 英特尔新一代AI芯片NNP-L1000明年面世
英特尔新一代AI芯片NNP-L1000明年面世
英特尔首届AI开发者大会发布了一系列机器学习软件工具,并宣布包括其首款商用神经网络处理器产品将于2019年推出。英特尔在旧金山举办第一届AI开发者大会(AI Dev Con),英特尔人工智能负责人Naveen Rao做了开场演讲。
Rao此前是Nervana的CEO和联合创始人,该公司于2016年被英特尔收购。
Naveen Rao
在会上,Rao发布了一系列机器学习软件工具,并宣布英特尔新一代产品,其中包括其首款商用NNP产品NNP-L1000,将于2019年推出。
以下从软件和硬件两个方面介绍AI Dev Con的重点。
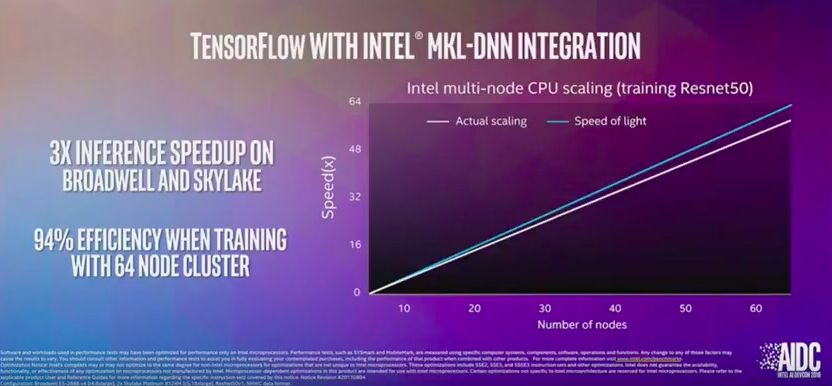
MKL-DNN是用于深层神经网络的数学内核库。它是神经网络中常见组件的数学程序列表,包括矩阵乘数、批处理规范、归一化和卷积。该库针对在英特尔CPU上部署模型进行了优化。
nGraph开发者选择不同的AI框架,它们都有各自的优点和缺点。为了使芯片具有灵活性,后端编译器必须能够有效地适应所有的芯片。
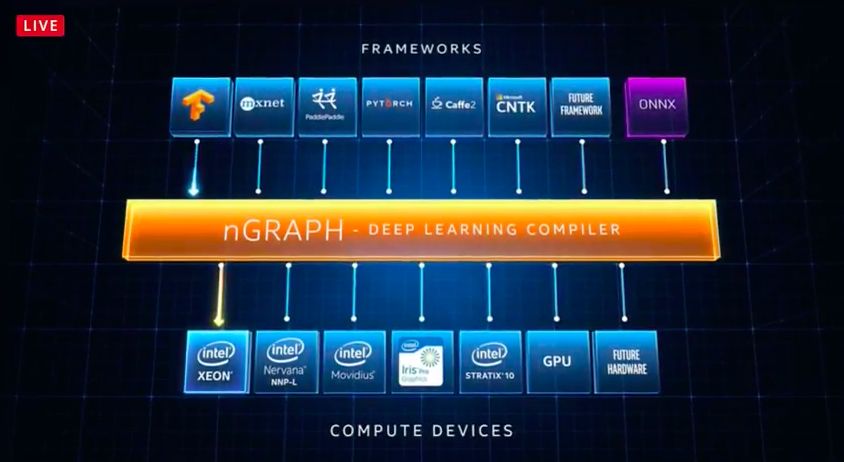
nGraph是一个编译器,它可以在英特尔的芯片上运行。开发人员可能想要在英特尔的Xeons处理器上训练他们的模型,然后使用英特尔的神经网络处理器(NNP)进行推理。
BigDL是Apache Spark的另一个库,它的目标是通过分布式学习在深度学习中处理更大的工作负载。应用程序可以用Scala或Python编写,并在Spark集群上执行。
OpenVINOA软件工具包用于处理“边缘”(即摄像头或移动电话)视频的模型。开发人员可以实时地做面部识别的图像分类。它预计将在今年晚些时候开放,但现在可以下载了。
再来看硬件部分。
英特尔在这方面比较沉默,没有透露更多的细节。
“几年前Xeons不适合AI,但现在真的已经改变了。”Rao强调,增加的内存和计算意味着自Haswell芯片以来性能提高了100倍,并且推理的性能提高了近200倍。
“你可能听说过GPU比CPU快100倍。这是错误的。”他补充说,“今天大多数推理都是在Xeons上运行的。”
Rao没有提到Nvidia,他解释说GPU在深度学习方面起了个好头,但受限于严重的内存限制。 Xeon拥有更多的内存,可以扩展到批量大的内存,因此它更适合推理。
在现场,ZIVA CEO James Jacobs还介绍了如何将Xeons用于3D图像渲染。
左边的狮子是没有使用AI,右边的狮子使用了AI,效果很棒。
他也简要地谈到了FPGA加速的问题,并表示英特尔正在研发一种“离散加速器”(discrete accelerator)进行推理,但没有透露更多细节。
同时,还介绍了Intel Movidius的神经计算棒。它是一个U盘,可以运行使用TensorFlow和Caffe编写的模型,耗电量大约一瓦。去年,英特尔公司决定终止其可穿戴设备,如智能手表和健身腕带。
现场还展示了一段用计算棒来进行AI作曲的DEMO,人类演奏者演奏一段曲子,AI能够在这段曲子的基础上进行创作。
英特尔去年宣布神经网络处理器(NNP)芯片。虽然没有发布任何基准测试结果,但英特尔表示将会有可供选择的客户。
Rao也没有透露多少细节。不过,大家所知道的是,它包含12个基于其“Lake Crest”架构的内核,总共拥有32GB内存,在未公开的精度下性能达到40 TFLOPS,理论上的带宽不足800纳秒,在低延迟的互连上,每秒2.4兆的带宽。
