 优化用于深度学习工作负载的张量程序
优化用于深度学习工作负载的张量程序
华盛顿大学计算机系博士生陈天奇、以及上海交通大学和复旦大学的研究团队提出一个基于学习的框架,以优化用于深度学习工作负载的张量程序。该研究使用基于机器学习的方法来自动优化张量运算核心并编译AI工作负载,从而可以将最优的性能部署到所有硬件。实验结果表明,该框架能够为低功耗CPU,移动GPU和服务器级GPU提供与最先进手工调优库相媲美的性能。
深度学习在我们的日常生活中已经无处不在。深度学习模型现在可以识别图像,理解自然语言,玩游戏,以及自动化系统决策(例如设备放置和索引)。张量算符(tensor operators),如矩阵乘法和高维卷积,是深度学习模型的基本组成部分。
可扩展的学习系统依赖于手动优化的高性能张量操作库,如cuDNN。这些库针对较窄范围的硬件进行了优化。为了优化张量算符,程序员需要从逻辑上等价的许多实现中进行选择,但由于线程,内存重用, pipelining和其他硬件因素的不同,性能上的差别很大。
支持多种硬件后端需要巨大的工程努力。即使在当前支持的硬件上,深度学习框架和模型的开发也从根本上受到库中优化操作符设置的限制,阻止了诸如操作符熔合(operator fusion)之类的优化,从而产生不受支持的操作符。
针对这个问题,华盛顿大学计算机系博士生陈天奇、以及上海交通大学和复旦大学的研究团队提出一个基于学习的框架,以优化用于深度学习工作负载的张量程序( tensor programs)。

摘要
我们提出一个基于学习的框架,以优化用于深度学习工作负载的张量程序( tensor programs)。矩阵乘法和高维卷积等张量算符( tensor operators)的高效实现是有效的深度学习系统的关键。然而,现有的系统依赖于手工优化的库,如cuDNN,这些库只有很少的服务器级GPU能很好地支持。对硬件有要求的操作库的依赖限制了高级图形优化的适用性,并且在部署到新的硬件目标时会产生巨大的工程成本。我们利用学习来消除这种工程负担。我们学习了领域特定的统计成本模型,以指导在数十亿可能的程序变体上搜索张量算符的实现。我们通过跨工作负载的有效模型迁移来进一步加快搜索速度。
实验结果表明,我们的框架能够为低功耗CPU,移动GPU和服务器级GPU提供与最先进手工调优库相媲美的性能。
学习优化张量程序问题的形式化方法
我们提出以下问题:我们是否可以通过学习来减轻这种工程负担,并自动优化给定硬件平台的张量算符程序?本论文为这个问题提供了肯定的答案。我们建立了统计成本模型来预测给定的低级程序的程序运行时间。这些成本模型指导了对可能程序空间的探索。我们的成本模型使用可迁移的表示形式,可以在不同的工作负载之间进行泛化,以加速搜索。这一工作的贡献如下:
我们提供了学习优化张量程序问题的一种形式化方法,并总结了其关键特征。
我们提出了一个基于机器学习的框架来解决这个新问题。
我们使用迁移学习将优化速度进一步提高2倍至10倍。
我们在这个框架中提供了详细的组件设计选择和实证分析。
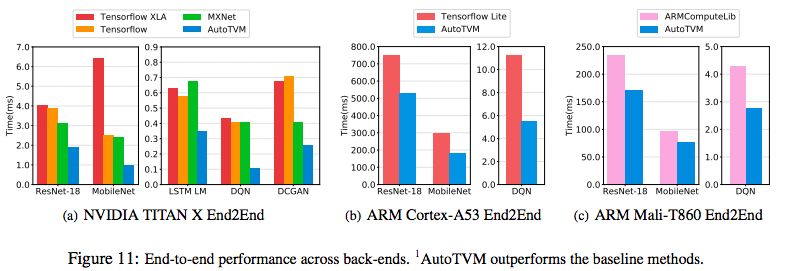
在实际的深度学习工作负载的实验结果表明,我们的框架提供的端到端性能改进比现有框架好1.2倍至3.8倍。
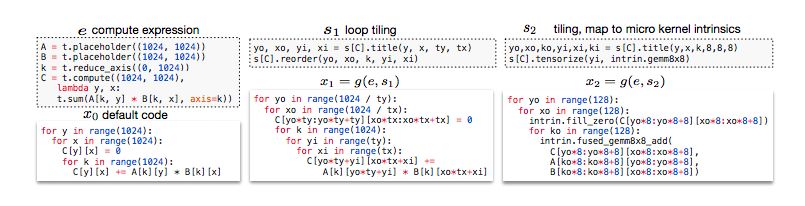
图1:该问题的一个例子。 对于给定的张量算符规范 ,有多种可能的低级别程序实现,每种实现都有不同的loop顺序, tiling 大小以及其他选项。每个选项都创建一个具有不同性能的逻辑等效程序。我们的问题是探索程序空间并找到一个优化的程序。
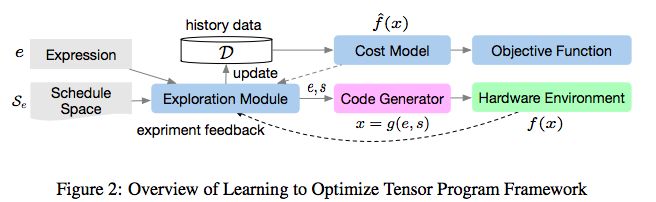
图2:学习优化张量程序框架的概览

