 利用深度学习模型实现监督式语义分割
利用深度学习模型实现监督式语义分割
语义分割是计算机视觉中的任务,语义分割让我们对图像的理解比图像分类和目标物体检测更详细。这种对细节的理解在很多领域都非常重要,包括自动驾驶、机器人和图片搜索引擎。来自斯坦福大学的Andy Chen和Chaitanya Asawa为我们详细介绍了进行精确语义分割都需要哪些条件。本文将重点讲解利用深度学习模型实现监督式语义分割。
人类如何描述一个场景?我们可能会说“窗户下面有一张桌子”或者“沙发右边有一盏台灯”。将场景分割成独立的实体是理解一张图像的关键,它让我们了解目标物体的行为。
当然,目标检测方法可以帮我们在特定实体周围画出边界框。但是要想像人类一样对场景有所了解还需要对每个实体的边界框进行监测和标记,并精确到像素级。这项任务变得越来越重要,因为我们开始创建自动驾驶汽车和智能机器人,它们都需要对周围环境有着精确的理解。来自斯坦福大学的Andy Chen和Chaitanya Asawa就为我们详细介绍了进行精确语义分割都需要哪些条件。以下是论智的编译。
什么是语义分割
语义分割是计算机视觉中的任务,在这一过程中,我们将视觉输入中的不同部分按照语义分到不同类别中。通过“语义理解”,各类别有一定的现实意义。例如,我们可能想提取图中所有关于“汽车”的像素,然后把颜色涂成蓝色。
虽然例如聚类等无监督的方法可以用于分割,但是这样的结果并不是按照语义分类的。这些方法并非按照训练方法进行分割,而是按照更通用的方法。
语义分割让我们对图像的理解比图像分类和目标物体检测更详细。这种对细节的理解在很多领域都非常重要,包括自动驾驶、机器人和图片搜索引擎。这篇文章将重点讲解利用深度学习模型实现监督式语义分割。
数据集和标准
经常用于训练语义分割模型的数据集有:
Pascal VOC 2012:其中有20个类别,包括人物、交通工具等等。目的是为了分割目标物体类别或背景。
Cityscapes:从50个城市收集的景观数据集。
Pascal Context:有超过400种室内和室外场景。
Stanford Background Dataset:该数据集全部由室外场景组成,但每张图片都有至少一个前景。

用来评估语义分割算法性能的标准是平均IoU(Intersection Over Union),这里IoU被定义为:
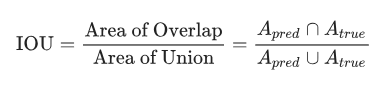
这一标准能保证我们不仅能捕捉到每个目标对象,还能非常精确地完成这一任务。
语义分割过程(Pipeline)
在高级过程中,通常应用语义分割模型的过程如下:
输入→分类器→后处理→最终结果
之后我们将详细讨论分类器和后处理的过程。
结构和分割方法
用卷积神经网络进行分类
最近进行语义分割的结构大多用的是卷积神经网络(CNN),它首先会给每个像素分配最初的类别标签。卷积层可以有效地捕捉图像的局部特征,同时将这样的图层分层嵌入,CNN尝试提取更宽广的结构。随着越来越多的卷积层捕捉到越来越复杂的图像特征,一个卷积神经网络可以将图像中的内容编码成紧凑的表示。
但是想要将单独的像素映射到标签,我们需要在一个编码-解码器设置中增强标准的CNN编码器。在这个设置中,编码器用卷积层和池化层减少图像的宽度和高度,达到一个更低维的表示。之后将其输入到解码器中,通过上采样“恢复”空间维度,在每个解码器的步骤上扩大表示的尺寸。在一些情况中,编码器中间的步骤是用来帮助解码器的步骤的。最终,解码器生成了一群表示原始图像的标签。

SCNet的编码-解码设置
在许多语义分割结构中,CNN想要最小化的损失函数是交叉熵损失。这一目标函数测量每个像素的预测概率分布与它实际概率分布的距离。
然而,交叉熵损失对语义分割并不理想,因为一张图像的最终损失仅仅是每个像素损失的总和,而交叉熵损失不是并行的。由于交叉熵损失无法在像素间添加更高级的架构,所以最小化交叉熵的标签会经常变得不完整或者失真,这时候就需要后处理了。
用条件随机场进行改进
CNN中的原始标签经常是经过补缀的图像,其中可能有一些地方是错误的标签,与周围的像素标签不一致。为了解决这一不连贯的问题,我们可以应用一种令其变光滑的技术。我们想保证目标物体所在图像区域是连贯的,同时任何像素都与其周围有着相同的标签。
为了解决这一问题,一些架构用到了条件随机场(CRFs),它利用原始图像中像素的相似性调整CNN的标签。
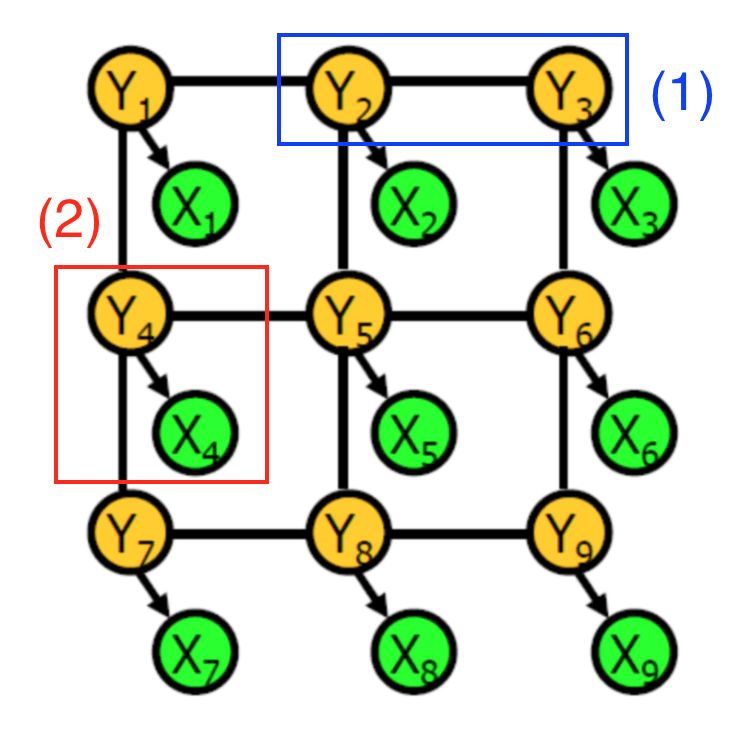
条件随机场的示例
一个条件随机场是由随机变量组成的图形。在这一语境中,每个节点代表:
特定像素的CNN标签(绿色)
特定像素的实际物体标签(黄色)
每个连接线中编码了两个类型的信息:
蓝色:两像素中实际标签之间的相关性
红色:CNN原始预测和给定像素的实际标签之间的依赖关系
每种依赖关系都与潜力有关,它是由两个相关随机变量表示的函数。例如,当相邻像素的实际标签相同时,第一种依赖关系的可能性更高。更直接地说,对象标签起到隐藏变量的作用,可以根据某些概率分布生成可观察的CNN像素标签。
要用CRF调整标签,我们首先用训练数据学习图像模型的参数。然后,我们再调整参数使概率最大化。CRF推断的输出就是原始图像像素的最终目标标签。
在实际中,CRF图形是完全连接的,这意味着即使与节点相对的像素距离很远,仍然可以在一条连接线上。这样的图形有几十亿条连接线,在计算实际的推断时非常耗费计算力。CRF架构将用高效的估算技术进行推断。
分类器结构
CNN分类之后的CRF调整只是语义分割过程的一个示例。许多研究论文都讨论过这一过程的变体:
U-Net通过生成原始训练数据的变形版本增强其训练数据。这一步骤让CNN的编码-解码器在应对这样的变形时更加稳定,同时能在更少的训练图像中学习。当在一个不到40张的医学图像集中训练时,模型的IoU分数依然达到了92%。
DeepLab结合了CNN编码-解码器和CRF调整,生成了它的对象标签(作者强调了解码过程中的上采样)。空洞卷积使用每层不同尺寸的过滤器,让每个图层捕捉到不同规模大小的特征。在Pascal VOC 2012测试集上,这一结构的平均IoU分数为70.3%。
Dilation10是空洞卷积的替代方法。在Pascal VOC 2012测试集上,它的平均IoU分数为75.3%。
其他训练过程
现在我们关注一下最近的训练案例,与含有各种元素、优化不同的是,这些方法都是端到端的。
完全差分条件随机场
Zheng等人提出的CRF-RNN模型介绍了一种将分类和后处理结合到一种端到端模型的方法,同时优化两个阶段。因此,例如CRF高斯核的权重参数就可以自动学习。它们浮现了推理近似算法作为卷积而达到这一目的,同时使用循环神经网络模拟推理算法的完全迭代本性。
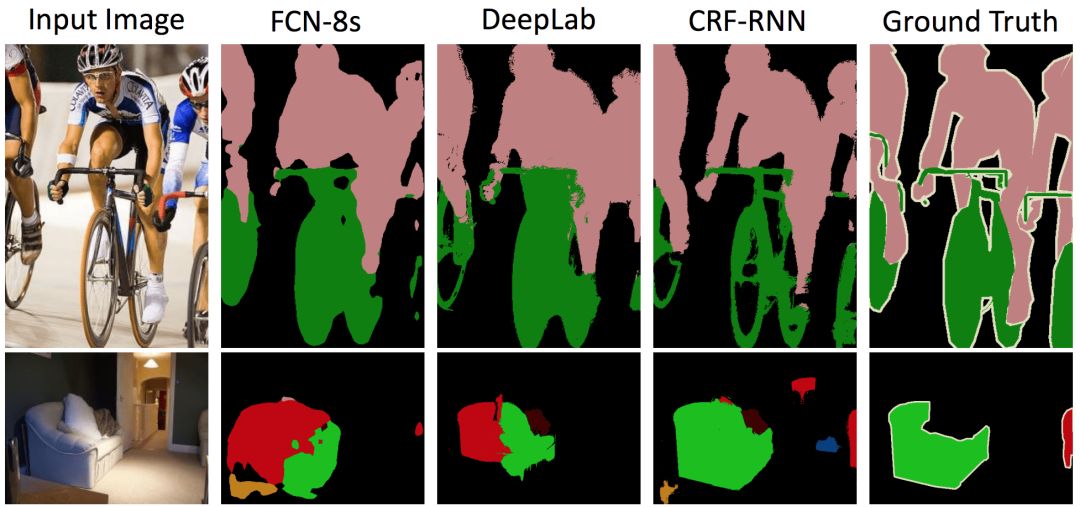
分别用FCN-8s、DeepLab和CRF-RNN生成的两张图片的分割
对抗训练
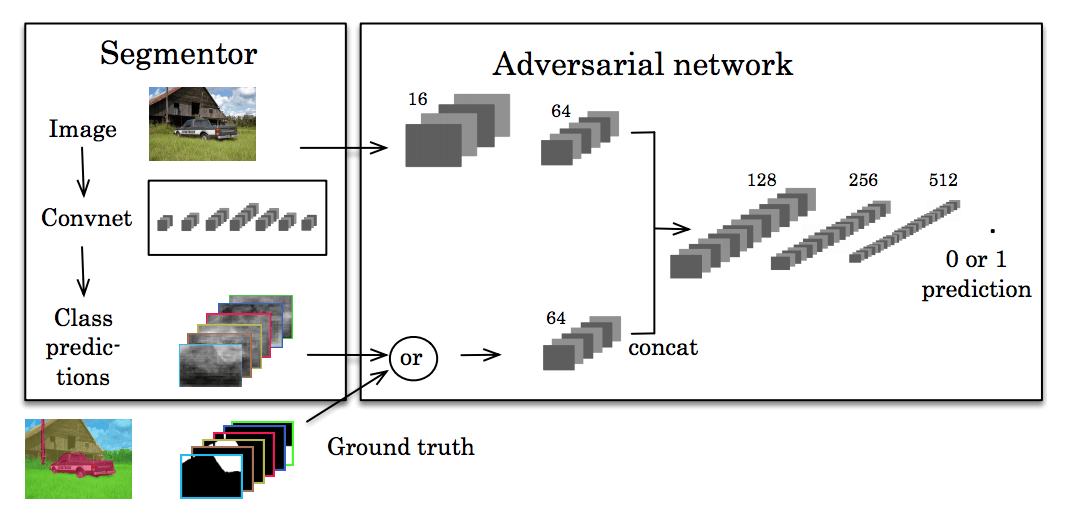