最后介绍了NNP L1000,Rao对它的介绍更少,这将是第一个商业NNP模型,并将在2019年推出。它将基于新的Spring Crest体系结构,预计将比之前的Lake Crest模型快3到4倍。
开发者大会的当天,英特尔官网发出一篇Rao的署名文章,对英特尔Nervana神经网络处理器(NNP)进行了介绍。
Nervana NNP有一个明确的设计目标,可实现高计算利用率和支持多芯片互连的真模型并行。
行业里讨论了很多关于最大的理论性能,然而,实际情况是,除非体系结构有能够支持这些计算元素的高利用率的储存器子系统,否则大部分计算都是没有意义的。此外,行业发布的大部分性能数据使用的是大型矩阵,这些矩阵通常在现实世界的神经网络中并不常见。
英特尔专注于为神经网络创建一个平衡的架构,它还包括低延迟的高芯片到芯片带宽。NNP系列的初始性能基准在利用率和互连方面显示出强劲的竞争力。具体包括:
使用A(1536, 2048)和B(2048, 1536)矩阵进行矩阵乘法运算的一般矩阵,在单个芯片上实现了96.4个百分点的计算利用率。这代表了在单个芯片上的实际(非理论)性能的38TOP/s。支持模型并行训练的多芯片分布式GEMM操作实现了A(6144,2048)和B(2048,1536)矩阵大小的接近线性缩放和96.2%的缩放效率,使得多个NNP能够连接在一起,并将我们从其他架构的内存限制中释放出来。
我们测量了89.4 %的单方向芯片到芯片的效率,理论上的带宽小于790ns(纳秒)的延迟,并且将其应用于2.4Tb/s的高带宽、低延迟互连。
所有这些都在单芯片总功率范围内低于210瓦的情况下进行,这只是英特尔Nervana NNP(Lake Crest)原型。
英特尔将在2019年提供第一个商用NNP产品——英特尔Nervana NNP-L1000(Spring Crest)。
预计英特尔Nervana NNP-L1000的性能将达到第一代Lake Crest产品的3-4倍。
在英特尔Nervana NNP-L1000中,还将支持bfloat16,这是一种业界广泛用于神经网络的数字格式。
随着时间的推移,英特尔将在其AI产品线上扩展bfloat16支持,包括英特尔Xeons处理器和英特尔FPGA。
-
英特尔
+关注
关注
61文章
9978浏览量
171889 -
AI
+关注
关注
87文章
31000浏览量
269333 -
机器学习
+关注
关注
66文章
8422浏览量
132743
原文标题:超越传统CPU?英特尔新一代AI芯片明年面世
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英特尔与火山引擎飞连携手升级AI时代企业IT管理体验
英特尔目标明年出货1亿台AI PC
英特尔计划明年AI PC出货一亿台
英特尔调降明年AI服务器芯片出货目标
AI PC市场爆发,英特尔、高通相继推出新一代AI PC芯片,战况火热升级
IBM Cloud将部署英特尔Gaudi 3 AI芯片
软银与英特尔AI芯片合作计划告吹
英特尔发布AI创作应用AI Playground,将于今夏正式上线!

英特尔CEO:AI时代英特尔动力不减
英特尔发布新一代Lunar Lake处理器
英特尔AI产品助力其运行Meta新一代大语言模型Meta Llama 3
英特尔首推面向AI时代的系统级代工—英特尔代工






 工商网监
工商网监
评论