 检测套现欺诈?用分布式深度森林算法就够了
检测套现欺诈?用分布式深度森林算法就够了

【导读】互联网公司每天都面临着处理大规模机器学习应用程序的问题,因此我们需要一个可以处理这种超大规模的日常任务的分布式系统。最近,以集成树为构建模块的深度森林(Deep Forest)算法被提出,并在各个领域取得了极具竞争力的效果。然而,这种算法的性能还未在超大规模的任务中得到测试。近日,基于蚂蚁金服的参数服务器系统“鲲鹏”及其人工智能平台“PAI”,蚂蚁金服和南京大学周志华教授的研究团队合作开发了一种分布式的深度森林算法,同时提供了一个易于使用的图形用户界面(GUI)。
为了满足现实世界的任务需求,周志华团队等对原始的深度森林模型进行了诸多改进。针对超大规模的任务,如套现欺诈(cash-out fraud)行为的自动检测 (拥有超过1亿的训练样本),研究人员测试了深度森林模型的性能。实验结果表明,在不同的评估标准下,只需微调模型的参数,深度森林模型便能在大规模任务处理上取得当前最佳的性能,从而有效地阻止大量套现欺诈行为的发生。即使和目前已经部署的其他最佳模型相比,深度森林模型依然能够显著减少经济损失。
以下是论文内容:
▌简介
对于蚂蚁金融这样的金融公司,套现欺诈行为是常见危害之一。买家通过蚂蚁金融发行的蚂蚁信用服务与卖家进行交易支付,并从卖家处获得现金。如果没有合适的欺诈检测手段,那么每天诈骗者就能够从套现欺诈中获取的大量现金,这对网络信用构成了一个严重的威胁。目前,基于机器学习的检测方法,如逻辑回归 (LR) 和多元加性回归树 (MART),能够在一定程度上预防这种欺诈行为,但是我们需要更有效的方法,因为任何微小的改进都将显著地降低经济损失。另一方面,随着数据驱动的机器学习模型有效性的日益提高,数据科学家经常与产品部门密切合作,为这些任务设计并部署有效的统计模型。对数据科学家和机器学习工程师来说,希望通过一个理想的高性能平台来处理大规模的学习任务 (经常有数百万或数十亿的训练样本)。此外,这个平台的搭建过程要简单,并能运行不同的任务以提高生产力。
基于树结构的模型,如随机森林和多重加权回归树模型,仍然是各种任务的主要方法之一。由于这种模型的优越性能,在 Kaggle 比赛或数据科学项目中大部分的获胜者也都使用集成的多元加性回归树模型 (ensemble MART) 或其变体结构。由于金融数据的稀疏性和高维性,我们需要将其视为离散建模或混合建模问题,因此,诸如深度神经网络结构的模型并不适用于蚂蚁金融这种公司的日常工作。
最近,周志华研究团队提出了一种深度森林算法,这是一种新的深层结构,无需进行微分求解,特别适合树结构。相比于其他非深度神经网络模型,深度森林算法能够实现最佳性能;而相较于当前最佳的深度神经网络模型,它能实现极具竞争力的结果。此外,深度森林模型的层数及其模型复杂性能够自适应于具体的数据,其超参数的数量还比深度神经网络模型要少得多,可视为是一些现成分类器的优秀替代品。
在现实世界中,许多任务都包含离散特征,当使用深度神经网络进行建模时,处理这些离散特征将会变得一个棘手的问题,因为我们需要将离散信息进行显式或隐式地连续转换,但这样的转换过程通常会导致额外的偏差或信息的丢失。而基于树结构的深度森林模型能够很好地处理这种数据类型问题。这项工作中,我们在分布式学习系统“鲲鹏”上实施并部署了深度森林模型,这是分布式深度森林模型在参数服务器上的第一个工业实践,能够处理数百万的高维数据。
此外,在蚂蚁金服的人工智能平台上,我们还设计了一个基于 Web 的图形用户界面,允许数据科学家通过简单地拖动和点击就能自如地使用深度森林模型,而无需任何的编码过程。这将方便数据科学家的工作,使得构建和评估模型的过程变得非常有效且方便。
我们在这项工作中的主要贡献可以总结如下:
-
基于现有的分布式系统“鲲鹏”,我们实现并部署了第一个分布式深度森林模型,并在我们的人工智能平台 PAI 上为其搭建了一个易于使用的图形界面。
-
我们对原始的深度森林模型进行了许多改进,包括 MART 作为基础学习者的效率和有效性,诸如基于成本的类别不平衡数据的处理方法,基于 MART 的高维数据特征选择和不同级联水平的评估指标的自动确定等任务。
-
我们在套现欺诈行为的自动检测任务上验证了深度森林模型的性能。结果表明,在不同的评估指标下,深度森林模型的性能都明显优于现有的所有方法。更重要的是,深度森林模型强大的鲁棒性也在实验中得到了验证。
▌系统介绍
鲲鹏系统
鲲鹏是一款基于参数服务器的分布式学习系统,该系统主要用于处理工业界出现的大规模任务。作为生产级别的分布式参数服务器,Kunpeng 系统具有如下几大优点:(1) 强大的故障转移机制,保证大规模工作的高成功率; (2) 适用于稀疏数据和通用通信的高效接口; (3) 用户友好型的 C ++ 和 Python 系统开发工具(SDKs)。其结构简图如下图1所示:

图1:鲲鹏结构简图,包括 ML-Bridge,PS-Core 部分。用户可以在 ML-Bridge 上自如地操作。
分布式 MART
多元加权回归树模型 (MART),也称为梯度提升决策树模型 (GBDT) 或梯度增强机模型 (GBM),是一种在学术和工业领域广泛使用的机器学习算法。得益于其高效而优秀的模型可解释性,在这项工作中我们在分布式系统中部署 MART,并将其作为分布式深度森林模型的基本组成部分。此外,我们还结合了其他的树结构模型进一步开发深度森林模型的分布式版本。
深度森林模型结构
深度森林模型是最近提出的一种以集成树为构建模块的深度学习框架。 其原始版本由 ne-grained 模块和级联模块 (cascading module) 构成。在这项工作中,我们弃用了 ne-grained 模块,并建立了多层的级联模块,每层由几个基础的随机森林或完全随机森林模块构成,其结构如下图2所示。 对于每个基础模块而言,输入是由前一层产生的类向量和原始的输入数据组合而成的,然后再将每个基础模块的输出组合得到最终的输出。此外,对每一层进行 K 倍验证,当验证集的准确率不在提高时,级联过程也随之自动终止。

图2:深度森林模型结构
对于一般的工作部署策略,模型训练模块需要在所有数据准备工作完成后才能开始工作,而模型测试模块也必须在所有模型都训练成功后才能开始预测,这样显著地降低了系统的工作效率。因此,在分布式系统上,我们采用有向无环图 (DAG) 来提高系统工作的效率。有向无环图,顾名思义就是一个没有定向循环的有向图,其结构如下图3所示。

图3:有向无环图的工作调度,每个长方形代表一个进程,只有彼此相关的进程才能互相连接。
我们将图中的一个节点视为一个进程,并且只连接彼此相关的进程。两个相关节点的先决条件是一个节点的输出作为另一节点的输入。只有当一个节点的所有先决条件都满足时,另一节点才会被执行。每个节点都是分开执行的,这意味着一个节点发生故障时并不会影响随后的其他节点。如此,系统的等待时间将显著地、缩短,因为每个节点只需要等待相应节点的执行完毕。更重要的是,这样的系统设计为故障转移提供了更好的解决方案。例如,当一个节点因为某些原因导致崩溃,那么只要因为它的前提条件满足了,我们就可以从这个节点开始重新运行,而不需要从头开始运行整个算法。
图形用户界面(GUI)
如何有效地构建并评估模型性能,对于生产力的提高是至关重要的。为了解决这个问题,我们在蚂蚁金服的人工智能平台 PAI 上开发了一个图形用户接口 (GUI)。
下图4展示了深度森林模型的 GUI 界面,其中箭头表示数据流之间的序列相关性,图中每个节点代表一个操作,包括加载数据,构建模型,模型预测等。例如,一个深度森林模型的所有细节都被封装成一个单一节点,我们只需要指定使用哪个基础模块,模块中每层的数量及其他一些基础配置。这里默认的基础模块是前面提到的 MART。 因此,用户只需要点击几下鼠标就能在几分钟内快速创建深度森林模型,并在模型训练结束后得到评估结果。

