 窥一窥深度学习这一黑盒子
窥一窥深度学习这一黑盒子
编者按:据传宋徽宗赵佶曾以“深山藏古寺”为题命人作画,夺魁的画作,画崇山峻岭之中,一股清泉飞流直下,跳珠溅玉,泉边有位老态龙钟的和尚,正舀着泉水倒进桶里。
这幅画的妙处在于,从“打水的老和尚”这一已知语义信息提取出“古寺”这一隐含信息,从而使得该画切题应景。而在计算机视觉领域,这一典故正展示了结构化分析中的隐含信息传递,对于画面内容理解的重要性。
近年来,深度学习取得了斐然的成绩,然而自其提出之日起,“黑盒智能”、“可解释性差”等质疑之声即不绝于耳,“黑盒智能”,意味着无法对结果作出保证,并极易陷入“自信的错误”这一致命问题。因此,世界上顶级实验室都在思考“why"这一问题,并尝试增强算法的可解释性,以打开深度学习这一黑盒子。
今天,来自悉尼大学的欧阳万里教授,将从物体之间的相关性出发,利用结构化建模,尝试在图像理解领域,窥一窥深度学习这一黑盒子。


本次报告中,我介绍一下我在香港中文大学以及在悉尼大学和很多老师、学生一起合作的工作。
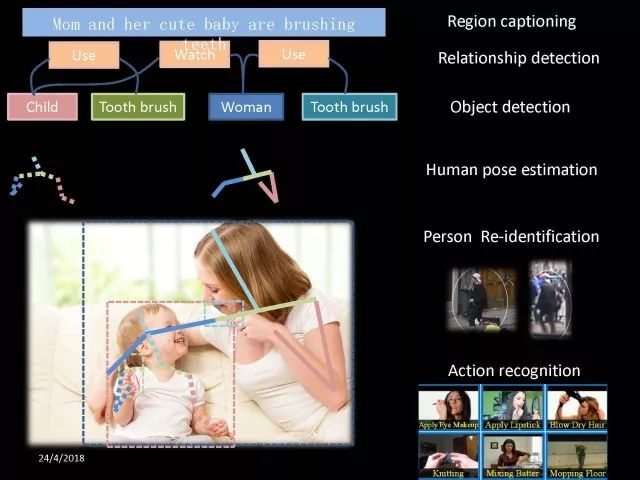
首先我们来了解一下检测和人体姿态识别相关的工作。给定一张图像,确定感兴趣的物体在图片中的位置,比如说这位女士的牙刷,这就是物体检测工作。目标检测进一步往上分析,就是关系检测。得到关系之后,可以进一步做更多语义的理解,比如用句子来描述图片中某个区域它的语义,如说这位妈妈和可爱的小孩在刷牙。物体检测后可以逐步把语义信息往上走,也可以对感兴趣物体进行深入分析,比如说可以对人体关键点进行定位,也就是人体姿态识别。有了这些物体检测、姿态检测以后可以分析行人,分析人的动作。