最近,还有人研究了利用对抗训练帮助开发更高程度的一致性。受到生成对抗网络的启发,Luc等人训练了一个标准的CNN用来做语义分割,同时还有一个对抗网络,试着学习标准分割与预测分割之间的区别。分割网络的目的是生成对抗网络无法分辨的语义分割。
这里的中心思想是,我们想让我们的分割看起来尽可能真实。如果其他网络可以轻易识破,那么我们做出的分割预测就不够好。
随时间进行分割
我们如何预测目标物体在未来会如何呢?我们可以对某一场景中的分割动作建模。这可以应用到机器人或自动交通工具中,这些产品需要对物体的移动进行建模,从而做计划。
Luc等人在2017年讨论了这一问题,在论文中他们表示直接预测未来的语义分割会生成比预测未来框架然后再分割更好的性能。
他们用了自动回归模型,用过去的分割预测下一个分割,以此类推。
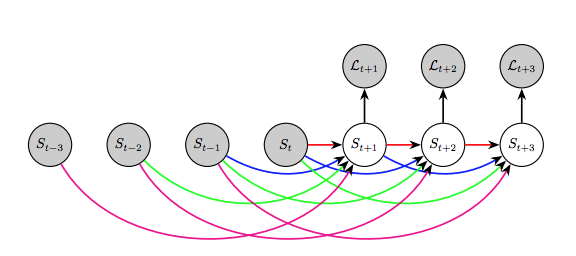
最终发现这种方法长期的性能不太好,中短期来看效果不错。
结语
在这之中的很多方法,例如U-Net,都遵循了一个基础结构:我们引用深度学习(或卷积网络),之后用传统概率的方法进行后处理。虽然卷积网络的原始输出不太完美,后处理能将分割的标签调整到接近人类的水平。
其他方法,例如对抗学习,可以看作是分割的强大端到端解决方案。与之前的CRF步骤不同,端到端技术无需人类建模调整原始预测。由于这些技术目前的性能比多步骤的方案都好,未来将有更多关于端到端算法的研究。
-
编码器
+关注
关注
45文章
3645浏览量
134569 -
神经网络
+关注
关注
42文章
4772浏览量
100803 -
深度学习
+关注
关注
73文章
5503浏览量
121200
原文标题:细说语义分割,不只是画个边框那么简单
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
van-自然和医学图像的深度语义分割:网络结构
van-自然和医学图像的深度语义分割:网络结构
基于深度学习的多尺幅深度网络监督模型


结合双目图像的深度信息跨层次特征的语义分割模型

基于深度学习的三维点云语义分割研究分析


基于SEGNET模型的图像语义分割方法
模型在学习可转移的语义分割表示方面的有效性
CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构







 工商网监
工商网监
评论