 优化嵌入式系统的工作负载,专用硬件来处理真正的人工智能算法
优化嵌入式系统的工作负载,专用硬件来处理真正的人工智能算法
Liran Bar, Director of Product Marketing, CEVA
移动设备上的人工智能已经不再依赖于云端连接,今年CES最热门的产品演示和最近宣布的旗舰智能手机都论证了这一观点。人工智能已经进入终端设备,并且迅速成为一个市场卖点。包括安全、隐私和响应时间在内的这些因素,使得该趋势必将继续扩大到更多的终端设备上。为了满足需求,几乎每个芯片行业的玩家都推出了不同版本、不同命名的人工智能处理器,像“深度学习引擎”、“神经处理器”、“人工智能引擎”等等。
然而,并非所有的人工智能处理器都是一样的。现实是,许多所谓的人工智能引擎就是传统的嵌入式处理器(利用CPU和GPU)加上一个矢量向量处理单元(VPU)。VPU单元是专门为高效执行与计算机视觉及深度学习相关的繁重计算负载而设计的。虽然拥有一个强大的、低功耗的VPU是嵌入式人工智能的重要组成部分,但这不是故事的全部。VPU是组成一个出色的人工智能处理器的众多组件之一。VPU虽然经过精心设计,也确实提供了所需的灵活性,但它不是一个AI处理器。这里还有一些其它功能对于人工智能处理前端化至关重要。
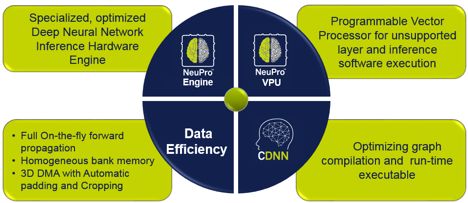
NeuProTM - CEVA人工智能(机器学习)整体解决方案’(图片来源于CEVA)
优化嵌入式系统的工作负载
在云计算处理过程中,采用浮点计算进行训练,定点计算进行推理,从而实现最大的准确性。用大型服务器群组进行数据处理,能耗和大小必须考虑,但他们相较于有边缘约束的处理几乎是无限的。在移动设备上,功耗、性能和面积(PPA)的可行性设计至关重要。因此在嵌入式SoC芯片上,优先采用更有效的定点计算。当将网络从浮点转换为定点时,会不可避免的损失掉一些精度。然而正确的设计可以最小化精度损失,可以达到与原始训练网络几乎相同的结果。
控制精度的方法之一是在8位和16位整数精度之间做出选择。虽然8位精度可以节省带宽和计算资源,但是许多商用的神经网络仍然需要采用16位精度以保证准确性。神经网络的每一层都有不同的约束和冗余,因此为每一层选择最佳的精度是至关重要的。

以层为单位选择最佳精度(图片来源于 CEVA)
针对开发人员和SoC设计者,一个工具可以自动输出优化的图形编译器和可执行文件,例如CEVA网络生成器,从上市时间的角度来看是一个巨大的优势。此外,保持为每一层选择最佳精度(8位或16位)的灵活性也是很重要的。这使每一层都可以在优化精度和性能之间进行权衡,然后一键生成高效和精确的嵌入式网络推理。
专用硬件来处理真正的人工智能算法
VPU使用灵活,但许多最常见的神经网络需要的大量带宽通道对标准处理器指令集提出了挑战。因此,必须有专门的硬件来处理这些复杂的计算。
例如NeuPro AI处理器包括专用的引擎处理矩阵乘法、完全连接层、激活层和汇聚层。这种先进的专用AI引擎结合完全可编程工作的NeuPro VPU,可以支持所有其它层类型和神经网络拓扑。这些模块之间的直接连接允许数据无缝交换,不再需要写入内存。此外,优化的DDR带宽和先进的DMA控制器采用动态流水线处理,可以进一步提高速度,同时降低功耗。
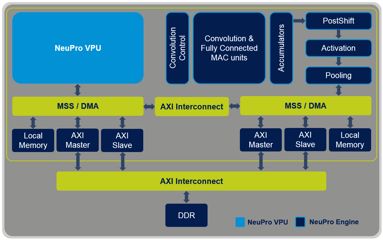
结合NeuPro 引擎和 NeuPro VPU的 NeuPro AI处理器框图(图片来源于:CEVA)
明天未知的人工智能算法
人工智能仍然是一个新兴且快速发展的领域。神经网络的应用场景快速增加,例如目标识别、语音和声音分析、5G通信等等。保持一种适应性的解决方案满足未来趋势是确保芯片设计成功唯一的途径。因此,满足现有算法的专用硬件肯定是不够的,还必须搭配一个完全可编程的平台。在算法一直不断改进的情况下,计算机模拟仿真是基于实际结果进行决策的关键工具,并且减少了上市时间。CDNN PC仿真包允许SoC设计人员在开发真实硬件之前,就可以使用PC环境权衡自己的设计。
另一个满足未来需求的宝贵特征是可扩展性。NeuPro AI产品家族可以应用于广泛的目标市场,从轻量型的物联网和可穿戴设备(2TOPs)到高性能的行业监控和自动驾驶应用(12.5 TOPs)。
在移动端实现旗舰AI处理器的竞赛已经开始。许多人快速赶上了这一趋势,使用人工智能作为自己产品的卖点,但并不是所有产品里都具备相同的智能水平。如果想要创建一个在不断发展的人工智能领域保持“聪明”的智能设备,应该确保在选择AI处理器时,检查上述提到的所有特性。
-
人工智能
+关注
关注
1792文章
47409浏览量
238924 -
嵌入式处理器
+关注
关注
0文章
255浏览量
30759 -
机器学习
+关注
关注
66文章
8424浏览量
132766
原文标题:为什么某些嵌入式 AI 处理器比其它更智能
文章出处:【微信号:CEVA-IP,微信公众号:CEVA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论