图4:PAI 平台上深度森林模型的 GUI 界面,每个节点代表一个操作。
▌实验应用
数据准备
我们在现金支付欺诈的自动检测任务上验证深度森林模型的性能。对于这个检测任务,我们需要做的事检测出欺诈行为的潜在风险,以避免不必要的经济损失。我们将这个任务视为二元分类问题,并收集四个方面的原始信息,包括描述身份信息的卖家特征和买家特征,描述交易信息的交易特征和历史交易特征。如此,每当一次交易发生时,我们就能收集到超过 5000 维的数据特征,其中包含了数值和分类特征。
为了构建模型的训练和测试数据集,我们对连续几个月在 O2O 交易中使用蚂蚁信用支付的用户数据进行采样来得到训练数据,并将往后几个月中相同场景下的数据作为测试数据。
数据集的详细信息如下表1所示,这是一个大规模的且类别不均衡任务。正如我们前面提到的,收集到的原始数据维度高达 5000 维,这其中可能包含一些不相关的特征属性,如果直接使用的话,整个训练过程将非常耗时,同时也将降低模型部署的效率。因此,我们使用 MART 模型来计算并选择我们所需的特征。
具体来说,首先我们用所有维度的特征来训练 MART 模型,然后计算出特征的重要性分数,以此选择相对重要的特征。实验结果表明,使用前 300 个特征重要性分数较高的特征,我们的模型能够达到相当有竞争力的性能,且在验证过程中进一步证明了特征的冗余性。因此,我们以特征重要性分数来过滤原始特征,并保留前300个特征作为我们模型训练所需。

表1:训练集和测试集的数据样本量
▌实验结果分析
我们在不同的评估标准下测试分布式深度森林模型的性能,并讨论具体的分析结果。
通用评估标准
在通用的评估标准下,包括 AUC 分数,F1 分数和 KS 分数,我们对比评估了 Logistic 回归模型 ( LR),深度神经网络 (DNN),多元加权回归树模型 (MART) 及我们的深度森林模型 (gcForest) 的性能,结果如下表2所示:

表2:通用评估标准下的实验对比结果
特定评估标准 (Recall)
对于正样本的回召率 ,我们对比评估了四种方法的性能,其结果如表3所示:

表3:特定评估标准下的实验对比结果。
PR 曲线
为了更直观地对比四种方法的检测性能,我们绘制了 PR (Precision-Recall) 曲线,如图5所示。我们能够清楚地看到,深度森林模型的 PR 曲线包含了其他所有方法,这意味着深度森林模型的检测性能要比其他方法的性能好得多,这进一步验证了深林模型的有效性。

图5:LR, DNN, MART 和 gcForest 模型的 PR 曲线
经济效益
在不同的评估标准下,我们已经逐一分析了实验结果并验证了深度森林模型用于处理大规模任务的有效性。在套现欺诈行为的检测任务上,与之前最好的 MART 模型相比 (由 600 个树结构构成的 MART 模型),深度森林模型 (以 MART 模型为基础模块,每个 MART 模块只需 200 个树结构) 能够以更简单的结构带来更显著的经济效益,大大降低了经济损失。
模型鲁棒性分析
针对上述的评估标准,我们对不同的方法分别进行了鲁棒性分析,其结果如表4,表5 及图6所示,分别对应通用评价标准,特定评价标准 (Recall) 及 PR 曲线的鲁棒性分析结果。其中 gcForest-d 代表默认设置下的深度森林模型,而 gcForest-t 代表微调后的深度森林模型。

表4:通用标准下的实验对比结果 (鲁棒性分析)
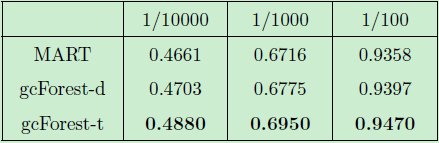
表5:特定标准下的实验对比结果 (鲁棒性分析)

图6:默认设置下的 gcForest-d,微调后的 gcForest-t 及 MART 模型的 PR 曲线
我们可以看到,默认设置下的 gcForest-d 模型的性能已经远远优于精调后的 MART 模型,而微调后的 gcForest-t 模型则能够取得更好的性能。
-
人工智能
+关注
关注
1797文章
47928浏览量
240976 -
机器学习
+关注
关注
66文章
8457浏览量
133190 -
蚂蚁金服
+关注
关注
0文章
44浏览量
7453
原文标题:周志华团队和蚂蚁金服合作:用分布式深度森林算法检测套现欺诈
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
分布式云化数据库有哪些类型
基于ptp的分布式系统设计
HarmonyOS Next 应用元服务开发-分布式数据对象迁移数据权限与基础数据
特力康输电线路分布式故障定位监测装置:提升电网可靠性的关键

分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进

浅谈屋顶分布式光伏发电技术的设计与应用
解决电网逆流难题,实现分布式光伏发电全部自发自用

分布式光纤测温是什么?应用领域是?
分布式光纤声波传感技术的工作原理
分布式输电线路故障定位中的分布式是指什么

红色警戒!深度伪造欺诈蔓延全球,ADVANCE.AI助力出海企业反欺诈新升级
分布式能源是什么意思?分布式能源有什么优势?
HarmonyOS开发实例:【分布式数据服务】
HarmonyOS实战案例:【分布式账本】





 工商网监
工商网监
评论