关键点定位识别任务具有许多难点,例如说人可能穿不同颜色衣服,会被遮挡,人身体变动灵活,会由于形变产生剧烈视觉信息变化。
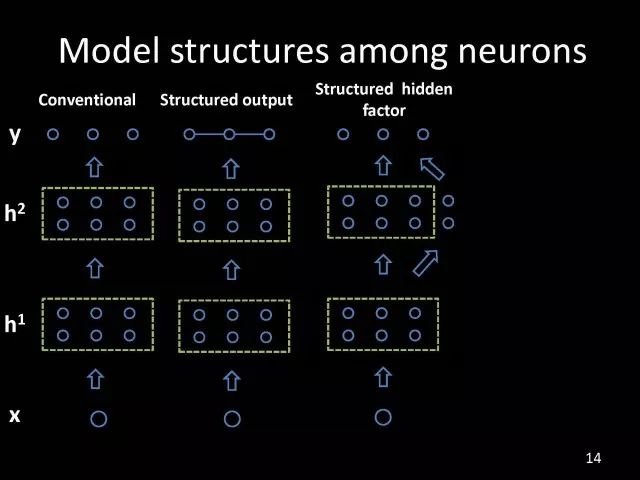
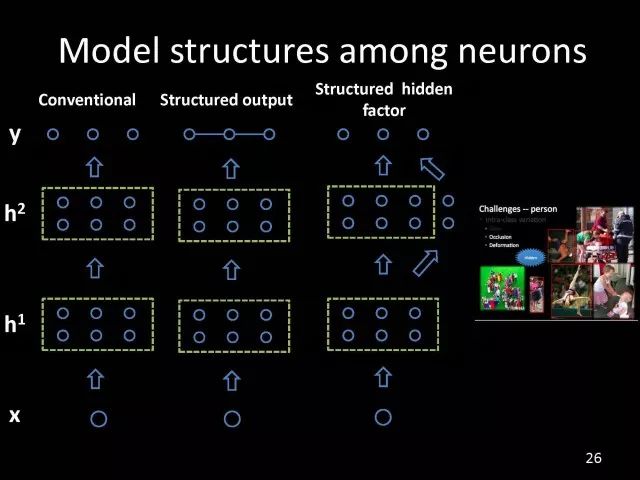
为了处理好视觉信息,我们引入结构化学习,学习输出结构化的信息在我们打开深度学习黑盒子的过程中是很重要的一环。我们期望利用对问题的理解,帮助我们在深度学习能达到的结果之上得到更多的改善。
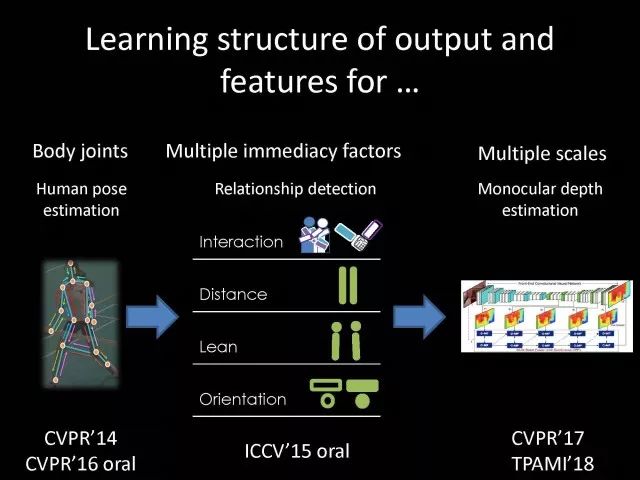
对于结构化输出的建模,我们有一些工作。比如在人体姿态识别任务中,对人体关键点之间的空间结构关系可以进行建模。对于人与人之间的交互,可能会有很多交互因素,比如说有交互动作,具体到拥抱、手拉手。其它交互因素,比如说人与人之间的距离,倾斜度、朝向等这些因素,他们之间也会有位置关系,所以可以将它们进行结构化建模。基于单目摄像头得到深度信息预测任务,可以利用卷积网络帮我们在不同分辨率特征中得到不同对于深度信息的预测,它们之间也有很多相关性,可以对它们进行结构化建模。最新工作考虑不同的模态,在跨摄像头寻人信息中对比两个图片是不是同一个人,对于人分割多值信息可以有结构化信息帮助我们进行建模。
在进一步打开深度学习黑盒子的情况下,我们可以引入标签或者输出所不具备的因素,把对于因素中特性的建模和深度特征的学习继续联合学习。具体例子就是物体检测,我们会遇到遮挡以及人的形变产生的变化,这些因素都是隐含的,标签中只有一个矩形框,没有这些信息。如果能够设计需要非常少参数的方法能够把隐含因素推理到,其实就能够帮助到模型学到更好的特征,并实现更好的结果。
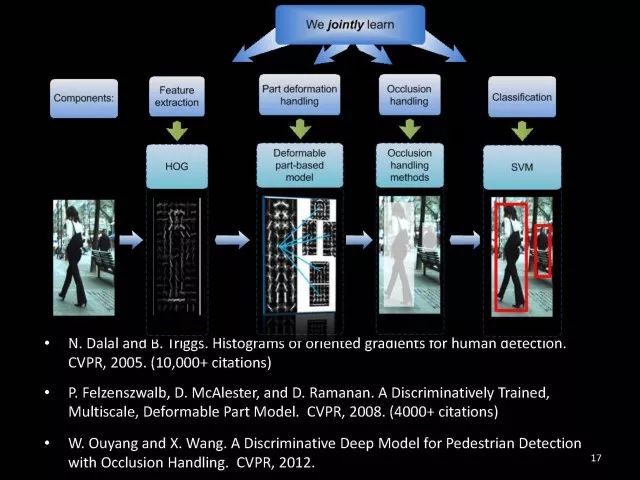
例如说有一幅图像,我们可以利用深度学习模型或者已有手工设计的特征对它进行处理。这个任务中,一个隐含的因素是形变,我们可以引入处理形变和学习形变的模型,一个著名模型是deformable part model。另一个隐含因素是遮挡,比如说在这幅图中这个人腿就被椅子挡住了。如果能够对人体的遮挡进行推理,能够把一些被遮挡的部分找出来,不要用被挡住的椅子学习人腿的视觉形状。如果能够得到这样的隐含因素可以进一步提高检测效果。最后是进行分类。这些模块之间的学习都是固定住前面一部分的参数,学习最后的参数,每个模块之间缺乏通信。我们可以设计联合深度学习模型,将这些模块联合起来,在每次参数学习中,都能够进行非常好的通信,从而使各模块通过互相沟通学习到更好的模型以提高准确率。
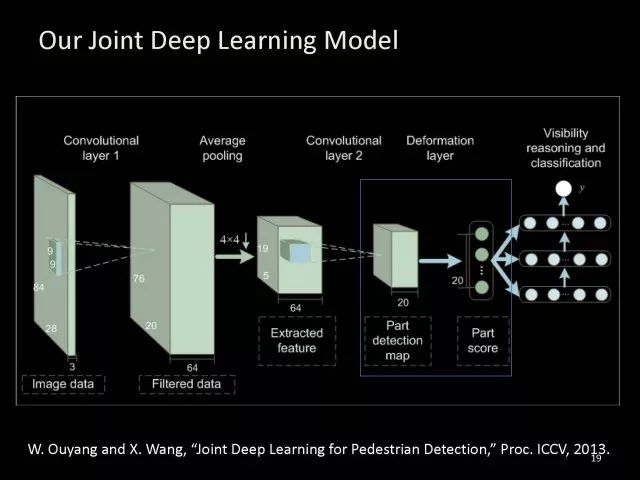
这是我们设计基本模型,首先利用卷积网络帮我们学习到特征,有了特征以后就可以利用形变层((deformation layer))学习身体各个部分的形变。
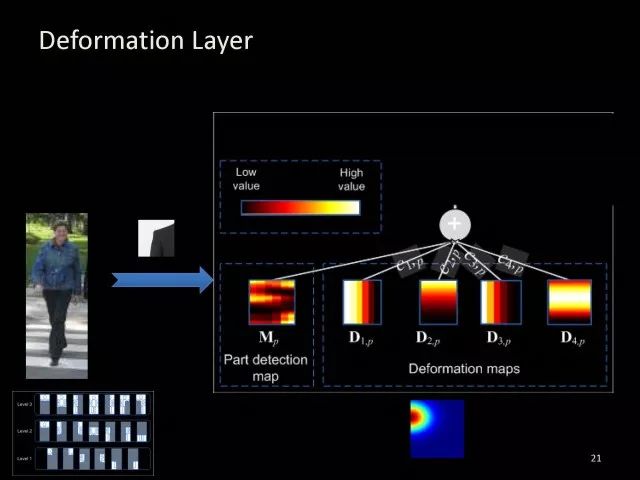
假设有一个检测器可以检测人的肩膀在图片中的位置,其中一个检测器的例子就是这样一个肩膀,如果把这个肩膀检测器在图片中进行滑动的匹配将会得到这样的响应图谱。在没有肩膀的地方会有我们不想要的高的响应,如果使用这些区域学习人的肩膀长什么样,特征学不好,肩膀的检测器也学不好。为了处理好这个问题,我们可以利用形变的特性。我们可以考虑到人的肩膀不会从对应的位置跑到人的右下角,所以我们设计形变的图谱,自动学习人的形变特性。将这种概率化的描述转化成图谱,进行叠加就会得到修正以后的图谱。如果利用修正以后的图谱进行检测,可以准确定位形变物体到底在哪里,相对于特征和检测学习就会得到更好的结果。
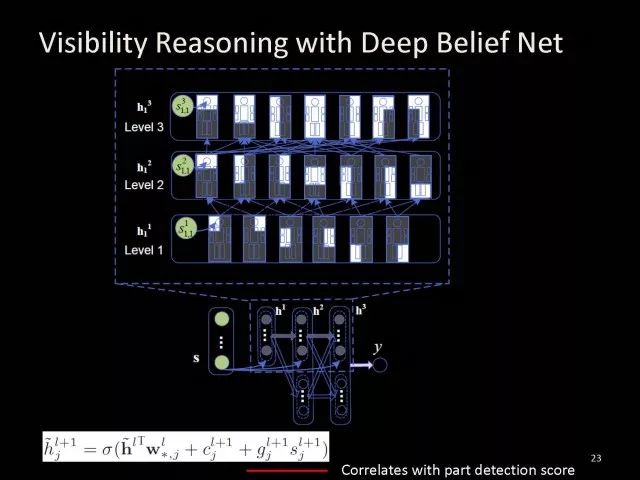
另一方面,人的身体各个部位会被遮挡,会涉及不同大小身体部位的检测器。比如说关于人的左腿和右腿的检测器,如果两个检测器都被遮挡,两条腿会一起被遮挡,所以不同检测器它们之间关系可以用deep belief net来学习。
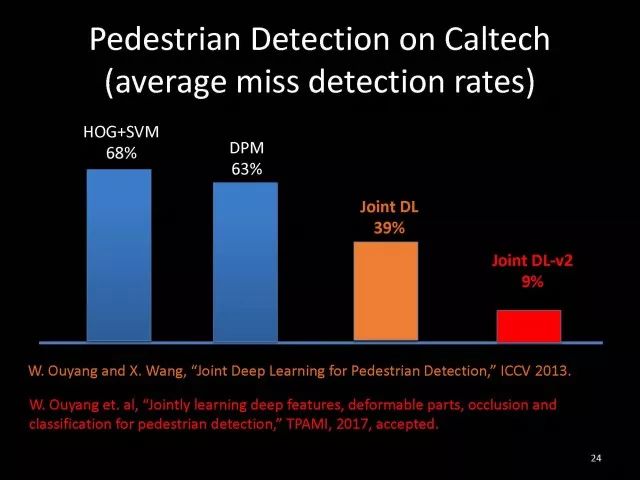
我们进行了一些实验,在2013年时最大的行人检测数据库上,使用手工设计的特征再加上已有的分类器错误率为68%。如果处理好形变隐含的因素可以降到63%,如果将特征学习以及形变和遮挡进行联合学习可以将错误率降到39%。如果进一步使用更好深度学习的方式,最近的工作错误率可以降低到9%。
论文相关代码在如下地址:
http://www.ee.cuhk.edu.hk/~wlouyang/projects/ouyangWiccv13Joint/index.html.

