 一种新颖的基于强化学习的图像复原算法—RL-Restore
一种新颖的基于强化学习的图像复原算法—RL-Restore
简介
在底层视觉算法领域,卷积神经网络(CNN)近年取得了巨大的进展,在诸如去模糊、去噪、去JPEG失真、超分辨率等图像复原任务上已经达到了优异的性能。但是现实图像中的失真往往更加复杂,例如,经过多个图像降质过程后,图像可能包含模糊、噪声、JPEG压缩的混合失真。这类混合失真图像对目前的图像复原算法仍然充满挑战性。
近期的一些图像复原工作(如VDSR、DnCNN等)证实了一个CNN网络可以处理多种失真类型或不同失真程度的降质图像,这为解决混合失真问题提供了新的思路。但是,这类算法均选用了复杂度较高的网络模型,带来了较大的计算开销。另外,这些算法的网络均使用同一结构处理所有图像,未考虑一些降质程度较低的图像可以使用更小的网络进行复原。
针对现有图像复原CNN算法模型复杂,计算复杂度高的问题,本文提出的RL-Restore算法弥补了这些不足,以更加高效灵活的方式解决了复杂的图像复原问题。
RL-Restore算法的设计思想与挑战
当前流行的图像复原理念认为解决复杂的图像复原问题需要一个大型的CNN,而本文提出了一种全新的解决方案,即使用多个小型CNN专家以协作的方式解决困难的真实图像复原任务。RL-Restore算法的主要思路是设计一系列基于小型CNN的复原工具,并根据训练数据学习如何恰当地组合使用它们。这是因为现实图像或多或少受到多种失真的影响,针对复杂失真的图像学习混合使用不同的小型CNN能够有效的解决现实图像的复原问题。不仅如此,因为该算法可以根据不同的失真程度选取不同大小的工具,相较于现有CNN模型,这一新方法使用的参数更少,计算复杂度更低。
RL-Restore算法的目标是对一张失真图像有针对性地选择一个工具链(即一系列小型CNN工具)进行复原,因而其该算法包含了两个基本组件:
一个包含多种图像复原小型CNN的工具箱;
一个可以在每一步决定使用何种复原工具的强化学习算法。
本文提出的工具箱中包含了12个针对不同降质类型的CNN(如表1所示)。每一种工具解决一种特定程度的高斯模糊、高斯噪声、JPEG失真,这些失真在图像复原领域中最为常见。针对轻微程度失真的复原工具CNN仅有3层,而针对严重程度失真的工具达到8层。为了增强复原工具的鲁棒性,本文在所有工具的训练数据中均加入了轻微的高斯噪声及JPEG失真。

表1:
工具箱中的图像复原工具

图1:
不同图像复原的工具链对最终结果产生不同影响
(c, d) 适用于这两张失真图像的CNN工具链
(b, e) 改变工具使用顺序的图像复原结果
(a, f) 改变工具强度的图像复原结果
有了工具箱,如何选择工具成为本文解决的主要挑战之一。图1展示了不同工具链的图像复原结果,可以看到对工具链的微小调整可能导致复原结果的剧烈变化。本文解决的第二个挑战在于,没有一个已有的工具可以恰当的处理“中间结果”。例如,去模糊的工具可能也会放大噪声,导致后面已有的去噪工具无法有效处理新引入的未知失真。针对这些挑战,本文使用强化学习算法训练得到有效的工具选择策略,同时还提出联合训练算法对所有工具进行端到端的训练以解决有效复原“中间结果”的挑战。
基于强化学习的普适图像复原
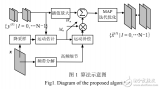
RL-Restore算法的框架(如图2所示)。对于一张输入图像,agent首先从工具箱中选择一个工具对它进行恢复。然后agent根据当前的状态(包括复原中间结果和之前工具的选择)来选取下一个动作(使用复原工具或停止),直到算法决定终止复原过程。