学习优化张量程序算法
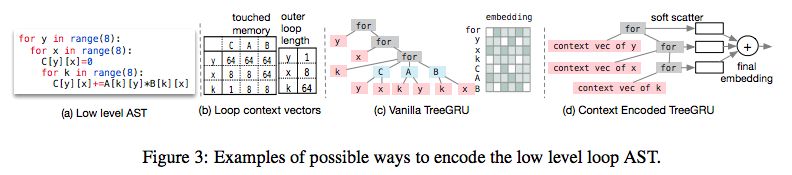
图3:编码低级别循环AST的可能方法的示例

表1:单batch的ResNet-18推理中所有conv2d操作符的配置。H,W表示高度和宽度,IC表示输入通道,OC表示输出通道,K表示 kernel大小,以及S表示stride大小。
讨论和结论
我们提出了一种基于机器学习的框架来自动优化深度学习系统中张量算符的实现。我们的统计成本模型允许在工作负载之间进行有效的模型共享,并通过模型迁移加速优化过程。这个新方法的优秀实验结果显示了对深度学习部署的好处。
在我们的解决方案框架之外,这个新问题的具体特征使它成为相关领域创新的一个理想测试平台,如神经程序建模、贝叶斯优化、迁移学习和强化学习。
在系统方面,学习优化张量程序可以使更多的融合操作符、数据布局和数据类型跨不同的硬件后端。这些改进对于改进深度学习系统至关重要。我们将开放我们的实验框架,以鼓励在这些方向进行更多的研究。
-
深度学习
+关注
关注
73文章
5500浏览量
121118
原文标题:陈天奇团队新研究:自动优化深度学习工作负载
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习工作负载中GPU与LPU的主要差异

RK3568国产处理器 + TensorFlow框架的张量创建实验案例分享
NPU在深度学习中的应用
pcie在深度学习中的应用
深度学习模型的鲁棒性优化
GPU深度学习应用案例
FPGA做深度学习能走多远?
AI引擎机器学习阵列指南

深度学习中的时间序列分类方法
深度学习中的模型权重
深度学习模型训练过程详解
深度学习的模型优化与调试方法
传统计算机视觉对比深度学习
目前主流的深度学习算法模型和应用案例






 工商网监
工商网监
评论