上面所说的我们对于形变和遮挡这两个隐含因素的学习主要用在单个行人检测工作中,我们将它进行拓展。第一个拓展是把形变的学习拓展到普适的物体检测中,我们开发了一个新的形变学习模型,这个工作2017发表在PAMI,连续几个月都是TPAMI最受欢迎的文章之一。
另外一个扩展是将对于单个行人的可见性与不可见性的推理运用到两个行人之中,互相遮挡的情况下,他们之间可见性有相融和不相融的关系,从而提高互相遮挡情况下的效果。
上面介绍的是我们利用隐含因素具体研究形变以及遮挡两个隐含因素,对这两个隐含因素参数的学习和深度学习中特征学习进行联合学习,从而提高最终我们具体任务的效果。
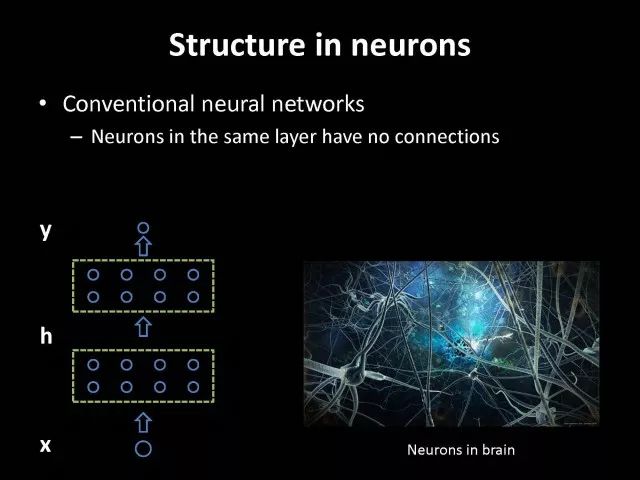
为了进一步的打开深度学习的黑盒子,我们考虑特征之间的结构化建模。它的动机是来自于另外一个观察。全连接网络或者卷积网络它们有一个共同特性,在同一层中神经元是没有连接的,但人脑并不是这样,在人脑中同一层神经元之间是有连接的。

