 一个完整的机器学习项目
一个完整的机器学习项目
创建测试集
在这个阶段就分割数据,听起来很奇怪。毕竟,你只是简单快速地查看了数据而已,你需要再仔细调查下数据以决定使用什么算法。这么想是对的,但是人类的大脑是一个神奇的发现规律的系统,这意味着大脑非常容易发生过拟合:如果你查看了测试集,就会不经意地按照测试集中的规律来选择某个特定的机器学习模型。再当你使用测试集来评估误差率时,就会导致评估过于乐观,而实际部署的系统表现就会差。这称为数据透视偏差。
理论上,创建测试集很简单:只要随机挑选一些实例,一般是数据集的 20%,放到一边:
import numpy as np def split_train_test(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices]
然后可以像下面这样使用这个函数:
>>> train_set, test_set = split_train_test(housing, 0.2) >>> print(len(train_set), "train +", len(test_set), "test") 16512 train + 4128 test
这个方法可行,但是并不完美:如果再次运行程序,就会产生一个不同的测试集!多次运行之后,你(或你的机器学习算法)就会得到整个数据集,这是需要避免的。
解决的办法之一是保存第一次运行得到的测试集,并在随后的过程加载。另一种方法是在调用np.random.permutation()之前,设置随机数生成器的种子(比如np.random.seed(42)),以产生总是相同的洗牌指数(shuffled indices)。
但是如果数据集更新,这两个方法都会失效。一个通常的解决办法是使用每个实例的ID来判定这个实例是否应该放入测试集(假设每个实例都有唯一并且不变的ID)。例如,你可以计算出每个实例ID的哈希值,只保留其最后一个字节,如果该值小于等于 51(约为 256 的 20%),就将其放入测试集。这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。新的测试集会包含新实例中的 20%,但不会有之前位于训练集的实例。下面是一种可用的方法:
import hashlib def test_set_check(identifier, test_ratio, hash): return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5): ids = data[id_column] in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash)) return data.loc[~in_test_set], data.loc[in_test_set]
不过,房产数据集没有ID这一列。最简单的方法是使用行索引作为 ID:
housing_with_id = housing.reset_index() # adds an `index` column train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
如果使用行索引作为唯一识别码,你需要保证新数据都放到现有数据的尾部,且没有行被删除。如果做不到,则可以用最稳定的特征来创建唯一识别码。例如,一个区的维度和经度在几百万年之内是不变的,所以可以将两者结合成一个 ID:
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"] train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
Scikit-Learn 提供了一些函数,可以用多种方式将数据集分割成多个子集。最简单的函数是train_test_split,它的作用和之前的函数split_train_test很像,并带有其它一些功能。首先,它有一个random_state参数,可以设定前面讲过的随机生成器种子;第二,你可以将种子传递给多个行数相同的数据集,可以在相同的索引上分割数据集(这个功能非常有用,比如你的标签值是放在另一个DataFrame里的):
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
目前为止,我们采用的都是纯随机的取样方法。当你的数据集很大时(尤其是和属性数相比),这通常可行;但如果数据集不大,就会有采样偏差的风险。当一个调查公司想要对 1000 个人进行调查,它们不是在电话亭里随机选 1000 个人出来。调查公司要保证这 1000 个人对人群整体有代表性。例如,美国人口的 51.3% 是女性,48.7% 是男性。所以在美国,严谨的调查需要保证样本也是这个比例:513 名女性,487 名男性。这称作分层采样(stratified sampling):将人群分成均匀的子分组,称为分层,从每个分层去取合适数量的实例,以保证测试集对总人数有代表性。如果调查公司采用纯随机采样,会有 12% 的概率导致采样偏差:女性人数少于 49%,或多于 54%。不管发生那种情况,调查结果都会严重偏差。
