是否在那一万首歌中。
作为例子,如果要你组织那一万首歌,一个简单的哈希算法就是让歌曲所占硬盘的字节数作为哈希码。这样的话,你可以让一万首歌“按照大小排序”,然后遇到一首新的歌,只要看看新的歌的字节数是否和已有的一万首歌中的某一首的字节数相同,就知道新的歌是否在那一万首歌之内了。
一个可靠的哈希算法,应该满足:
对于给定的数据M,很容易算出哈希值X=F(M);
根据X很难反算出M;
很难找到M和N使得F(N)=F(M)
前面提到哈希函数具有抗碰撞性,碰撞性就是指有人实现找出一奇一偶使得哈希结果一致,但这在计算上是不可行的。
首先,把大空间的消息压缩到小空间上,碰撞肯定是存在的。假设哈希值长度固定为256位,如果顺序取1,2,…2^256+1, 这2^256+1个输入值,逐一计算其哈希值,肯定能找到两个输入值使得其哈希值相同。但不要高兴的太早,因为你得有时间把它算出来,才是你的。
根据生日悖论,如果随机挑选其中的2^128+1输入,则有99.8%的概率发现至少一对碰撞输入。那么对于哈希值长度为256位的哈希函数,平均需要完成2^128次哈希计算,才能找到碰撞对。如果计算机每秒进行10000次哈希计算,需要约10^27年才能完成2^128次哈希计算。在区块链中,哈希函数的抗碰撞性用来做区块和交易的完整性验证,一有篡改就能被识别出来。
前面提到挖矿需要矿工通过随机数不断计算得到小于给定难度值的数值。难度值(difficulty)是矿工们挖矿时的重要参考指标,它决定了矿工大约需要经过多少次哈希运算才能产生一个合法的区块。比特币的区块大约每10分钟生成一个,为了让新区块的产生基本保持这个速率,难度值必须根据全网算力的变化进行调整。
哈希函数通过调整难度值来确保每个区块挖出的时间都大约在10分钟,哈希函数计算的难度值对保证区块链系统的安全意义重大。正如美国的几位计算机科学家在共同所著的书中所写的:“哈希密码是密码学中的瑞士军刀,它们在众多各具特色的应用中找到了一席之地,为了保证安全,不同的应用会要求不同的哈希函数特点。事实已经证明,要确定一系列哈希函数以全面达成可证安全极度困难。”
工作量证明需要有一个目标值。比特币工作量证明的目标值(target)的计算公式如下:
目标值=最大目标值 / 难度值
其中,最大目标值为一个恒定值:
0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
目标值的大小与难度值成反比。比特币工作量证明的达成就是矿工计算出来的区块哈希值必须小于目标值。
我们也可以简单理解成,比特币工作量证明的过程,就是通过不停地变换区块头(即尝试不同的随机值)作为输入进行SHA256哈希运算,找出一个特定格式哈希值的过程(即要求有一定数量的前导0)。而要求的前导0的个数越多,代表难度越大。
4
举个栗子帮助理解
▌场景一、小星和阿呆在篮球场
小星:阿呆,你是不是口渴了,你要不要去买水喝,顺便帮我买一瓶哈。
阿呆:呵呵,你的小心思我还不知道,你自己也口渴了吧,你去,我不去。
小星:哎哎,咱们不扯这些没用的,来抛硬币,好不好,正面你去,反面我去,公平吧,如何?
阿呆:好吧。
………
▌场景二、小星与阿呆即时聊天中
阿呆:小星,今天来我家玩,来的路上,有一家披萨店,很好吃,顺便带一点哈。
小星:哦,要不你来我家玩吧,你顺便带上披萨。
阿呆:小星,你竟然都这么说了,看来只能抛硬币解决了。
小星:丫的,这个怎么抛,我怎么知道你有没有搞鬼。
阿呆:嗯,那到也是,要不这样。
1.考虑对结果加密
阿呆:我心中想一个数,假设为A,然后A在乘以一个数B,得到结果C。A是我的密钥,我把结果C告诉你。你来猜A是奇数还是偶数,猜中了,算你赢。
小星:这不行,如果你告诉我C是12,我猜A是奇数,你可以说A是4,B是3。我猜A是偶数,你可以说A是3,B是4。要不你告诉我C是多少的时候,也告诉我B是多少。
阿呆:那这不行,告诉你C和B,不等于告诉你A是多少了,还猜个屁。不行得换个方式。
2.不可逆加密
阿呆:小星,你看这样可以不,我想一个A,经过下面的过程:
1.A+123=B2.B^2=C3.取C中第2~4位数,组成一个3位数D4.D/12的结果求余数,得到E
阿呆:我把E和上述计算方式都告诉你,你猜A是奇数还是偶数,然后我告诉你A是多少,你可以按上述的计算过程来验证我是否有说谎。
小星:嗯,我想想,假如阿呆你想的A为5,那么:
5+123=128128^2=16384D=638 E=638mod12=53
(mod表示除法的求余数)
小星:咦,厉害了,一个A值对应一个唯一的E值,根据E还推算不出来A。你太贱了,好吧,这个算公平,谁撒谎都能被识别出来。
小星:阿呆,你出题吧 ……
这种丢掉一部分信息的加密方式称为“单向加密”,也叫哈希算法。
5
常见的哈希算法
1、SHA-1算法
SHA-1的输入是最大长度小于264位的消息,输入消息以512位的分组为单位进行处理,输出是160位的消息摘要。SHA-1具有实现速度高、容易实现、应用范围广等优点,其算法描述如下。
对输入的消息进行填充:经过填充后,消息的长度模512应与448同余。填充的方式为第一位是1,余下各位都为0。再将消息被填充前的长度以big-endian的方式附加在上一步留下的最后64位中。该步骤是必须的,即使消息的长度已经是所希望的长度。填充的长度范围是1到512。
初始化缓冲区:可以用160位来存放Hash函数的初始变量、中间摘要及最终摘要,但首先必须进行初始化,对每个32位的初始变量赋值,即:

进入消息处理主循环,处理消息块:一次处理512位的消息块,总共进行4轮处理,每轮进行20次操作,如图所示。这4轮处理具有类似的结构,但每轮所使用的辅助函数和常数都各不相同。每轮的输入均为当前处理的消息分组和缓冲区的当前值A、B、C、D、E,输出仍放在缓冲区以替代旧的A、B、C、D、E的值。第四轮的输出再与第一轮的输入CVq相加,以产生CVq+1,其中加法是缓冲区5个字CVq中的每个字与中相应的字模232相加。
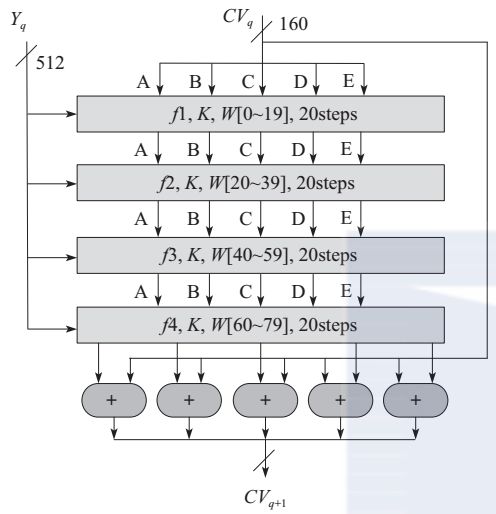
图 单个512位消息块的处理流程
输出:所有的消息分组都被处理完之后,最后一个分组的输出即为得到的消息摘要值。
SHA-1的步函数如图所示,它是SHA-1最为重要的函数,也是SHA-1中最关键的部件。
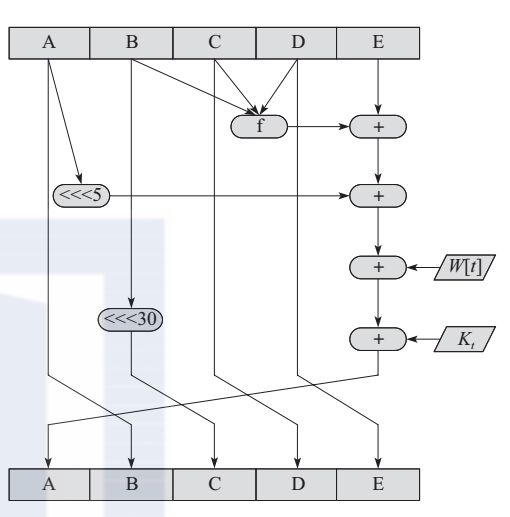
图 SHA-1的步函数
SHA-1每运行一次步函数,A、B、C、D的值就会依次赋值给B、C、D、E这几个寄存器。同时,A、B、C、D、E的输入值、常数和子消息块在经过步函数运算后就会赋值给A。