关于深度学习,研究者得到最多的信息就是要设计很好的学习方法以及很好模型设计方式,使得模型变得越来越深。是不是把模型变得更深就是我们唯一的出路呢?另外一个问题是做视觉研究者对于问题的观察以及理解是不是也会有帮助?为了回答这个问题,我们设计了GBD-Net。GBD-NET利用上下文信息,帮助我们识别所感兴趣的物体是什么。

计算机视觉研究者很早就知道上下文信息对于识别物体有帮助。有了深度学习模型以后怎样考虑上下文信息呢?我们考虑的是可以学习不同上下文信息的特征之间的关系。比如说,现在有一个特征对应的是兔子的耳朵,它是比较少的上下文的信息,可以推测到下面应该有兔子的头。因此兔子耳朵这样比较少上下文的特征和兔子头这个比较多的上下文特征,反之亦然。由此可见,不同上下文信息的特征之间可以互相验证。
而另外一方面如果看见一个兔子耳朵并不一定下面就有兔子的头,如上图中的反例。在这种情况下,如果我们看见下面不是兔子的头,而是一个人的脸,我们希望的是让这个兔子的耳朵不要传递信息给兔子的头。因此信息是需要传递的,但是信息的传递是需要受到控制的。
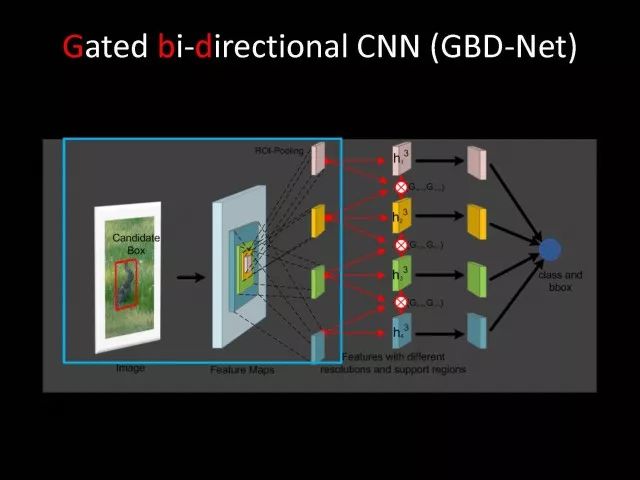
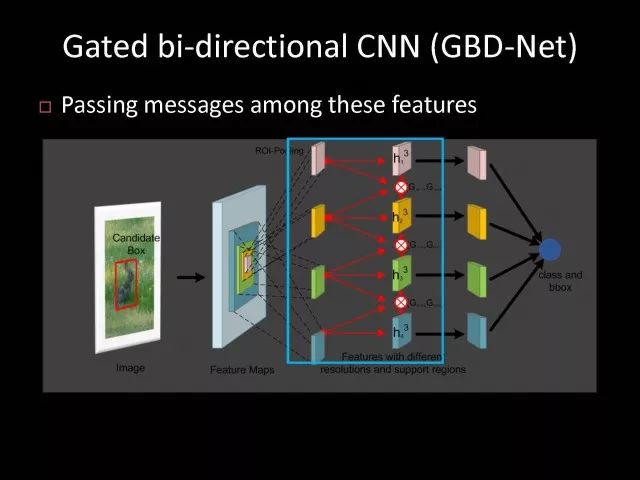
基于已有的检测网络基础上我们设计了GBD-Net。它利用已有网络结构得到不同上下文特征。有了不同上下文信息特征以后,开始进行信息传递。