假设专家告诉你,收入中位数是预测房价中位数非常重要的属性。你可能想要保证测试集可以代表整体数据集中的多种收入分类。因为收入中位数是一个连续的数值属性,你首先需要创建一个收入类别属性。再仔细地看一下收入中位数的柱状图(图 2-9)(译注:该图是对收入中位数处理过后的图):
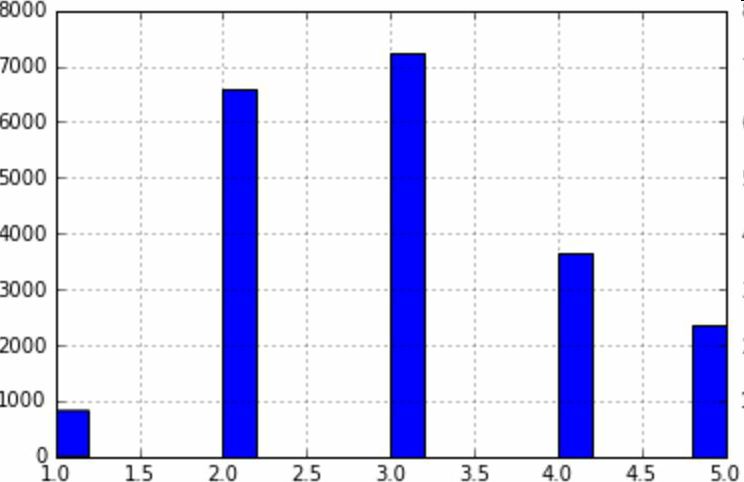
图 2-9 收入分类的柱状图
大多数的收入中位数的值聚集在 2-5(万美元),但是一些收入中位数会超过 6。数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要。否则,对分层重要性的评估就会有偏差。这意味着,你不能有过多的分层,且每个分层都要足够大。后面的代码通过将收入中位数除以 1.5(以限制收入分类的数量),创建了一个收入类别属性,用ceil对值舍入(以产生离散的分类),然后将所有大于 5的分类归入到分类 5:
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5) housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
现在,就可以根据收入分类,进行分层采样。你可以使用 Scikit-Learn 的StratifiedShuffleSplit类:
from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index]
检查下结果是否符合预期。你可以在完整的房产数据集中查看收入分类比例:
>>> housing["income_cat"].value_counts() / len(housing) 3.0 0.350581 2.0 0.318847 4.0 0.176308 5.0 0.114438 1.0 0.039826 Name: income_cat, dtype: float64
使用相似的代码,还可以测量测试集中收入分类的比例。图 2-10 对比了总数据集、分层采样的测试集、纯随机采样测试集的收入分类比例。可以看到,分层采样测试集的收入分类比例与总数据集几乎相同,而随机采样数据集偏差严重。
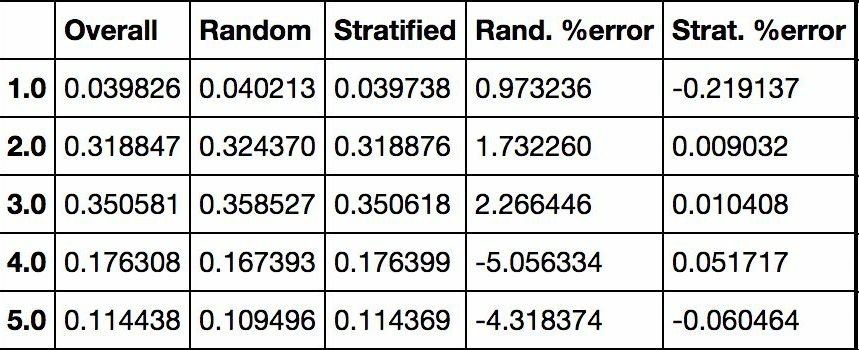
图 2-10 分层采样和纯随机采样的样本偏差比较
现在,你需要删除income_cat属性,使数据回到初始状态:
for set in (strat_train_set, strat_test_set): set.drop(["income_cat"], axis=1, inplace=True)
我们用了大量时间来生成测试集的原因是:测试集通常被忽略,但实际是机器学习非常重要的一部分。还有,生成测试集过程中的许多思路对于后面的交叉验证讨论是非常有帮助的。接下来进入下一阶段:数据探索。
数据探索和可视化、发现规律
目前为止,你只是快速查看了数据,对要处理的数据有了整体了解。现在的目标是更深的探索数据。
首先,保证你将测试集放在了一旁,只是研究训练集。另外,如果训练集非常大,你可能需要再采样一个探索集,保证操作方便快速。在我们的案例中,数据集很小,所以可以在全集上直接工作。创建一个副本,以免损伤训练集:
housing = strat_train_set.copy()
地理数据可视化
housing.plot(kind="scatter", x="longitude", y="latitude")
因为存在地理信息(纬度和经度),创建一个所有街区的散点图来数据可视化是一个不错的主意(图 2-11):
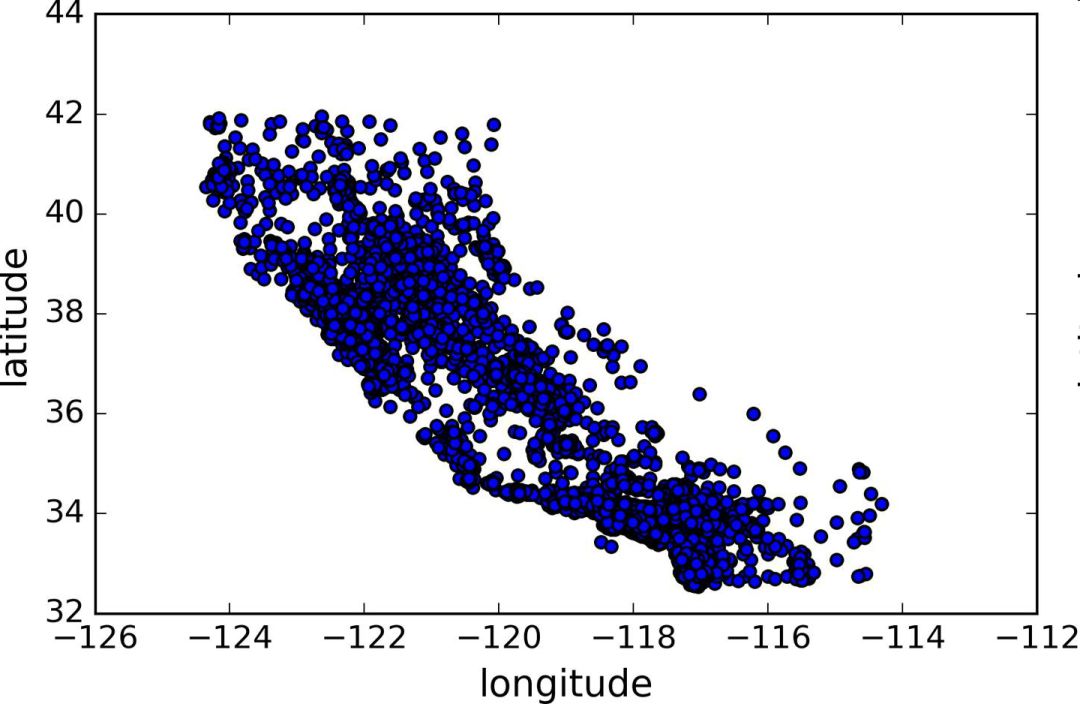
图 2-11 数据的地理信息散点图
这张图看起来很像加州,但是看不出什么特别的规律。将alpha设为 0.1,可以更容易看出数据点的密度(图 2-12):
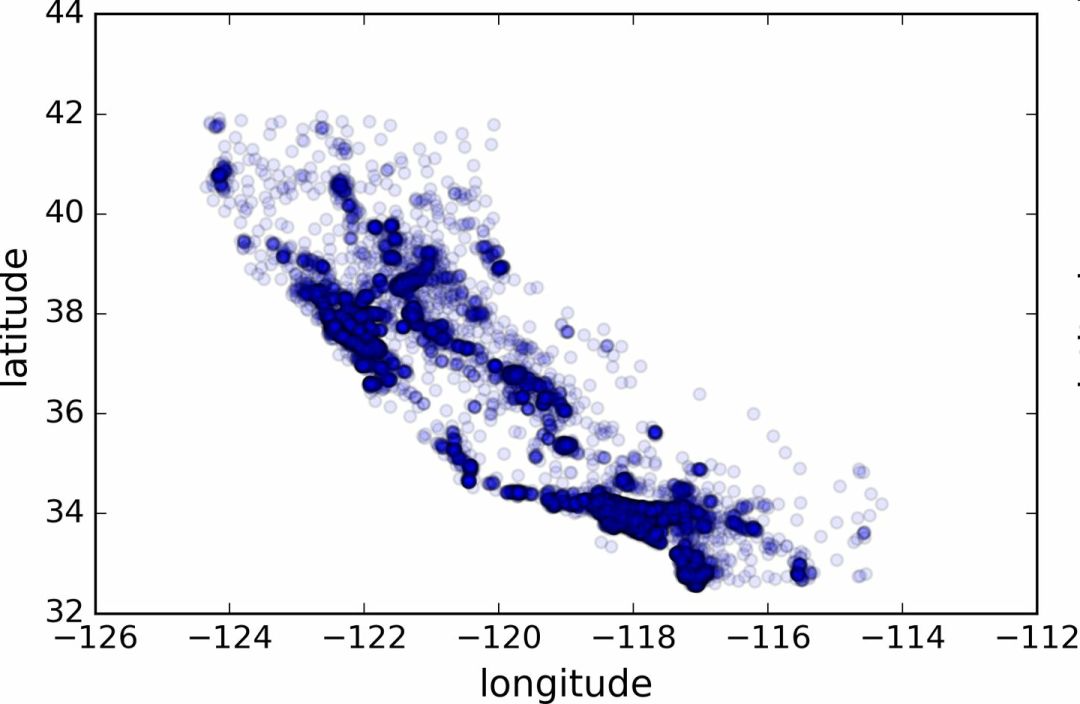
图 2-12 显示高密度区域的散点图
现在看起来好多了:可以非常清楚地看到高密度区域,湾区、洛杉矶和圣迭戈,以及中央谷,特别是从萨克拉门托和弗雷斯诺。
通常来讲,人类的大脑非常善于发现图片中的规律,但是需要调整可视化参数使规律显现出来。
现在来看房价(图 2-13)。每个圈的半径表示街区的人口(选项s),颜色代表价格(选项c)。我们用预先定义的名为jet的颜色图(选项cmap),它的范围是从蓝色(低价)到红色(高价):
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, s=housing["population"]/100, label="population", c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, ) plt.legend()
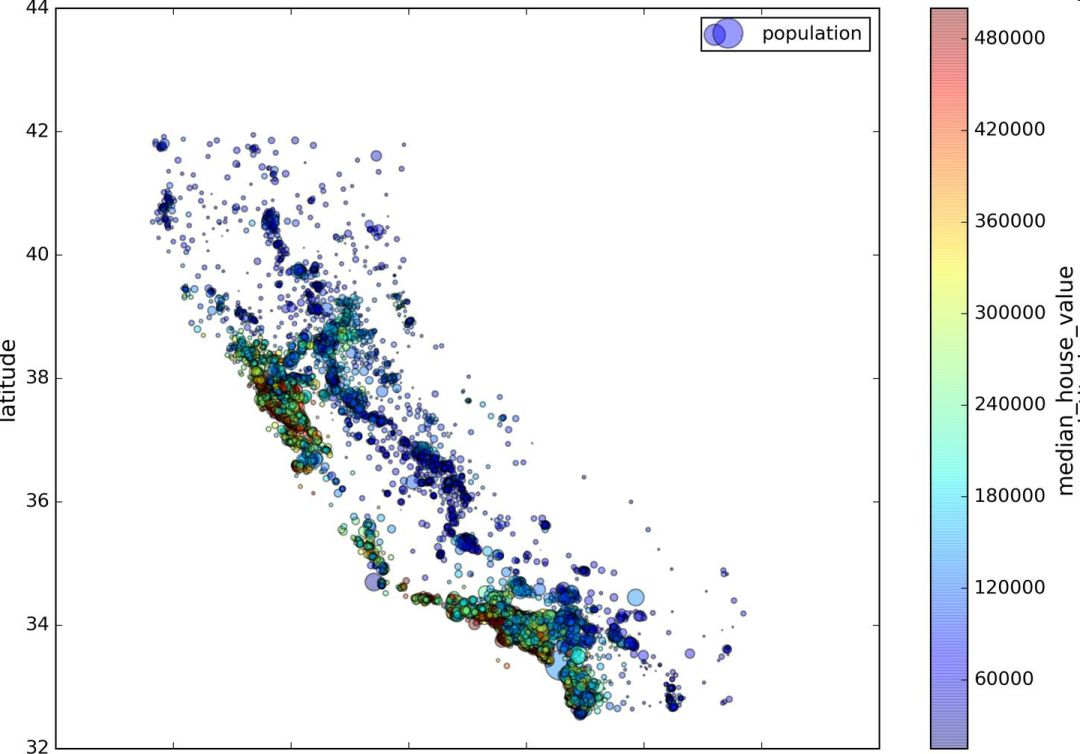
图 2-13 加州房价
