 一个高效的低延迟视频语义分割算法
一个高效的低延迟视频语义分割算法
在自动驾驶领域,目前基于深度学习的分割算法运算负荷仍然较大,不能有效移植到嵌入式端,在车辆上运行。在保证分割精度的情况下,如何才能达到高实时性?CVPR 2018商汤科技论文解读第4期为您带来解读。
以下是在自动驾驶场景理解领域,商汤科技发表的一篇亮点报告(Spotlight)论文,提出极低延迟性的视频语义分割算法。
简介
近年来由于深度神经网络,尤其全卷经神经网络的迅速发展,图像语义分割取得了飞速的进展,但是如何高效的实现视频语义分割仍然是一个极富挑战性的问题。其困难在于:
与图像分割相比,视频分割通常涉及更多的数据。比如,视频每秒通常包含15~30帧,分析视频因而需要更多的计算资源;
许多实际应用(如自动驾驶)中的视频分割模块需要实现视频分割的低延迟性。
对于视频语义分割任务,大部分现有工作关注如何在每帧计算量和分割精度之间的达到一个平衡点,却并没有深入的思考和探讨算法延迟性这个因素。现有工作可以被大致分为两类:
高层特征的时序建模方法
中间层特征传播的方法
前者主要在一个完整的逐帧模型上增加一些提取时序信息的操作,因此不能减少计算量。后者(如Clockwork Net、Deep Feature Flow等工作)通过重用历史帧的特征来加速计算,这类方法可以减少视频整体计算量,然而忽略了延迟方面的因素。这类方法的延迟和精度对比(如图1所示),可以看出这类方法很难同时实现低延迟和高精度。我们的工作则立足降低每帧平均计算量的同时,实现分割的高精度,降低算法的最大延迟。
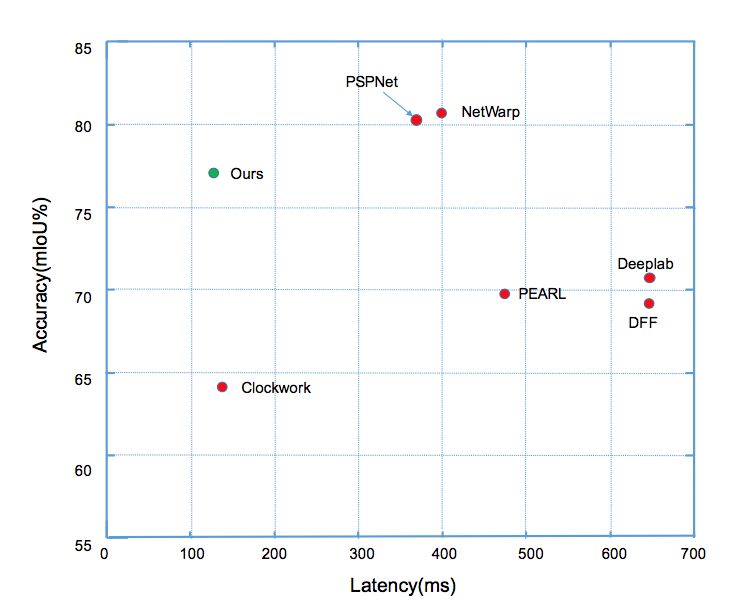
图1:
Cityscapes数据集上
不同方法延迟和分割精度的对比
