 高维空间逼近最近邻评测
高维空间逼近最近邻评测
最近邻方法是机器学习中一个非常流行的方法,它的原理很容易理解:邻近的数据点是相似的数据点,更可能属于同一分类。然而,在高维空间中快速地应用最近邻方法,却是非常有挑战性的工作。
全球最大的流媒体音乐服务商Spotify需要向上面的海量用户推荐音乐,其中就用到了最近邻方法。也就是在高维空间、大型数据集上应用最近邻方法。
由于维度高、数据规模大,直接应用最近邻方法并不可行,因此,最佳实践是使用逼近方法搜索最近邻。这方面有不少开源库,比如Spotify开源的Annoy库。Annoy库的作者Erik Bernhardsson在开发Annoy的过程中发现,尽管有成百上千的使用逼近方法搜索最近邻的论文,却很少能找到实践方面的比较。因此,Erik开发了ANN-benchmarks,用来评测逼近最近邻(approximate nearest neighbor,ANN)算法。
评估的实现
Annoy Spotify自家的C++库(提供Python绑定)。Annoy最突出的特性是支持使用静态索引文件,这意味着不同进程可以共享索引。
FLANN 加拿大英属哥伦比亚大学出品的C++库,提供C、MATLAB、Python、Ruby绑定。
scikit-learn 知名的Python机器学习库scikit-learn提供了LSHForest、KDTree、BallTree实现。
PANNS 纯Python实现。已“退休”,作者建议使用MRPT。
NearPy 纯Python实现。基于局部敏感哈希(Locality-sensitive hashing,简称LSH,一种降维方法)。
KGraph C++库,提供Python绑定。基于图(graph)算法。
NMSLIB (Non-Metric Space Library) C++库,提供Python绑定,并且支持通过Java或其他任何支持Apache Thrift协议的语言查询。提供了SWGraph、HNSW、BallTree、MPLSH实现。
hnswlib(NMSLIB项目的一部分) 相比当前NMSLIB版本,hnswlib内存占用更少。
RPForest 纯Python实现。主要特性是不需要在模型中储存所有索引的向量。
FAISS Facebook出品的C++库,提供可选的GPU支持(基于CUDA)和Python绑定。包含支持搜寻任意大小向量的算法(甚至包括可能无法在RAM中容纳的向量)。