这张图说明房价和位置(比如,靠海)和人口密度联系密切,这点你可能早就知道。可以使用聚类算法来检测主要的聚集,用一个新的特征值测量聚集中心的距离。尽管北加州海岸区域的房价不是非常高,但离大海距离属性也可能很有用,所以这不是用一个简单的规则就可以定义的问题。
查找关联
因为数据集并不是非常大,你可以很容易地使用corr()方法计算出每对属性间的标准相关系数(standard correlation coefficient,也称作皮尔逊相关系数):
corr_matrix = housing.corr()
现在来看下每个属性和房价中位数的关联度:
>>> corr_matrix["median_house_value"].sort_values(ascending=False) median_house_value 1.000000 median_income 0.687170 total_rooms 0.135231 housing_median_age 0.114220 households 0.064702 total_bedrooms 0.047865 population -0.026699 longitude -0.047279 latitude -0.142826 Name: median_house_value, dtype: float64
相关系数的范围是 -1 到 1。当接近 1 时,意味强正相关;例如,当收入中位数增加时,房价中位数也会增加。当相关系数接近 -1 时,意味强负相关;你可以看到,纬度和房价中位数有轻微的负相关性(即,越往北,房价越可能降低)。最后,相关系数接近 0,意味没有线性相关性。图 2-14 展示了相关系数在横轴和纵轴之间的不同图形。
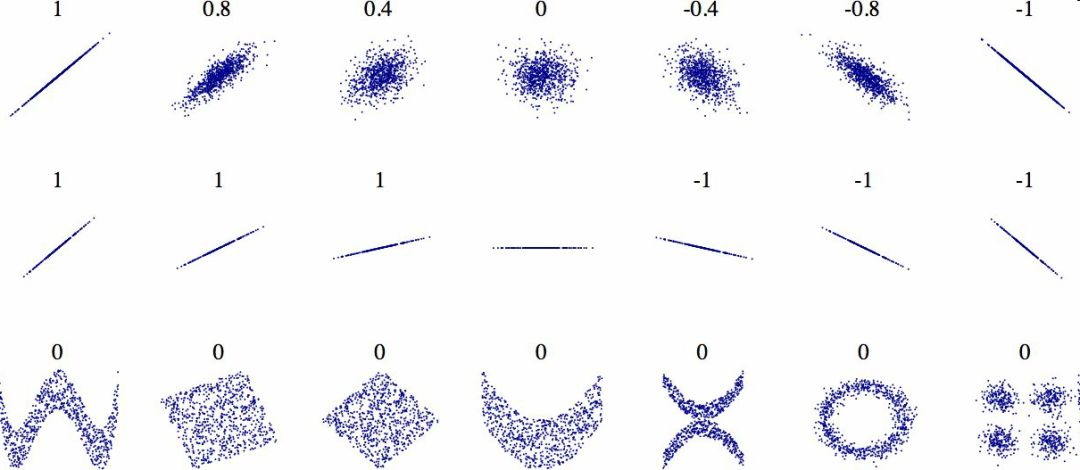
图 2-14 不同数据集的标准相关系数(来源:Wikipedia;公共领域图片)
警告:相关系数只测量线性关系(如果x上升,y则上升或下降)。相关系数可能会完全忽略非线性关系(例如,如果x接近 0,则y值会变高)。在上面图片的最后一行中,他们的相关系数都接近于 0,尽管它们的轴并不独立:这些就是非线性关系的例子。另外,第二行的相关系数等于 1 或 -1;这和斜率没有任何关系。例如,你的身高(单位是英寸)与身高(单位是英尺或纳米)的相关系数就是 1。
另一种检测属性间相关系数的方法是使用 Pandas 的scatter_matrix函数,它能画出每个数值属性对每个其它数值属性的图。因为现在共有 11 个数值属性,你可以得到11 ** 2 = 121张图,在一页上画不下,所以只关注几个和房价中位数最有可能相关的属性(图 2-15):