可以把信息从上往下传,也就是让上下文信息比较少的特征传递给上下文信息比较多的特征。也可以进行反向的传递,就是把上下文信息比较多的特征传递给上下文信息比较少的特征。我们将两组通过不同方向传递的特征会进行结合,也引入一个函数来帮助我们控制信息的传递。
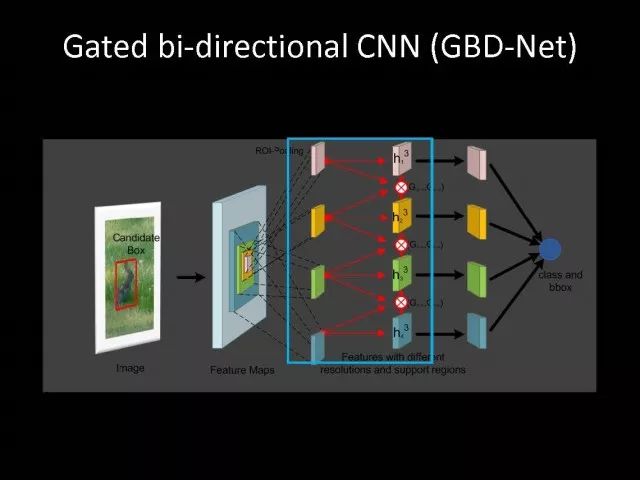
经过信息传递以后,这些特征将会被得到修正,我们利用修正特征帮助我们做最终检测的任务。
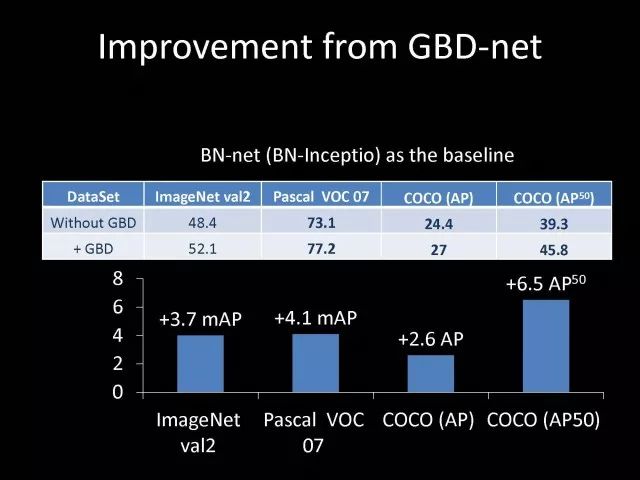
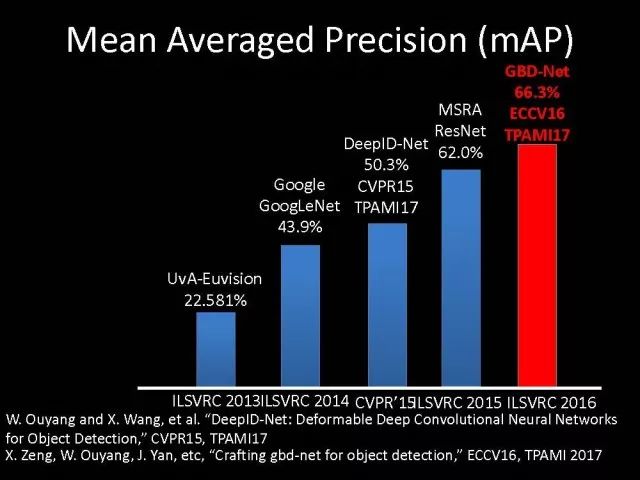
实验发现在不同的数据库和不同网络结构中,使用我们这样的特征之间传递信息的方法,效果都可以得到很好的改善。我们利用这个方法参加了2016年的竞赛,在静态物体检测和动态视频物体检测跟踪中我们都取得第一名。

对GBD-Net进行总结。第一点,特征仍然是重要的。第二点,视觉工作者基于专业知识对于问题的观察和分析同样重要。第三点,我们使用深度学习,把它当做一个工具来帮助将特征之间的关系进行建模。具体而言,我们设计的GBD-Net是在不同上下文特征之间进行信息传递。论文相关代码可以扫描二维码。
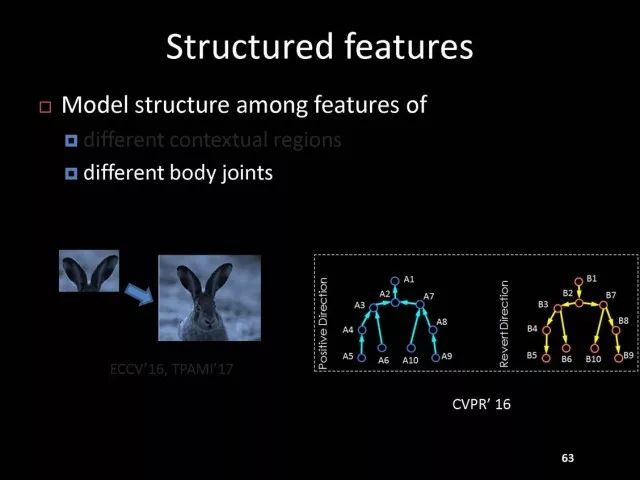
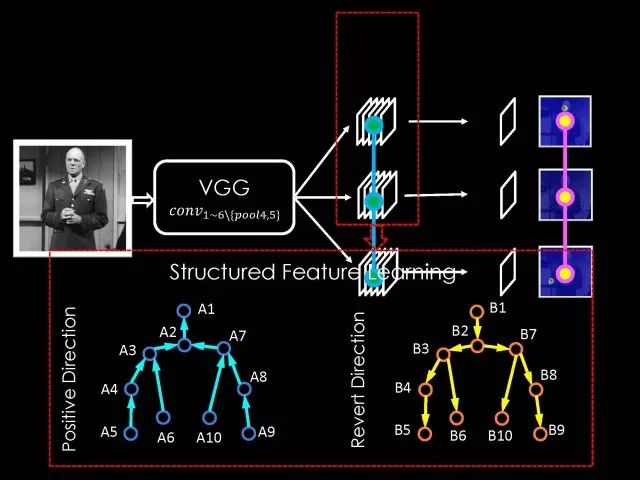
刚才所做的只是在物体检测中,是不是这个特征之间的结构建模只是适用于物体检测呢?其实不是这样的,它在其他很多工作中也是有效的。比如说在人体姿态识别中,我们考虑每一个人体的关键点都是一个特征,在这些特征中可以进行信息传递。可以考虑每个关键点分别对应的一组特征,有了对应特征以后可以把对应特征认为是结点,有了结点以后可以考虑人体关键点树型结构,在树形结构上的各个结点之间进行信息传递。论文相关代码在:
https://github.com/chuxiaoselena/StructuredFeature.