算法核心思想
本文算法使用视频分割中经典的基于关键帧调度的模式来有效平衡计算量和精度。具体来说,如果当前处理帧为关键帧,则使用整个分割网络来获得语义分割的标签,如图2左部分所示;如果当前帧不为关键帧,则变换分割网络高层历史帧特征为当前帧高层特征,再使用分割网络的语义分类操作获得当前帧的语义标签,如图2右部分所示。关键帧的选择和特征跨帧传播两个操作均基于同样的网络低层特征,具体操作在之后章节详述。在划分分割网络结构时,算法尽量保证低层网络的运行时间远小于高层网络,(如图2所示)低层网络耗时61ms,而高层网络耗时300ms。这样考虑的出发点在于:
因低层网络的计算代价很小,算法可以基于低层网络提取的特征,增加少部分额外的计算来完成关键帧选择和特征跨帧传播;
当前帧的低层特征同样包含当前帧的信息,可以互补来自不同时间的传播特征;
所有的操作均复用了逐帧模型的结构,算法整体模型更加简洁。
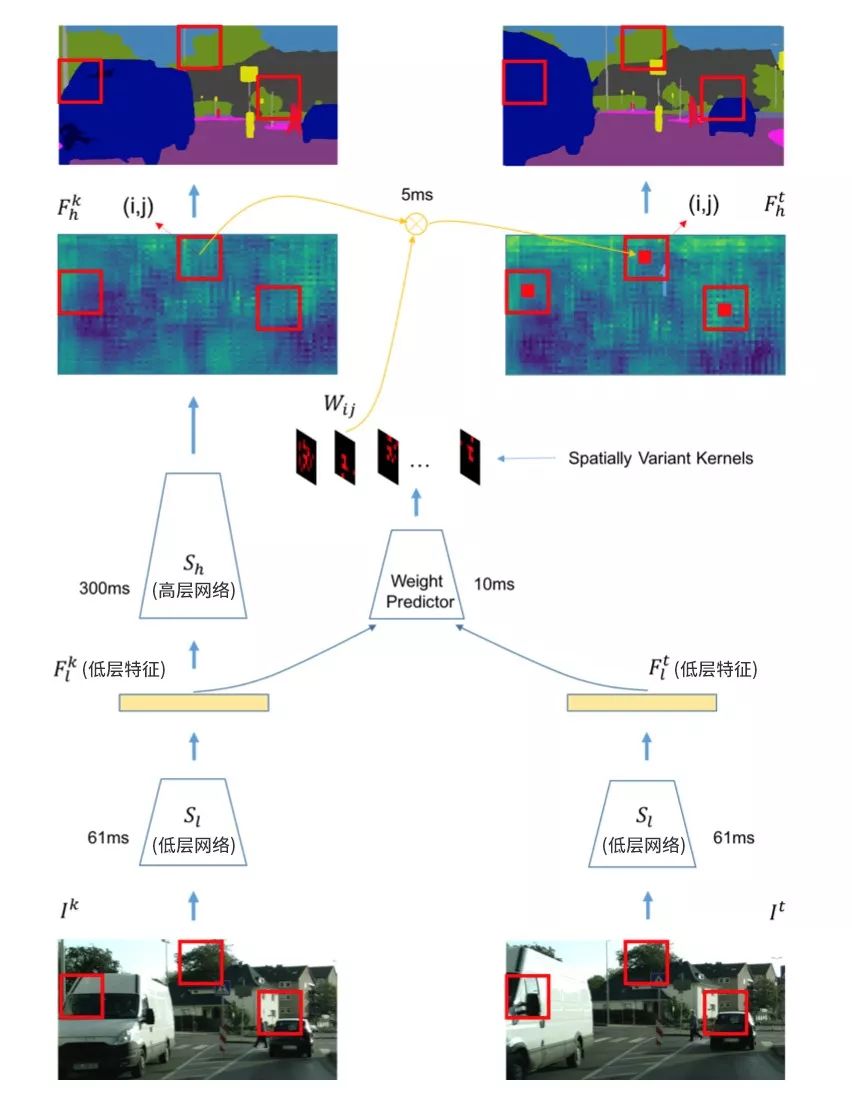
图2:
自适应特征传播模块
自适应特征跨帧传播
特征传播关注如何从历史帧传播高层特征到当前帧,降低模型总体计算量,先前的变换方法主要分为两类:
基于图像或底层特征获取的光流信息,跨帧传播不同帧的语义分类特征。这类方法虽然有效,但是计算光流往往代价太大,而获得当前帧的语义标签并不需要严格的点到点映射。
平移不变性卷积。这种操作在每个位置均使用相同的卷积核来映射特征,因此不能适应不同位置的内容变化。
本文设计了一个位置相关的卷积操作来进行跨帧特征传播。它的计算量相对较低,同时又能适应不同位置的特征进行自适应传播。不同位置的卷积核参数通过一个小的网络回归学习获得(如图2中weight predictor所示),其能很好的适应不同空间位置内容的变化。整体特征传播模块(包含当前帧低层网络、卷积核预测和空间变化卷积)包含两大优势:
总体计算量相较高层网络部分计算量大为减小,因而可以快速的获得当前帧的语义标签;
可以很好的保持视频邻近帧的抖动或者其他快速变化,实验结果表明这种卷积操作融合方法能够有效的提升7% mIOU的精度。
整体结果如表1所示,结果展示了本文算法复用逐帧网络的优势,可以从低层网络提取的特征来互补跨帧传播的特征。

表1:
不同特征传播模块对最终分割精度的影响
自适应关键帧调度
视频处理算法中,一个好的关键帧选择算法能够随视频内容变化自适应的调整关键帧选择频率,在视频内容变化大的时间区间更多的选择关键帧,而在视频变化缓慢的区间较少的选择关键帧,从而在有效保持视频流中信息的前提下,降低整体计算量。现有的关键帧调度算法分为固定长度调度和基于阈值调度两种方案,前者每隔n帧选择一次关键帧,这种方式不能适应不同视频帧之间内容的变化,后者则通过计算当前帧高层特征和历史帧高层特征之间的差值,通过设定一个阈值来决定是否是否选择当前帧为关键帧,这种方法能一定程度的适应不同帧之间的内容变化,但是特征的差值容易波动,较难设定一个统一的阈值。
本文算法使用当前帧语义标签和前一个关键帧语义标签的差异值来作为视频内容变化程度的判断依据,如图3所示,若当前帧距上一个关键帧越远,则语义标签的差值就越大。当差值超过某个阈值的时候,则选择该帧作为关键帧。但是直接计算这样一个差异值较为困难,本文在Cityscapes和Camvid两个数据集上发现低层特征和语义标签的变化值有很大的关联,因而利用低层特征来预测这样该差值,即输入历史帧低层特征和当前帧低层特征到一个回归器来回归该差异值。不同的关键帧选择策略的结果如图4所示,所有的策略均采用本文提出的自适应特征传播方法,可以看出提出的自适应关键帧调度方法明显优于基于固定间隔和基于高层特征差值阈值的调度策略。