from pandas.tools.plotting import scatter_matrix attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"] scatter_matrix(housing[attributes], figsize=(12, 8))
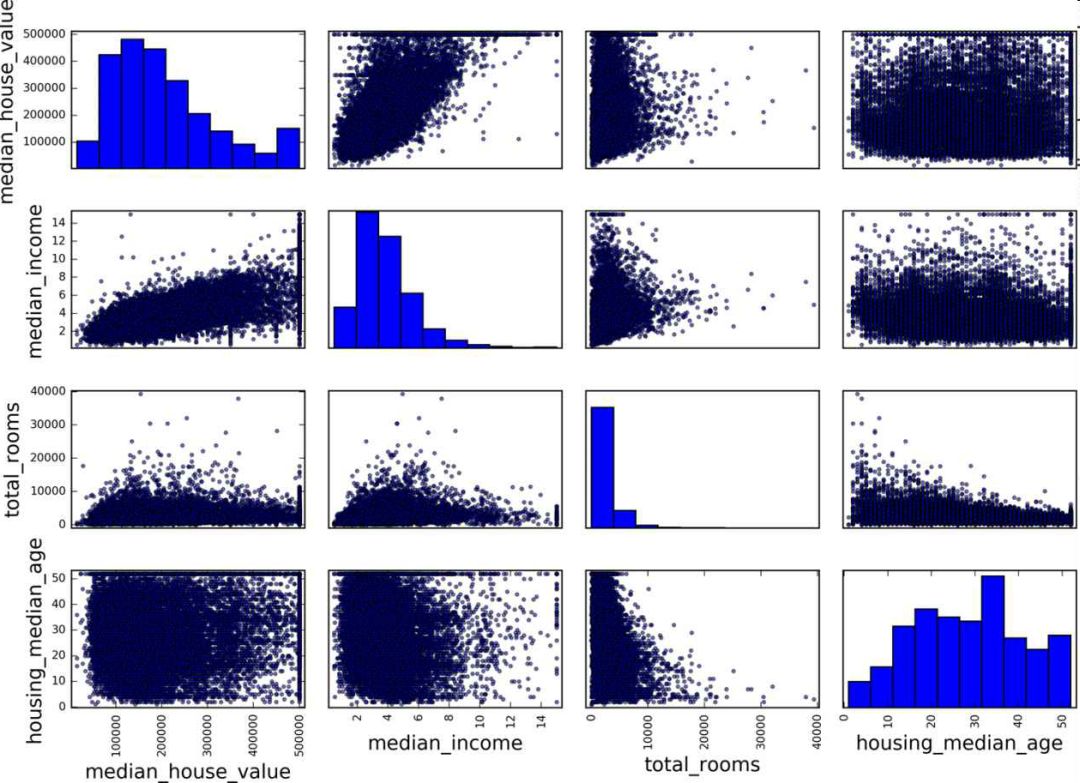
图 2-15 散点矩阵
如果 pandas 将每个变量对自己作图,主对角线(左上到右下)都会是直线图。所以 Pandas 展示的是每个属性的柱状图(也可以是其它的,请参考 Pandas 文档)。
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大(图 2-16):
housing.plot(kind="scatter", x="median_income",y="median_house_value", alpha=0.1)
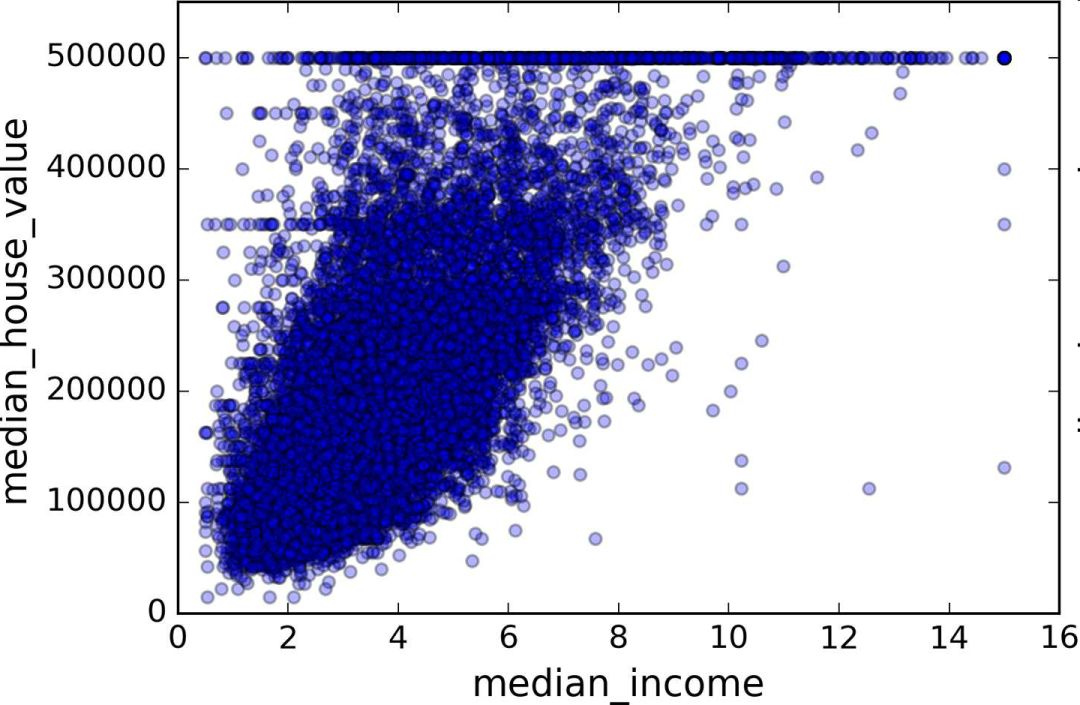
图 2-16 收入中位数 vs 房价中位数
这张图说明了几点。首先,相关性非常高;可以清晰地看到向上的趋势,并且数据点不是非常分散。第二,我们之前看到的最高价,清晰地呈现为一条位于 $500000 的水平线。这张图也呈现了一些不是那么明显的直线:一条位于 $450000 的直线,一条位于 $350000 的直线,一条在 $280000 的线,和一些更靠下的线。你可能希望去除对应的街区,以防止算法重复这些巧合。
属性组合试验
希望前面的一节能教给你一些探索数据、发现规律的方法。你发现了一些数据的巧合,需要在给算法提供数据之前,将其去除。你还发现了一些属性间有趣的关联,特别是目标属性。你还注意到一些属性具有长尾分布,因此你可能要将其进行转换(例如,计算其log对数)。当然,不同项目的处理方法各不相同,但大体思路是相似的。
给算法准备数据之前,你需要做的最后一件事是尝试多种属性组合。例如,如果你不知道某个街区有多少户,该街区的总房间数就没什么用。你真正需要的是每户有几个房间。相似的,总卧室数也不重要:你可能需要将其与房间数进行比较。每户的人口数也是一个有趣的属性组合。让我们来创建这些新的属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"] housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"] housing["population_per_household"]=housing["population"]/housing["households"]