其中,t是步数,0≤t≤79,Wt是由当前512位长的分组导出的一个32位的字,Kt是加法常量。
基本逻辑函数f的输入是3个32位的字,输出是一个32位的字,其函数表示如下。
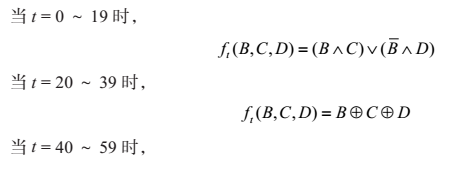

对于每个输入分组导出的消息分组wt,前16个消息字wt(0≤t≤15)即为消息输入分组对应的16个32位字,其余wt(0≤t≤79)可按如下公式得到:
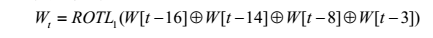
其中,ROTLs表示左循环移位s位,如图所示。
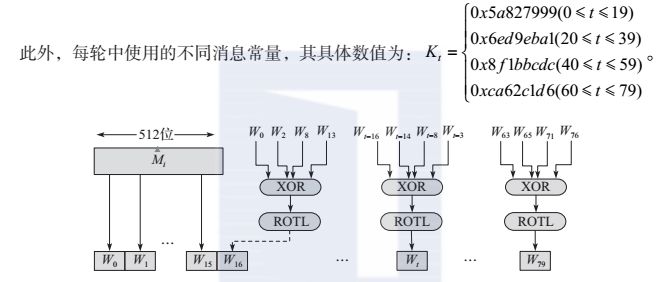
图 SHA-1的80个消息字的产生过程
2、SHA-2算法
SHA-2系列Hash算法,其输出长度可取SHA-2系列哈希算法的输出长度可取224位、256位、384位、512位,分别对应SHA-224、SHA-256、SHA-384、SHA-512。它还包含另外两个算法:SHA-512/224、SHA-512/256。比之前的Hash算法具有更强的安全强度和更灵活的输出长度,其中SHA-256是常用的算法。下面将对前四种算法进行简单描述。
SHA-256算法
SHA-256算法的输入是最大长度小于264位的消息,输出是256位的消息摘要,输入消息以512位的分组为单位进行处理。算法描述如下。
(1)消息的填充
添加一个“1”和若干个“0”使其长度模512与448同余。在消息后附加64位的长度块,其值为填充前消息的长度。从而产生长度为512整数倍的消息分组,填充后消息的长度最多为264位。
(2)初始化链接变量
链接变量的中间结果和最终结果存储于256位的缓冲区中,缓冲区用8个32位的寄存器A、B、C、D、E、F、G和H表示,输出仍放在缓冲区以代替旧的A、B、C、D、E、F、G、H。首先要对链接变量进行初始化,初始链接变量存储于8个寄存器A、B、C、D、E、F、G和H中:

初始链接变量是取自前8个素数(2、3、5、7、11、13、17、19)的平方根的小数部分其二进制表示的前32位。
(3)处理主循环模块
消息块是以512位分组为单位进行处理的,要进行64步循环操作(如图所示)。每一轮的输入均为当前处理的消息分组和得到的上一轮输出的256位缓冲区A、B、C、D、E、F、G、H的值。每一步中均采用了不同的消息字和常数,下面将给出它们的获取方法。
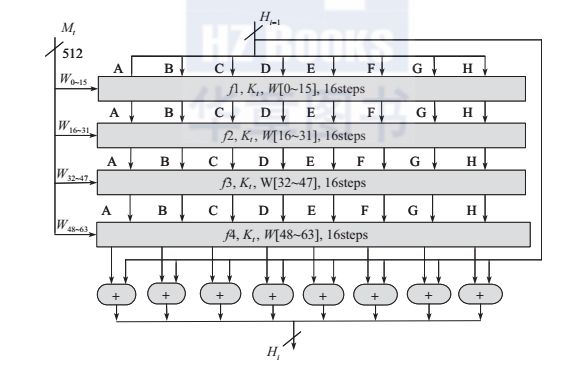
图SHA-256的压缩函数
(4)得出最终的Hash值
所有512位的消息块分组都处理完以后,最后一个分组处理后得到的结果即为最终输出的256位的消息摘要。
步函数是SHA-256中最为重要的函数,也是SHA-256中最关键的部件。其运算过程如图所示。
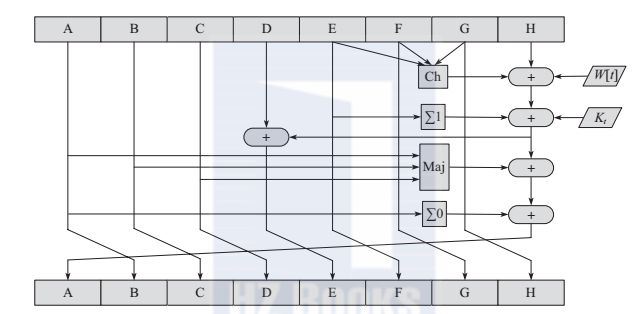
图SHA-256的步函数