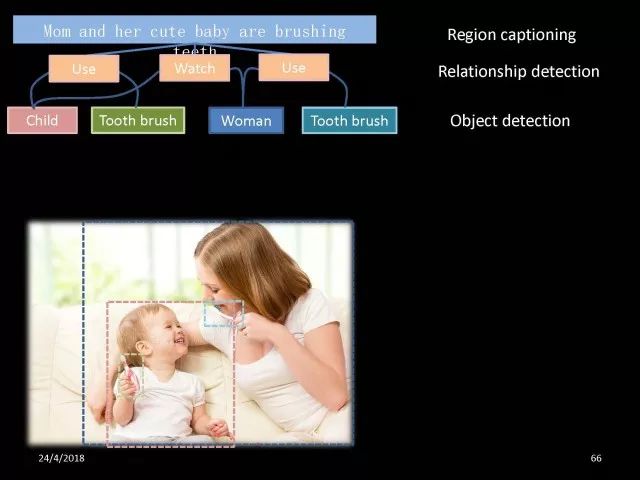
刚才我们所介绍的仍然是具有类似语义信息的这样一些特征,其实这样的特征并不一定要具有相同语义。在具体工作中,可以考虑这些特征可以具有不同的语义信息。比如说物体检测中可能有专门对应每一个物体的特征,比如说这位女士自己的特征,对于牙刷也有它自己的特征,小孩和他的牙刷都有自己的特征,往上走不同物体之间关系也有一组专门识别物体关系的特征。继续上走,每个语句也有自己的特征。如果考虑每一个特征都是一个结点的话,仍然可以利用它们之间的关系,通用边进行信息传递,最终提高这三个不同任务的效果。

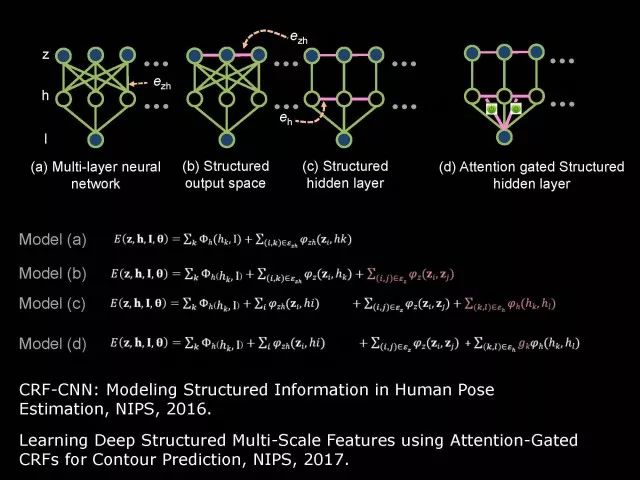
上面介绍利用结构化信息传递在不同任务进行结构化信息建模。它面临的问题是信息传递没有任何理论指导,我们只是通过观察来设计并通过实验发现这样做有效。为了解决这个问题,我们引入统计模型。具体而言,我们引入条件随机场,帮助我们进行网络结构设计。网络结构符合这样的统计模型。在具体工作中,我们对特征之间的信息传递利用条件随机场进行建模,也对加入门限控制的特征信息传递利用条件随机场进行建模。
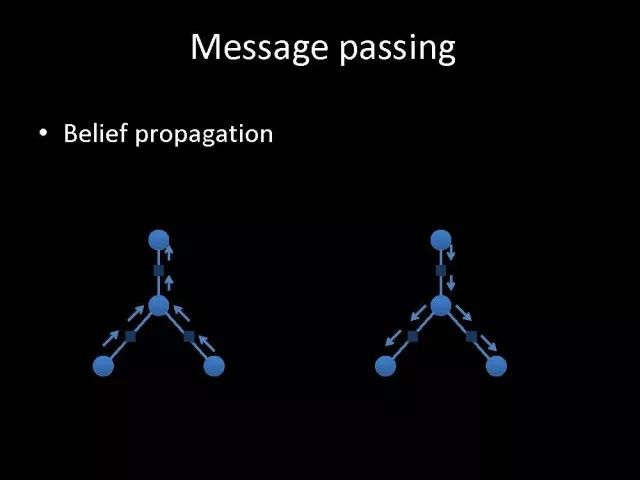
在统计模型指导下,另外一个优势可以利用统计模型中一个很好的信息传递方法,帮助指导我们怎样在各个节点之间传递信息才是最有效的。
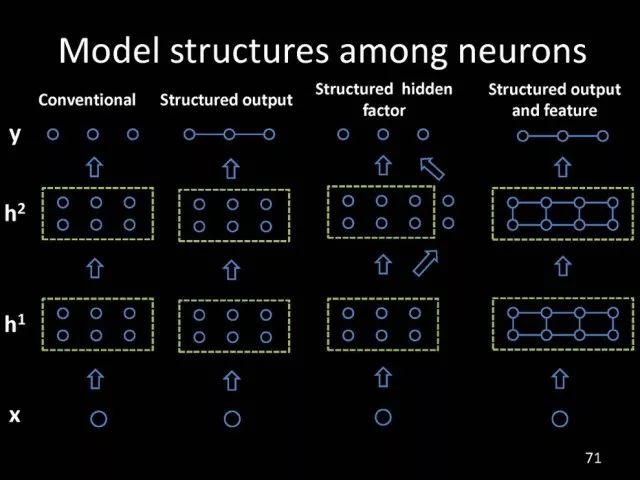
所以,对于结构化信息传递,在已有基础上考虑结构化的输出,可以引入结构化特征,将结构化特征和结构化输出进行联合学习。