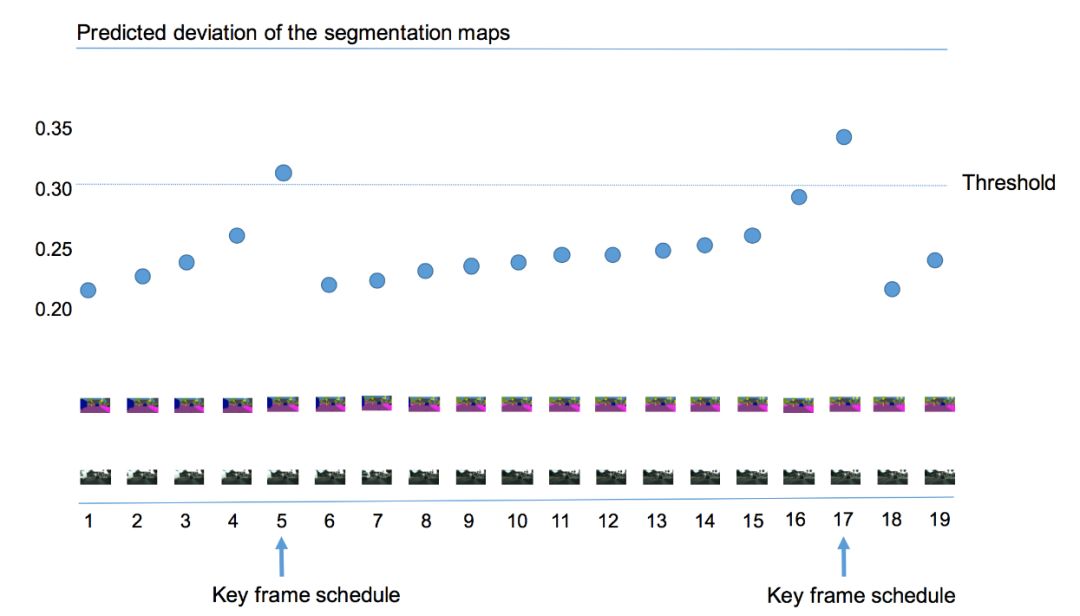
图3:
自适应的关键帧选择
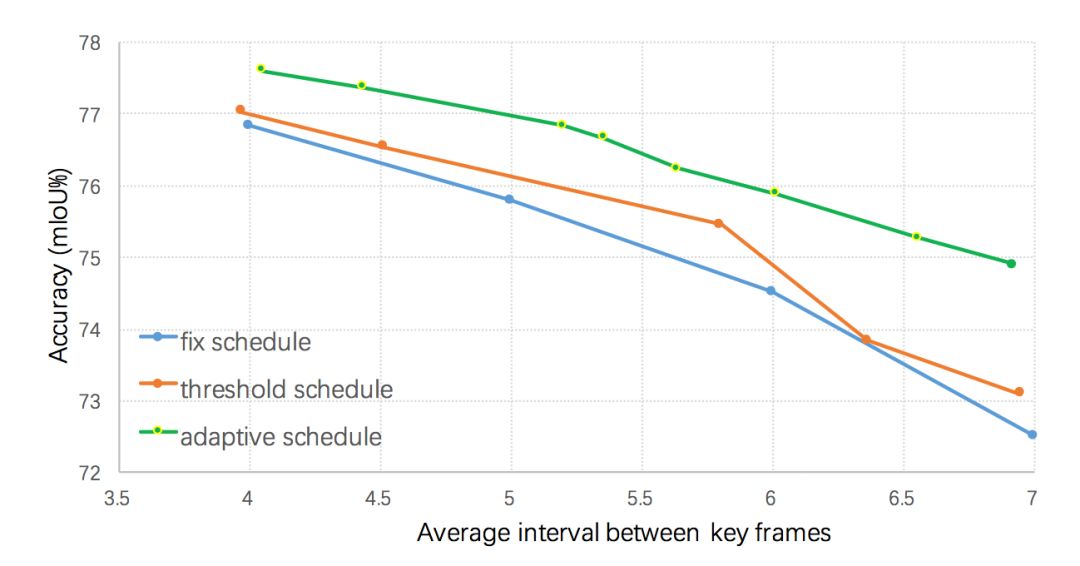
图4:
不同调度策略对最终分割性能的影响
整体系统框架
本文算法整体框架如图5所示,当视频的序列帧不断输入时,在第一帧时刻,进行初始化操作,即输入图片帧给整个网络,获得低层特征和高层特征。在接下来的时刻t进行自适应的计算,首先计算低层特征:输入和上一个关键帧低层特征至自适应关键帧选择模块,判断当前帧是否为关键帧。若为关键帧,则输入底层特征至高层网络获得高层特征;否则输入底层特征至自适应特征传播模块获得当前帧高层特征,进而通过语义分类获得当前帧语义标签。
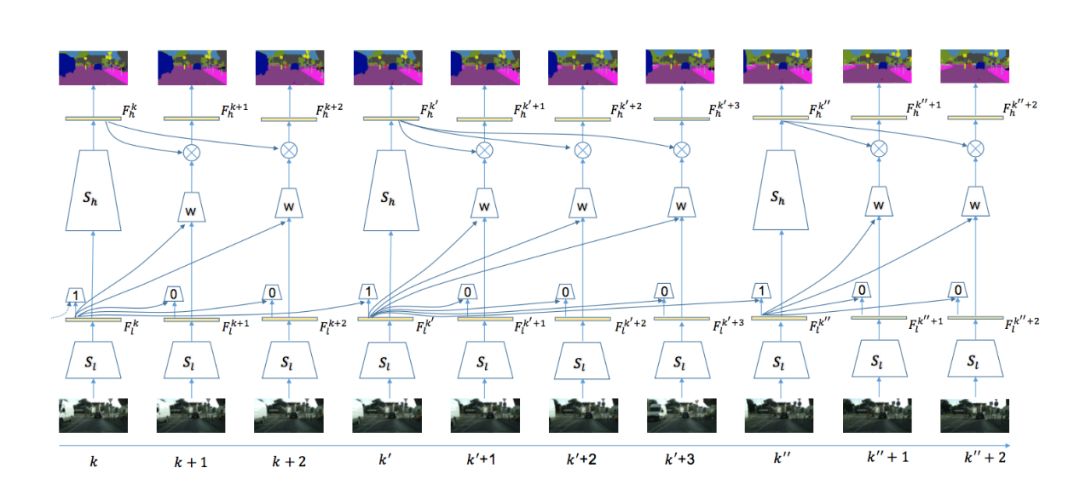
图5:
系统整体框架示意图
该系统极大的减少了整体耗时,其中判断关键帧操作耗时仅20ms,跨帧特征传播仅需38ms,而高层网络计算高层特征则需要299ms。通过这种方式,整个系统可以明显的降低系统的平均每帧计算量(如表2所示),自适应调度策略和自适应特征传播方法可以把每帧平均计算时间由360ms减为171ms,精度仅损失3.4% mIOU。
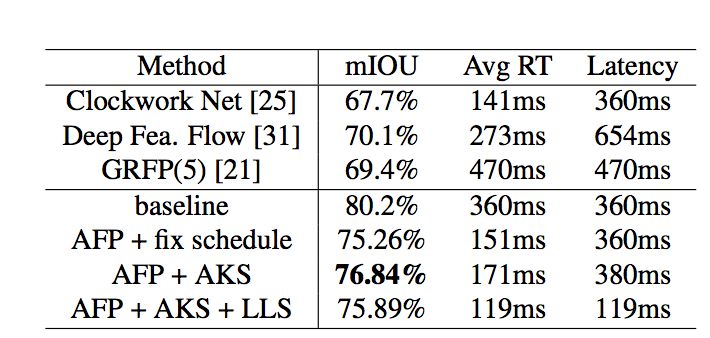
表2:
Cityscape数据集上
与目前先进方法结果的对比
