 一款采用单位元精度的深度学习推论(inference)芯片原型
一款采用单位元精度的深度学习推论(inference)芯片原型
比利时研究机构Imec在近日举行的年度技术论坛(ITF BELGIUM 2018)上透露,该机构正在打造一款采用单位元精度的深度学习推论(inference)芯片原型;Imec并期望在明年收集采用创新资料型态与架构──采用存储器内处理器(processor-in-memory,PIM),或是Analog存储器结构(analog memory fabric)──的客户端装置有效性资料。
学术界已经研究PIM架构数十年,而该架构越来越受到资料密集的机器演算法欢迎,例如新创公司Mythic以及IBM Research都有相关开发成果。许多学术研究机构正在实验1~4位元的资料型别(data type),以减轻深度学习所需的沉重存储器需求;到目前为止,包括Arm等公司的AI加速器商用芯片设计都集中在8位元或更大容量的资料型别,部分原因是编程工具例如Google的TensorFlow缺乏对较小资料型别的支援。
Imec拥有在一家晶圆代工厂制作的40nm制程加速器逻辑部份,而现在是要在自家晶圆厂添加一个MRAM层;该机构利用SRAM模拟此设计的性能,并且评估5nm节点的设计规则。此研究是Imec与至少两家匿名IDM业者伙伴合作、仍在开发阶段的专案,从近两年前展开,很快制作了采用某种电阻式存储器(ReRAM)的65nmPIM设计原型。
该65nm芯片并非锁定深度学习演算法,虽然Imec展示了利用它启动一段迷人的电脑合成音乐;其学习模式是利用了根据以音乐形式呈现、从感测器所串流之资料的时间序列分析(time-series analysis)。而40nm低功耗神经网路加速器(Low-Energy Neural Network Accelerator,LENNA)则会锁定深度学习,在相对较小型的MRAM单元中运算与储存二进位权重。
Imec技术团队的杰出成员Diederik Verkest接受EE Times采访时表示:「我们的任务是定义出我们应该利用新兴存储器为机器学习开发什么样的半导体技术──或许我们会需要制程上的调整,」以取得最佳化结果。该机构半导体技术与系统部门执行副总裁An Steegen则表示:「AI会是制程技术蓝图演化的推手,因此Imec会在AI (以及PIM架构)方面下很多功夫──这方面的工作成果将会非常重要。」
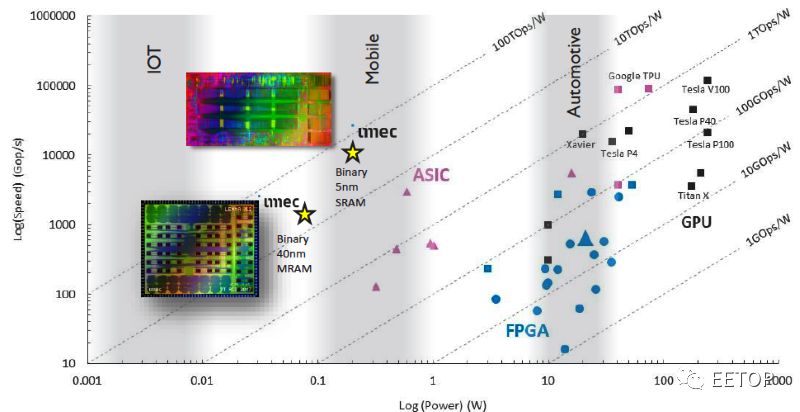
Imec声称其LENNA芯片在推论任务上的表现将超越现有的CPU与GPU
确实,如来自英国的新创公司Graphcore执行长Nigel Toon所言,AI标志着「运算技术的根本性转变」;该公司将于今年稍晚推出首款芯片。Toon在Imec年度技术论坛上发表专题演说时表示:「今日的硬体限制了我们,我们需要某种更灵活的方案…我们想看到能根据经验调整的(神经网路)模型;」他举例指出,两年前Google实习生总共花了25万美元电费,只为了在该公司采用传统x86处理器或Nvidia GPU的资料中心尝试最佳化神经网路模型。
实现复杂的折衷平衡
Imec希望LENNA能在关于PIM或Analog存储器架构能比需要存取外部存储器的传统架构节省多少能量方面提供经验;此外该机构的另一个目标,是量化采用二进制方案在精确度、成本与处理量方面的折衷(tradeoff)。
加速器芯片通常能在一些热门的测试上提供约90%的精确度,例如ImageNet竞赛;Verkest表示,单位元资料型别目前有10%左右的精度削减,「但如果你调整你的神经网路,可以达到最高85%~87%的精确度。」他原本负责督导Imec的逻辑制程微缩技术蓝图,在Apple挖脚该机构的第一个AI专案经理之后,又兼管AI专案。
Verkest表示,理论上Analog存储器单元应该能以一系列数值来储存权重(weights),但是「那些存储器元件的变异性有很多需要考量之处;」他指出,Imec的开发专案将尝试找出能提供最佳化精度、处理量与可靠度之间最佳化平衡的精度水准。
而Toon则认为聚焦于资料型别是被误导了:「低精度并没有某些人想得那么严重,存储器存取是我们必须修正之处;」他并未详细介绍Graphcore的解决方案,但声称该公司技术可提供比目前采用HBM2存储器的最佳GPU高40倍的存储器频宽。
在芯片架构方面,Imec的研究人员还未决定他们是要设计PIM或采用Analog存储器结构;后者比较像是一种Analog SoC,计算是在Analog区块处理,可因此减少或免除数位-Analog转换。不同种类的神经网路会有更适合的不同架构,例如卷积神经网路(CNN)会储存与重复使用权重,通常能以传统GPU妥善运作;归递神经网路(RNN)以及长短期记忆模型(long short-term memories,LSTMs)则倾向于在使用过后就抛弃权重,因此更适合运算式存储器结构

Imec可能会以存储器结构来打造LENNA,让运算留在Analog功能区块
新的平行架构非常难编程,因此大多数供应商正在尝试建立在TensorFlow等现有架构中摄取程式码的途径。而Graphcore则是打造了一种名为Poplar的软体层,旨在以C++或Python语言来完成这项工作;Toon表示:「我们把在处理器中映射图形(graphs)的复杂性推到编译器(也就是扮演该角色的Poplar)。」
Graphcore的客户很快就会发现该程序会有多简单或是多困难;这家新创公司预计在年中将第一款产品出货给一线大客户,预期他们会在今年底采用该款芯片执行大型云端供应商的服务。Toon声称,其加速器芯片将能把CNN的速度提升五至十倍,同时间采用RNN或LSTM的更复杂模型则能看到100倍的效能提升。
-
存储器
+关注
关注
38文章
7470浏览量
163699 -
加速器
+关注
关注
2文章
795浏览量
37827 -
AI芯片
+关注
关注
17文章
1871浏览量
34956
原文标题:Imec等多家公司正力促AI芯片设计最佳化
文章出处:【微信号:eetop-1,微信公众号:EETOP】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论