图2:
RL-Restore算法框架,虚线框内为Agent结构
动作(action):在每一个复原步骤 t,算法会输出一个估值向量vt选择一个动作at。除了停止动作以外,其余每一个动作均代表使用某个复原工具。在本文中,工具箱内共包含12个工具,因而算法总共包含13个动作。
状态(state):状态是算法可以观测到的信息,在步骤t的状态记为St={It,v ̃t},其中It是当前步骤的输入图像,v ̃t=vt-1是前一步骤的动作估值向量,包含了前一步骤的决策信息。
回报(reward):在强化学习中,算法的学习目标是最大化所有步骤的累积回报,因而回报是驱动算法学习的关键。本文希望确保图像质量在每一步骤都得到提升,因此设计了一个逐步的回报函数rt=Pt+1-Pt,其中Pt+1和Pt分别代表步骤t的输入图像和输出图像的PSNR,度量每个步骤中图像PSNR的变化。
结构:虚线框内的agent包含了三个模块(如图2所示):
特征提取器(Feature Extractor),包含了4个卷积层和1个全连接层,将输入图像转化为32维特征向量;
One-hot编码器(One-hot Encoder),其输入是前一步骤的动作估值向量,输出将其转换为对应的特征向量;
LSTM,其以前两个模块输出作为输入,这个模块不仅观测当前步骤的状态特征,还存储了历史状态的信息,该模块最后输出当前步骤的估值向量,用于复原工具的选取。
训练:每一个复原工具的训练均使用MSE损失函数,而agent的训练则使用deep Q-learning算法。由于LSTM具有记忆性,每一个训练样本均包含一条完整的工具链。
联合训练算法
至此,RL-Restore算法已经拥有了较好的工具选取策略,还需要解决对“中间结果”进行复原的挑战。前文已经提到,由于前面的复原步骤可能引入新的未知失真,没有一个已有工具能对这类复杂的“中间结果”进行有效处理。因此,本文提出了联合训练算法,将所有的工具以及工具的选择进行端到端地训练,从而解决“中间结果”的复原问题。具体而言,对于每一张输入图像,先通过所选取的工具链前向传播得到最后的复原图像,通过与清晰参考图像对比得到MSE损失,然后通过工具链对误差进行反向传播,根据平均的梯度值更新工具网络的参数。

算法1:
联合训练算法
实验结果
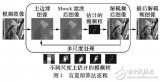
本文使用DIV2K训练集的前750张图像用于训练,后50张图像用于测试。通过抠取分辨率为63x63的子图像,共得到25万张训练图像和3,584张测试图像。本文在每一张图像上随机加上不同程度的高斯模糊、高斯噪声和JPEG压缩。算法在训练样本中排除一些极度轻微或严重的失真,使用中度失真的图像进行训练(如图3所示),而在轻度、中度和重度失真的图像上进行测试。

图3:
不同程度的失真图像
本文与现有的VDSR和DnCNN图像复原算法相比,模型复杂度更低而复原性能更加优异(如表2、3所示)。其中VDSR-s是与VDSR结构相似的小参数模型,其参数量与RL-Restore算法相当。表2展示了RL-Restore算法具有最小的参数量和计算复杂度,表3展示了RL-Restore算法与VDSR和DnCNN等大模型在轻度和中度失真测试集上具有类似的性能,而在重度失真测试集上则表现得更加优异。在参数量相当的情况下,RL-Restore算法在各个测试集上均比VDSR-s算法拥有更加优异的复原性能。图4展示了不同算法和本文算法在不同步骤复原结果的对比。

表2:
模型复杂度对比

表3:
复原结果对比

图4:
可视化复原结果对比
本文也使用实际场景图像对RL-Restore算法进行了进一步测试。如图5所示,测试图像由智能手机采集,其中包含了模糊、噪声和压缩等失真,直接使用训练好的RL-Restore和VDSR模型在这些真实场景图像进行测试。由结果可以看到,RL-Restore算法取得了明显更加优异的复原结果,图5(a, c) 展示了RL-Restore算法成功修复由曝光噪声和压缩带来的严重失真;图5(b, d, e) 展示了本文方法可以有效地处理混合的模糊与噪声。

图5:
RL-Restore算法对实际场景图像的复原结果
结论
本文提出了一种新颖的基于强化学习的图像复原算法—RL-Restore。与现有的深度学习方法不同,RL-Restore算法通过学习动态地选取工具链从而对带有复杂混合失真的图像进行高效的逐步复原。基于合成数据与现实数据的大量实验结果证实了该算法的有效性和鲁棒性。由于算法框架的灵活性,通过设计不同的工具箱和回报函数,RL-Restore算法为解决其他富有挑战性的底层视觉问题也提供了新颖的解决思路。
-
神经网络
+关注
关注
42文章
4789浏览量
101597 -
图像
+关注
关注
2文章
1091浏览量
40682 -
cnn
+关注
关注
3文章
353浏览量
22441
原文标题:CVPR 2018 | 商汤科技Spotlight论文详解:RL-Restore普适图像复原算法
文章出处:【微信号:SenseTime2017,微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度强化学习实战
一种新型的强化学习算法,能够教导算法如何在没有人类协助的情况下解开魔方
深度强化学习的概念和工作原理的详细资料说明
深度强化学习到底是什么?它的工作原理是怎么样的
机器学习中的无模型强化学习算法及研究综述

强化学习的基础知识和6种基本算法解释
彻底改变算法交易:强化学习的力量
强化学习的基础知识和6种基本算法解释






 工商网监
工商网监
评论