根据T1、T2的值,对寄存器A、E进行更新。A、B、C、E、F、G的输入值则依次赋值给B、C、D、F、G、H。


Kt的获取方法是取前64个素数(2,3,5,7,……)立方根的小数部分,将其转换为二进制,然后取这64个数的前64位作为Kt。其作用是提供了64位随机串集合以消除输入数据里的任何规则性。
对于每个输入分组导出的消息分组Wt,前16个消息字Wt(0≤t≤15)直接按照消息输入分组对应的16个32位字,其他的则按照如下公式来计算得出:
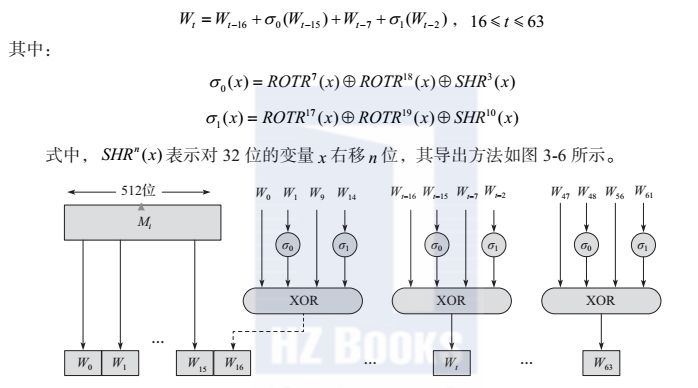
图SHA-256的64个消息字的生成过程
SHA-512算法
SHA-512是SHA-2中安全性能较高的算法,主要由明文填充、消息扩展函数变换和随机数变换等部分组成,初始值和中间计算结果由8个64位的移位寄存器组成。该算法允许输入的最大长度是2128位,并产生一个512位的消息摘要,输入消息被分成若干个1024位的块进行处理,具体参数为:消息摘要长度为512位;消息长度小于2128位;消息块大小为1024位;消息字大小为64位;步骤数为80步。下图显示了处理消息、输出消息摘要的整个过程,该过程的具体步骤如下。
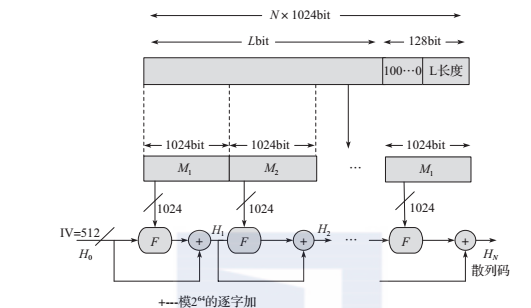
图SHA-512的整体结构
消息填充:填充一个“1”和若干个“0”,使其长度模1024与896同余,填充位数为0-1023,填充前消息的长度以一个128位的字段附加到填充消息的后面,其值为填充前消息的长度。
链接变量初始化:链接变量的中间结果和最终结果都存储于512位的缓冲区中,缓冲区用8个64位的寄存器A、B、C、D、E、F、G、H表示。初始链接变量也存储于8个寄存器A、B、C、D、E、F、G、H中,其值为:

初始链接变量采用big-endian方式存储,即字的最高有效字节存储于低地址位置。初始链接变量取自前8个素数的平方根的小数部分其二进制表示的前64位。
主循环操作:以1024位的分组为单位对消息进行处理,要进行80步循环操作。每一次迭代都把512位缓冲区的值A、B、C、D、E、F、G、H作为输入,其值取自上一次迭代压缩的计算结果,每一步计算中均采用了不同的消息字和常数。
计算最终的Hash值:消息的所有N个1024位的分组都处理完毕之后,第N次迭代压缩输出的512位链接变量即为最终的Hash值。
步函数是SHA-512中最关键的部件,其运算过程类似SHA-256。每一步的计算方程如下所示,B、C、D、F、G、H的更新值分别是A、B、C、E、F、G的输入状态值,同时生成两个临时变量用于更新A、E寄存器。

对于80步操作中的每一步t,使用一个64位的消息字Wt,其值由当前被处理的1024位消息分组Mi导出,导出方法如图所示。前16个消息字Wt(0≤t≤15)分别对应消息输入分组之后的16个32位字,其他的则按照如下公式来计算得出:
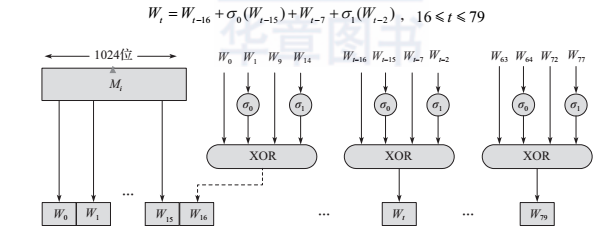
图SHA-512的80个消息字生成的过程
其中,
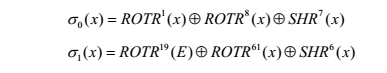
式中,ROTRn(X)表示对64位的变量x循环右移n位,SHRn(X)表示对64位的变量x右移n位。
从图可以看出,在前16步处理中,Wt的值等于消息分组中相对应的64位字,而余下的64步操作中,其值是由前面的4个值计算得到的,4个值中的两个要进行移位和循环移位操作。
Kt的获取方法是取前80个素数(2,3,5,7,……)立方根的小数部分,将其转换为二进制,然后取这80个数的前64位作为Kt,其作用是提供了64位随机串集合以消除输入数据里的任何规则性。
SHA-224与SHA-384
SHA-256和SHA-512是很新的Hash函数,前者定义一个字为32位,后者则定义一个字为64位。实际上二者的结构是相同的,只是在循环运行的次数、使用常数上有所差异。SHA-224及SHA-384则是前述两种Hash函数的截短型,它们利用不同的初始值做计算。
SHA-224的输入消息长度跟SHA-256的也相同,也是小于264位,其分组的大小也是512位,其处理流程跟SHA-256也基本一致,但是存在如下两个不同的地方。
SHA-224的消息摘要取自A、B、C、D、E、F、G共7个寄存器的比特字,而SHA-256的消息摘要取自A、B、C、D、E、F、G、H共8个寄存器的32比特字。
SHA-224的初始链接变量与SHA-256的初始链接变量不同,它采用高端格式存储,但其初始链接变量的获取方法是取前第9至16个素数(23、29、31、37、41、43、47、53)的平方根的小数部分其二进制表示的第二个32位,SHA-224的初始链接变量如下:
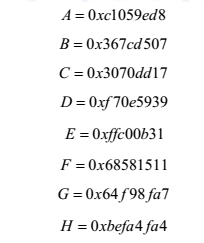
SHA-224的详细计算步骤与SHA-256一致。
SHA-384的输入消息长度跟SHA-512相同,也是小于2128位,而且其分组的大小也是1024位,处理流程跟SHA-512也基本一致,但是也有如下两处不同的地方。
SHA-384的384位的消息摘要取自A、B、C、D、E、F共6个64比特字,而SHA-512的消息摘要取自A、B、C、D、E、F、G、H共8个64比特字。
SHA-384的初始链接变量与SHA-512的初始链接变量不同,它也采用高端格式存储,但其初始链接变量的获取方法是取前9至16个素数(23、29、31、37、41、43、47、53)的平方根的小数部分其二进制表示的前64位,SHA-384的初始链接变量如下:

SHA-384的详细计算步骤与SHA-512的相同。
3、SHA-3算法
SHA-3算法整体采用Sponge结构,分为吸收和榨取两个阶段。SHA-3的核心置换f作用在5×5×64的三维矩阵上。整个f共有24轮,每轮包括5个环节θ、ρ、π、χ、τ。算法的5个环节分别作用于三维矩阵的不同维度之上。θ环节是作用在列上的线性运算;ρ环节是作用在每一道上的线性运算,将每一道上的64比特进行循环移位操作;π环节是将每道上的元素整体移到另一道上的线性运算;χ环节是作用在每一行上的非线性运算,相当于将每一行上的5比特替换为另一个5比特;τ环节是加常数环节。
目前,公开文献对SHA-3算法的安全性分析主要是从以下几个方面来展开的。
对SHA-3算法的碰撞攻击、原像攻击和第二原像攻击。
对SHA-3算法核心置换的分析,这类分析主要针对算法置换与随机置换的区分来展开。
对SHA-3算法的差分特性进行展开,主要研究的是SHA-3置换的高概率差分链,并构筑差分区分器。
Keccak算法的立体加密思想和海绵结构,使SHA-3优于SHA-2,甚至AES。Sponge函数可建立从任意长度输入到任意长度输出的映射。
4、RIPEMD160算法
RIPEMD(RACE Integrity Primitives Evaluation Message Digest),即RACE原始完整性校验消息摘要。RIPEMD使用MD4的设计原理,并针对MD4的算法缺陷进行改进,1996年首次发布RIPEMD-128版本,它在性能上与SHA-1相类似。
RIPEMD-160是对RIPEMD-128的改进,并且是RIPEMD中最常见的版本。RIPEMD-160输出160位的Hash值,对160位Hash函数的暴力碰撞搜索攻击需要280次计算,其计算强度大大提高。RIPEMD-160的设计充分吸取了MD4、MD5、RIPEMD-128的一些性能,使其具有更好的抗强碰撞能力。它旨在替代128位Hash函数MD4、MD5和RIPEMD。
RIPEMD-160使用160位的缓存区来存放算法的中间结果和最终的Hash值。这个缓存区由5个32位的寄存器A、B、C、D、E构成。寄存器的初始值如下所示:

数据存储时采用低位字节存放在低地址上的形式。
处理算法的核心是一个有10个循环的压缩函数模块,其中每个循环由16个处理步骤组成。在每个循环中使用不同的原始逻辑函数,算法的处理分为两种不同的情况,在这两种情况下,分别以相反的顺序使用5个原始逻辑函数。每一个循环都以当前分组的消息字和160位的缓存值A、B、C、D、E为输入得到新的值。每个循环使用一个额外的常数,在最后一个循环结束后,两种情况的计算结果A、B、C、D、E和A′、B′、C′、D′、E′及链接变量的初始值经过一次相加运算产生最终的输出。对所有的512位的分组处理完成之后,最终产生的160位输出即为消息摘要。
除了128位和160位的版本之外,RIPEMD算法也存在256位和320位的版本,它们共同构成RIPEMD家族的四个成员:RIPEMD-128、RIPEMD-160、RIPEMD-256、RIPEMD-320。其中128位版本的安全性已经受到质疑,256位和320位版本减少了意外碰撞的可能性,但是相比于RIPEMD-128和RIPEMD-160,它们不具有较高水平的安全性,因为他们只是在128位和160位的基础上,修改了初始参数和s-box来达到输出为256位和320位的目的。
-
哈希函数
+关注
关注
0文章
43浏览量
9446 -
哈希算法
+关注
关注
1文章
56浏览量
10744
原文标题:据说,80%的人都搞不懂哈希算法
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于双字哈希结构的匹配算法
哈希算法的基本含义与分类
什么是哈希算法用途是什么
哈希算法SHA-512的基本概念及特性解析
什么是哈希算法它的作用是什么
哈希算法的前世、今生和未来
基于哈希存储与事务加权的Apriori算法
基于双峰高斯分布的深度哈希检索算法

区块哈希游戏开发逻辑(上链)哈希竞猜游戏开发
哈希算法是什么,哈希游戏系统开发方案
哈希是什么,常见的哈希算法有哪些
区块哈希竞猜游戏系统开发加密哈希算法概述





 工商网监
工商网监
评论