 大神教你怎么用Python抓取婚恋网用户数据,用决策树生成自己择偶观
大神教你怎么用Python抓取婚恋网用户数据,用决策树生成自己择偶观
最近在看《机器学习实战》的时候萌生了一个想法,自己去网上爬一些数据按照书上的方法处理一下,不仅可以加深自己对书本的理解,顺便还可以在github拉拉人气。刚好在看决策树这一章,书里面的理论和例子让我觉得这个理论和选择对象简直不能再贴切,看完长相看学历,看完学历看收入。如果可以从婚恋网站上爬取女性的数据信息,手动给她们打标签,并根据这些数据构建决策树,不就可以找出自己的择偶模式了吗!github项目:huatian-funny,下面就详细的阐释一下。
数据爬取
之前在世纪佳缘上爬取过类似的数据,总体的感觉是上面的用户数据要么基本不填要么一看就很假,周围的一些老司机建议可以在花田网上看下,数据质量确实高很多,唯一的缺点就是上面的数据不给爬,搜索用户的API需要登录,而且只显示三十多个用户的信息。刚好我需要的数据也很少,就把搜索条件划分的很细,每次取到的数据很小,但最终汇集的数量还是相当可观的,最终获取了位置在上海年龄22-27共计2000个左右的用户数据。填写好spider.py中的用户名和密码,直接运行这个文件就可以爬取数据,因为数据量不大,很快就可以运行完毕,存储在mongodb中的数据如下:
爬虫用到的工具是requests,流程上也很简单,先发送登陆请求获取cookie,然后调用搜索API获取数据,拿到的数据是json格式,不需要任何转换直接存储mongodb,非常的方便,唯一想吐槽的就是花田搜索API接口竟然用的是POST方式,太没有专业水准了。稍微提一下如何用request获取cookie,用Session构建一个session对象,用这个对象发送登陆请求后,之后的请求都会自动带上登陆返回的cookie,使用起来非常的简单。
给用户打标签
由于决策树属于监督学习,需要一个给定的标签,因此需要自己根据用户的外貌、年龄、学历等多个维度的判断给出一个标签,最后生成的决策树在一定程度上就可以反映自己的择偶标准。针对女性的标签很简单粗暴,只有满意和不满意两种,有兴趣的同学可以按照真实的情况设置更多的标签,例如优秀、一般、备胎、不合格等等。因为外貌是选择对象过程中一个必不可少的要素,把相貌量化至关重要,因为没有相关的工具根据头像进行评分,只能个人主观进行量化,采用了当下非常流行的十分制。
为了增加打标签的效率,专门写了一个桌面窗口,运行mark.py即可,运行结果如下。(tkinter是一个坑,调代码的时间够我把整个数据集看好几遍了,不过真的用起来的时候还是挺有意思的)
备注:因为刚开始看的很多用户只有头像、年龄、身高、工资、学历这五个信息,所以整个过程中只参考了这五个维度进行评价,下面的决策树也是根据这五个维度进行处理。
训练数据
决策树
机器学习中,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。
理论方面我可以参考《机器学习实战》第三章或者这篇博客,很浅显易懂的解释了具体的原理,我就不赘述了。
结果展示
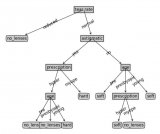
代码参考的是《机器学习实战》,针对现实自己做了一些优化调整,和原来的代码不是完全相同,运行train.py就可以显示出结果,如下:
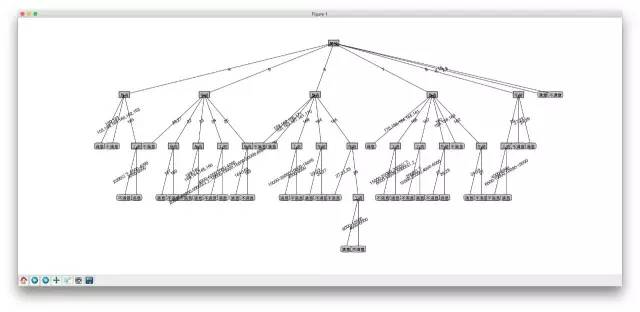
因为线很挤,调了很久只能拿到这个效果了。到这儿已经很清晰明了的阐明了主题,我就是一个外貌党,颜值高的pass,颜值低的忽略,不高不低的考虑的相当纠结。有兴趣的同学可以自己试一试。
-
机器学习
+关注
关注
66文章
8458浏览量
133222 -
python
+关注
关注
56文章
4812浏览量
85154
原文标题:Python抓取婚恋网用户数据,用决策树生成自己择偶观
文章出处:【微信号:WUKOOAI,微信公众号:悟空智能科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
关于决策树,这些知识点不可错过
怎样使用UNICO生成具有多个决策树的UCF文件呢
决策树的生成资料
决策树的构建设计并用Graphviz实现决策树的可视化
机器学习:决策树--python
机器学习之决策树生成详解
决策树的原理和决策树构建的准备工作,机器学习决策树的原理
什么是决策树模型,决策树模型的绘制方法





 工商网监
工商网监
评论