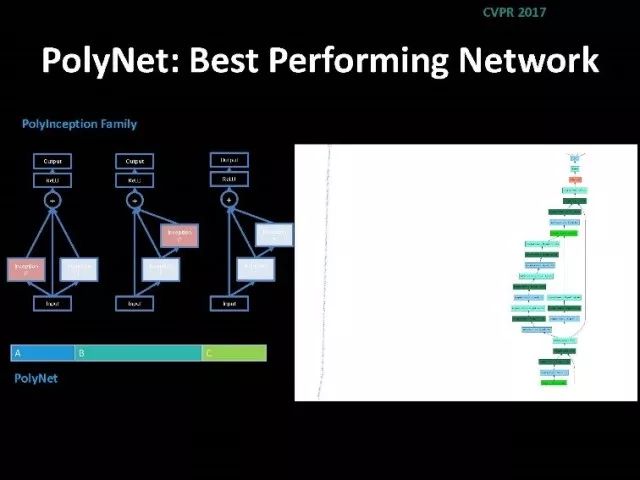
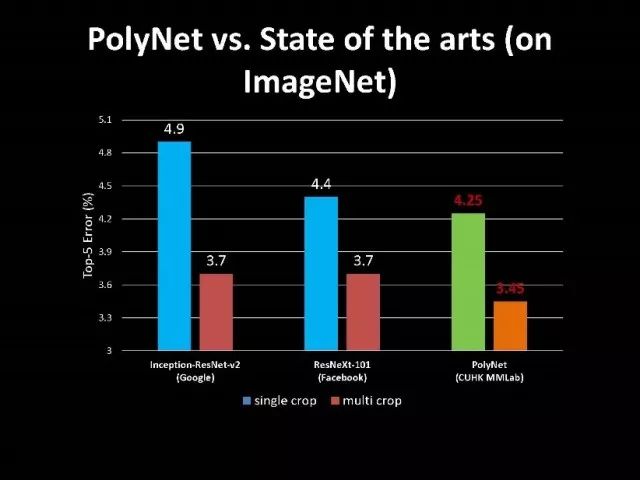
除了结构化学习,我们实验室在基础网络设计上我们也做了很多工作。林达华老师设计非常好的网络-PoLyNet,它是一种非常深的网络结构。这个网络结构的基本想法是同一个模块中,引入多个inception module,可以并行或串行。利用这个方法达华老师所带的学生参加2016年的竞赛,竞赛中单个模型结果是当时最好的。
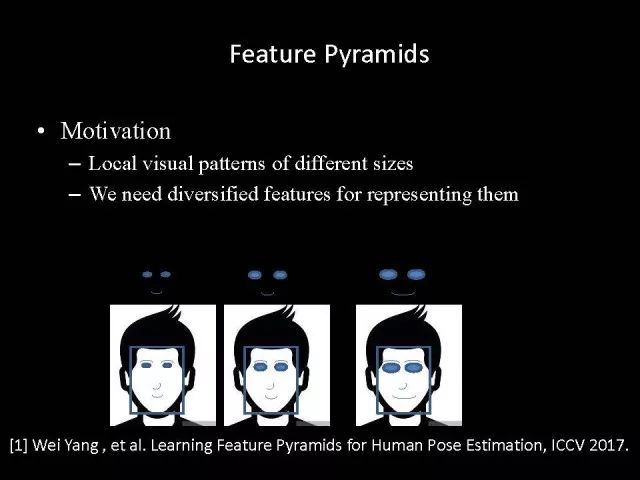
另外一个工作动机是,如果有同样大小的人脸,但是局部特征是不一样的。比如说在这个例子中有三张同样大小人脸,但是人的眼睛和嘴巴视觉信息大小是不一样的。这就要求我们的神经元具有多样性能够捕捉到这些不同大小的特征。
为了捕捉到不同大小的特征,有一种设计,就是设计不同大小的滤波器或者将不同大小的滤波器进行叠加,比如说有3×3再往上叠,可以得到5x5,这会增大参数量和计算复杂度。
我们考虑另外一种方式就是下采样。第一个分支中不采用任何下采样,这样情况下3×3的卷积对应的视觉信息就是3×3的大小,如果另外一个分支使用2的下采样,特征会变得原来1/2,3×3卷积看到大小就是6×6。通过这种方法,只需要改变下采样的参数,就能帮助我们实现捕捉不同大小特征的目的。最终,我们利用上采操作,使下采样造成的不同大小分辨率的特征变成同样大小,便于把它们连接起来。下采样和上采样不需要参数,运算快。这种做法取得了良好的实验效果。
论文相关代码在:
https://github.com/bearpaw/PyraNet.
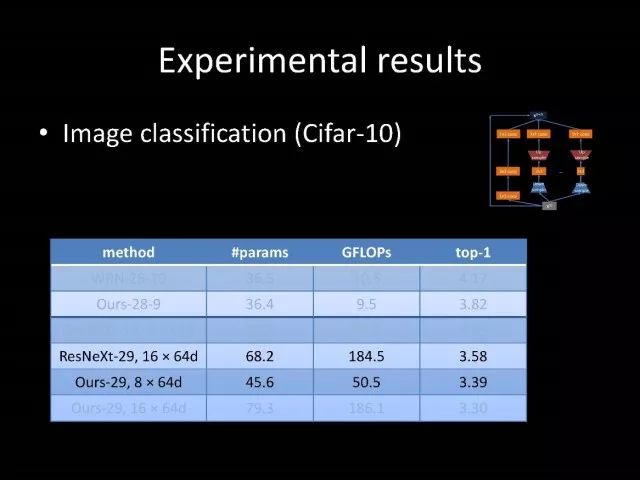
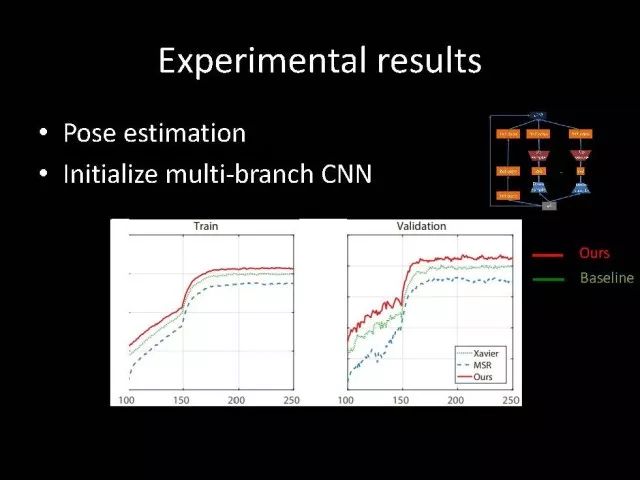
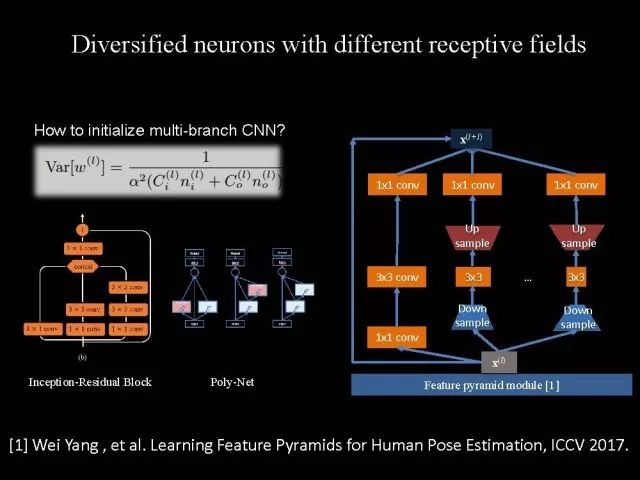
另外一个问题,最近大家提出多种网络结构化,如ResNet,DenseNet,ResNext,甚至像GoogleNet和我们设计的PolyNet,这些网络具有一个共性:它有多个分支。有一个问题是,对应于有多个分支的网络结构情况下,常用的参数初始化方法的基本假设是不成立的。如果用这样的参数初始化会带来一些问题。为了解决这个问题,我们进行严格的理论推导,并给出最终答案。推导发现与输入、输出分支数和参数初始化是相关的。在图像分类以及人体姿态识别上都发现使用我们的方法以后会得到更好的效果。