同时本文设计了一种低延迟的调度策略进一步减少整体系统的延迟,适用于自动驾驶等需要及时响应的系统。具体而言,当前帧被判断为关键帧时,低延迟调度策略仍然从历史帧传播特征到当前帧并将其缓存为当前帧高层特征,同时启用一个后台线程来计算当前帧高层特征(如果直接运行高层网络部分会造成299ms的延迟),一旦计算完成就取代缓存的高层特征。实验结果表明(如表2所示),这种低延迟的调度策略能够将延迟由360ms降为119ms,同时只损失较小的分割精度(由78.84%降为75.89%)。
结论
本文提出了一个高效的低延迟视频语义分割算法,其主要由自适应特征传播和自适应关键帧调度模块组成。该算法在关注平衡精度和计算量的同时力求降低系统的延迟,Cityscapes和Camvid两个数据集上的实验结果证明了该方法的有效性。作者希望在未来工作中在模型压缩和模型设计方面进一步降低算法的总体延迟和计算量。
-
神经网络
+关注
关注
42文章
4789浏览量
101549 -
视频
+关注
关注
6文章
1964浏览量
73308 -
自动驾驶
+关注
关注
788文章
13994浏览量
167656
原文标题:CVPR 2018 | 商汤科技Spotlight论文详解:极低延迟性的视频语义分割
文章出处:【微信号:SenseTime2017,微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于TICA和GMM的视频语义概念检测算法
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割

语义分割算法系统介绍
语义分割方法发展过程

基于深度神经网络的图像语义分割方法

全局双边网络语义分割算法综述
PyTorch教程-14.9. 语义分割和数据集

深度学习图像语义分割指标介绍






 工商网监
工商网监
评论