现在,再来看相关矩阵:
>>> corr_matrix = housing.corr() >>> corr_matrix["median_house_value"].sort_values(ascending=False) median_house_value 1.000000 median_income 0.687170 rooms_per_household 0.199343 total_rooms 0.135231 housing_median_age 0.114220 households 0.064702 total_bedrooms 0.047865 population_per_household -0.021984 population -0.026699 longitude -0.047279 latitude -0.142826 bedrooms_per_room -0.260070 Name: median_house_value, dtype: float64
看起来不错!与总房间数或卧室数相比,新的bedrooms_per_room属性与房价中位数的关联更强。显然,卧室数/总房间数的比例越低,房价就越高。每户的房间数也比街区的总房间数的更有信息,很明显,房屋越大,房价就越高。
这一步的数据探索不必非常完备,此处的目的是有一个正确的开始,快速发现规律,以得到一个合理的原型。但是这是一个交互过程:一旦你得到了一个原型,并运行起来,你就可以分析它的输出,进而发现更多的规律,然后再回到数据探索这步。
-
机器学习
+关注
关注
66文章
8373浏览量
132391 -
数据可视化
+关注
关注
0文章
457浏览量
10237
原文标题:【翻译】Sklearn 与 TensorFlow 机器学习实用指南 —— 第2章 一个完整的机器学习项目(中)
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用python进行第一个机器学习项目(详细教程篇)
创建一个边缘机器学习系统
人工智能:你知道这八个超赞的机器学习项目吗?
一个机器学习系统的需求建模与决策选择






 工商网监
工商网监
评论