DolphinnPy 纯Python实现。基于超平面局部敏感哈希算法。
Datasketch 纯Python实现。基于MinHash局部敏感哈希算法。
PyNNDescent 纯Python实现。基于k-近邻图构造(k-neighbor-graph construction)。
MRPT C++库,提供Python绑定。基于稀疏随机投影(sparse random projection)和投票(voting)。
NGT: C++库,提供了Python、Go绑定。提供了PANNG实现。
数据集
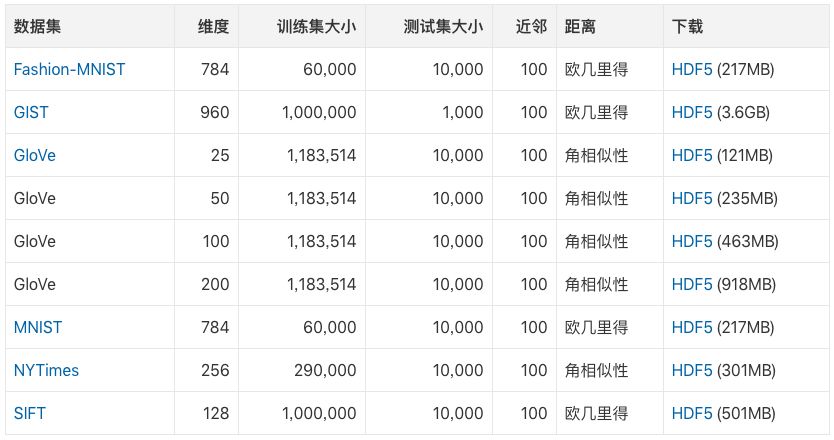
ANN-benchmarks提供了一些预先处理好的数据集。
结果
Erik提供了在AWS EC2机器(c5.4xlarge)上运行测试的结果——跑了好几天才跑完,费用约100美元。
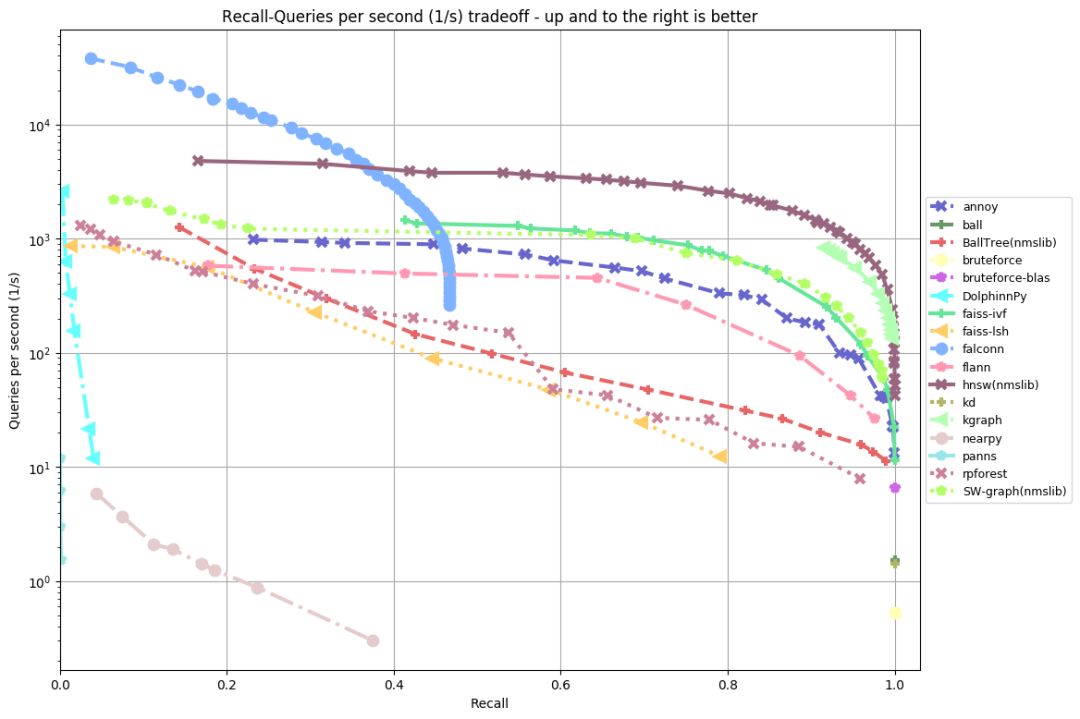
glove-100-angular
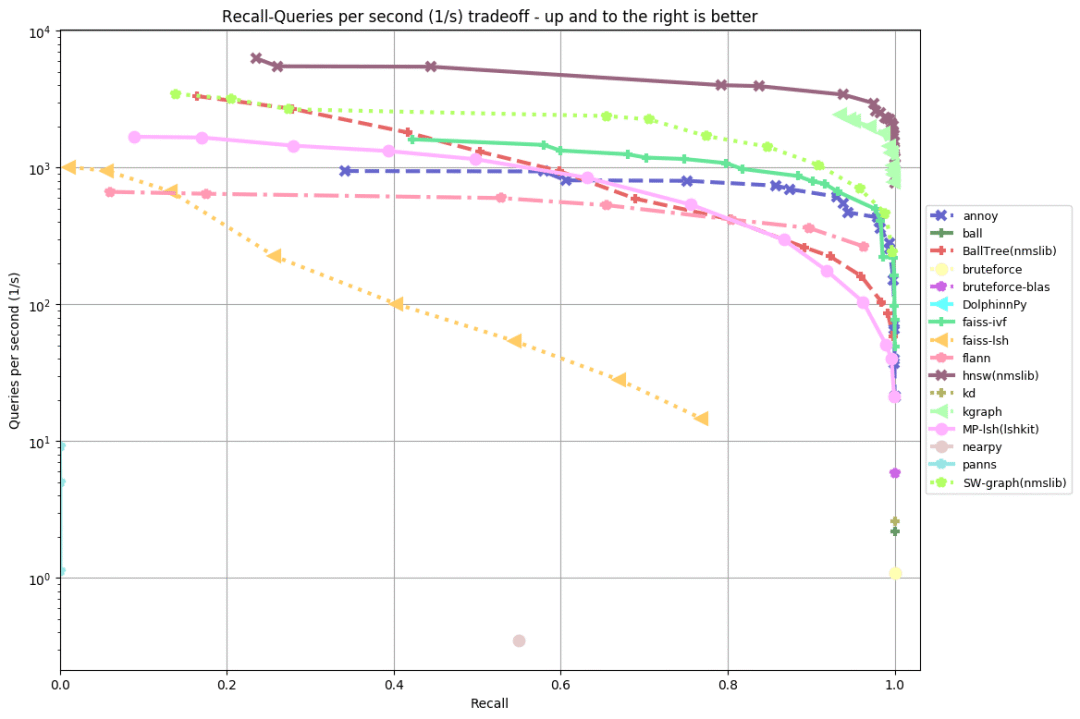