另外就是人的行为识别。行为识别和很多做视频任务里很重要的信息是运动。


如果要得到关于运动的信息,我们发现有一种很简单的操作,就是先得到两帧图像特征,把两个特征点对点(element-wise)相减。这个相减是时间上的梯度,空间上的梯度可以用很简单的操作得到。这样简单的操作它背后来源于我们数学的推导,数学的推导告诉我们这样特征的表示和光流(optical flow)是正交的,正交意味着它们是互补的,这种特征会拥有原来optical flow没有的信息。实验发现使用我们这种特征而不使用optical flow,能达到的相似的准确率,但在速度上可以快很多。另外,由于特征是由它互补的,特征结合以后可以进一步改善准确率。论文相关代码会在近期提供。

总结一下,结构化深度学习在很多视觉任务中都是有效的。结构化信息通常是来源于观察,来源于对问题的理解。视觉领域的研究者对特定问题的观察和理解可以联合深度学习一起推进整个视觉的进步。另外,我们可以对输出和特征进行结构化的建模。而深度学习这样一个工具提供的能力是将结构的建模和特征的学习进行联合学习,增大最终解决任务的能力。
-
滤波器
+关注
关注
161文章
7848浏览量
178460 -
黑盒子
+关注
关注
0文章
5浏览量
8794 -
深度学习
+关注
关注
73文章
5508浏览量
121314
原文标题:让机器“解疑释惑”:视觉世界中的结构化理解|VALSE2018之八
文章出处:【微信号:deeplearningclass,微信公众号:深度学习大讲堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
马航MH370失联 深藏飞机黑盒子内部电子电路秘密大曝光
一文读懂内窥镜软窥FPGA解决方案

玩转延时摄影,compass黑盒子的秘密
突然黑盒子我的项目
如何在系统设计中添加“黑盒子”故障记录仪?
防窥门镜(猫眼)的解决方案

在系统设计中添加“黑盒子”故障记录议
基站射频可当黑盒子设计,背寄存器的时代结束了!
LED照明的黑盒子及广义与狭义的照明设计介绍
特斯拉黑盒子的出现给智能门锁浇上了一盆冷水
让机器学习模型不再是”黑盒子“
软件测试的代码划分:黑盒白盒灰盒的区别
在系统设计中添加“黑盒子”故障记录议





 工商网监
工商网监
评论