sift-128-euclidean
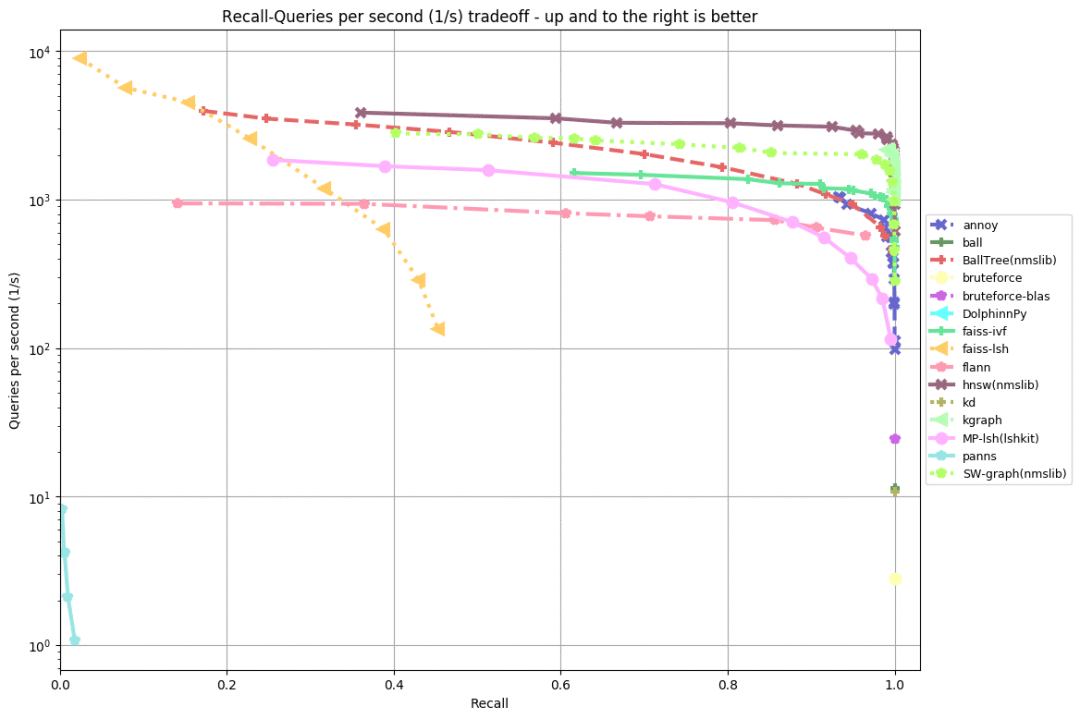
fashion-mnist-784-euclidean
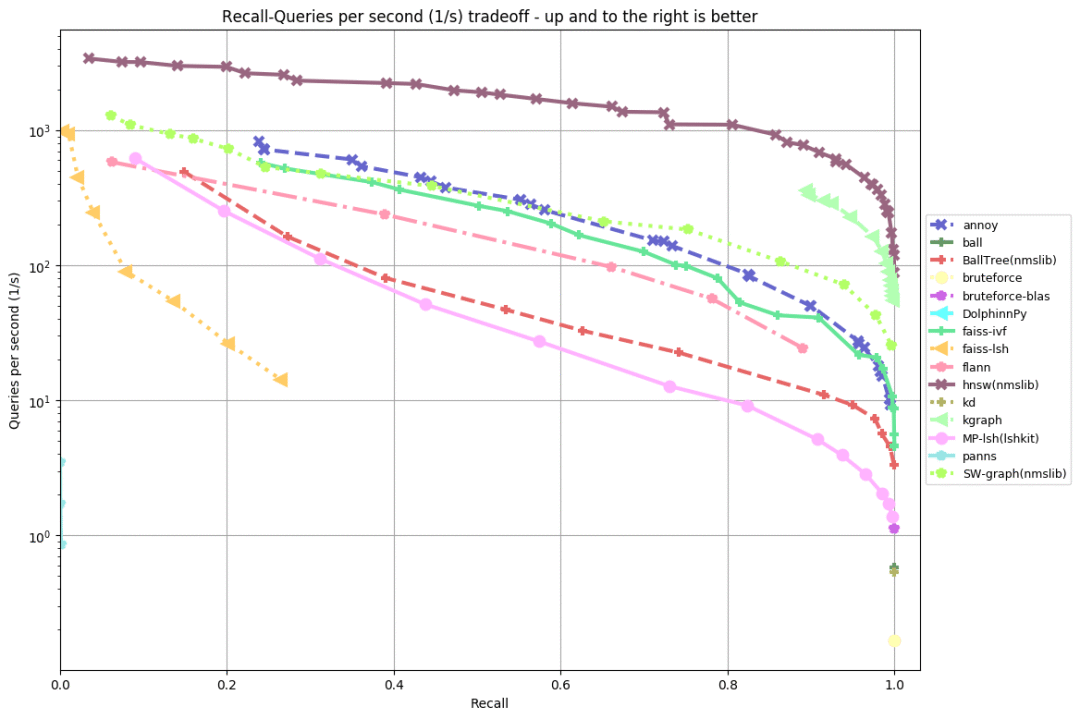
gist-960-euclidean
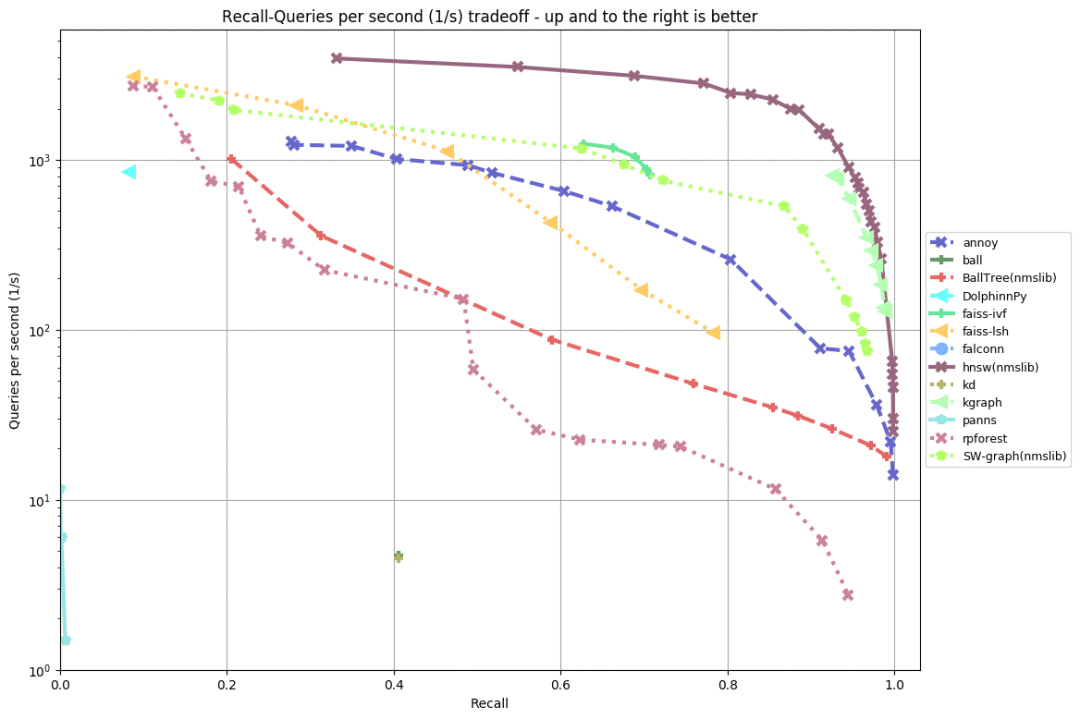
nytimes-256-angular
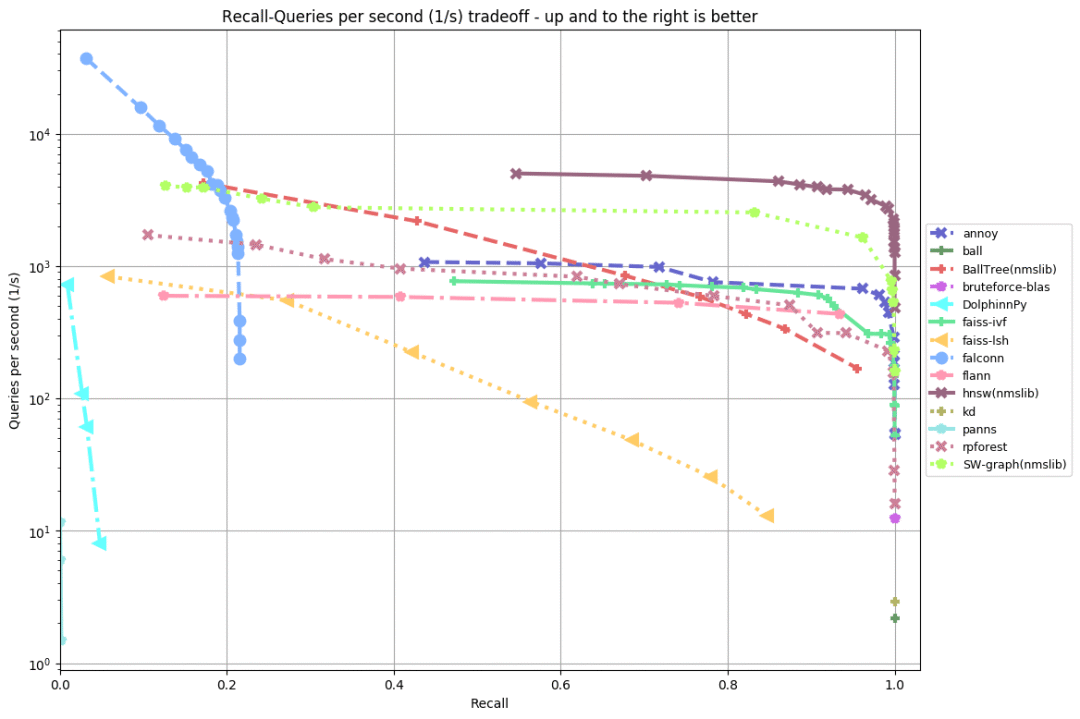
glove-25-angular
从以上评测可以看出(越靠上、靠右,成绩越好),几乎在所有数据集上,排名前五的实现为:
HNSW(NMSLIB的低内存占用版本),比Annoy快10倍。
KGraph位于第二,和HNSW的差距不算很大。和HNSW一样,KGraph也是基于图(graph)的算法。
SW-graph,源自NWSLIB的另一个基于图的算法。
FAISS-IVF,源自Facebook的FAISS。
Annoy
在“评估的实现”一节中,我们看到,有不少使用局部敏感哈希(LSH)的库。这些库的表现都不是很好。在之前进行的一次评测中,FALCONN表现非常好(唯一表现优良的使用局部敏感哈希的库)。但是这次评测中,FALCONN看上去退步得很厉害——原因未明。
从这次评测来看,基于图的算法是当前最先进的算法(名列三甲的算法全都基于图),特别是HNSW表现突出。
-
机器学习
+关注
关注
66文章
8461浏览量
133446
原文标题:高维空间最近邻逼近搜索算法评测
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python实现k-近邻算法
基于Hilbert曲线的近似k-最近邻查询算法
基于子空间样本选择的最近凸包分类器
改进的共享型最近邻居聚类算法
基于SRM自组织多区域覆盖的可拒绝近邻分类算法研究
Spark下的并行多标签最近邻算法
激光散乱点云K最近邻搜索算法
路网环境下的最近邻查询技术
基于最近邻距离分布的空间聚类方法
最近邻的随机非线性降维
人工智能机器学习之K近邻算法(KNN)
解决复杂数据最近邻问题的通用方法
一种基于自然最近邻的密度峰值聚类算法

基于改进的Canopu和共享最近邻的聚类算法






 工商网监
工商网监
评论