 三种典型的神经网络以及深度学习中的正则化方法应用于无人驾驶
三种典型的神经网络以及深度学习中的正则化方法应用于无人驾驶
兰州大学在读硕士研究生,主攻无人驾驶,深度学习;兰大未来计算研究院无人车团队骨干,在改自己的无人车,参加过很多无人车Hackathon,喜欢极限编程。
在前几十年,神经网络并没有受到人们的重视,直到深度学习的出现,人们利用深度学习解决了不少实际问题(即一些落地性质的商业应用),神经网络才成为学界和工业界关注的一个焦点。本文以尽可能直白,简单的方式介绍深度学习中三种典型的神经网络以及深度学习中的正则化方法。为后面在无人驾驶中的应用做铺垫。
▌深度学习的能力
近期在学术领域存在这许多批判深度学习的言论(参考Gary Marcus的文章:https://arxiv.org/ftp/arxiv/papers/1801/1801.00631.pdf),深度学习在一些学者看来并不是通往通用人工智能的道路。但是,作为关注行业应用的研究者和工程师,我们并不需要关注深度学习到底是不是通往最终的通用人工智能的道路,我们只需要知道,深度学习到底能不能够解决我们行业的一些问题(通过传统的软件工程很难解决的问题)?答案是能,正是因为深度学习有着这样的能力,它才成为人工智能研究领域历史上第一次为各大商业公司追逐的技术(以往的人工智能大多是实验室产品,从未吸引巨头的大量资本投入)。商业公司追逐利益,追逐商业化,一项技术能够为业内大量公司热捧,说明其已经具备在某些应用行业商业化,产品化的能力,那么我们首先来了解一下深度学习现在已经具备的“产品力”:
图像识别与分类
传统的计算机视觉技术在处理图像识别问题时往往需要人为设计特征,要识别不同的类别,就要设计不同的特征,要识别猫和狗,就要分别为猫和狗设计特征,而这个过程是非常麻烦的,我们以猫和狗为例:

上图是猫和狗的照片,可以说,光是为猫和狗两个类别的识别设计特征就需要耗费大量的精力,并且还得是“猫狗专家”才能做这件事情。那么,当要识别的类别上升到1000类的时候呢?传统的视觉算法的识别精度将会更低。
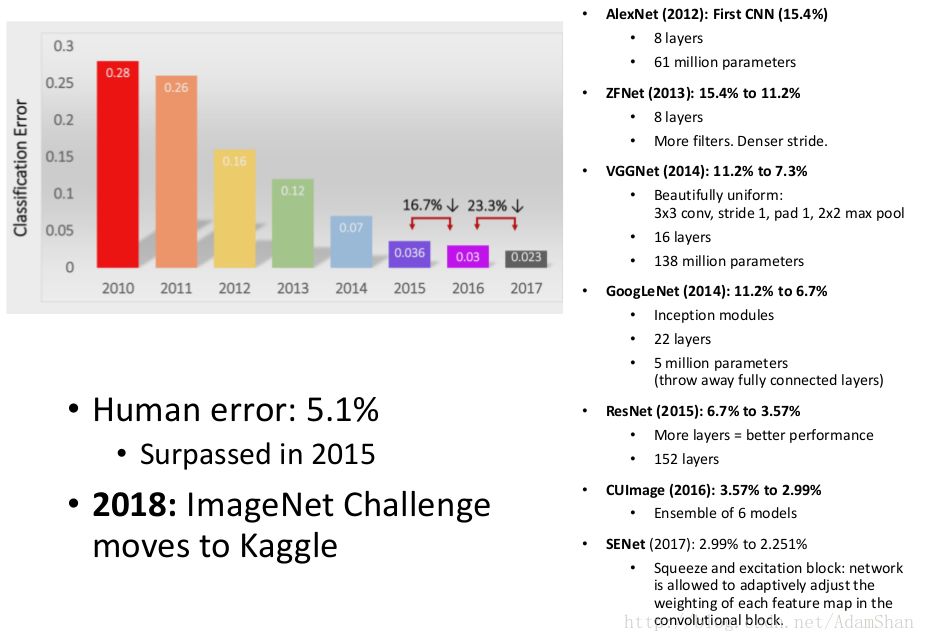
深度学习取得的第一个重大的突破就在ImageNet的识别挑战上。
ImageNet是一个拥有1400万张图片的巨大数据集,基于ImageNet数据集,ILSVRC(ImageNet Large Scale Visual Recognition Challenge)挑战赛每年举办一次。
自2012年AlexNet在ILSVRC上以远超第二名的识别率打破当年的记录以后,深度学习在ImageNet数据集上的识别率在近两年取得了一个又一个的突破。到2015年,ResNet的top-5识别率正式超过人类:
目标检测
像素级别的场景分割
视频字幕生成

游戏和棋牌

语音识别,文本生成,黑白影片自动着色,雅尔塔游戏……
深度学习有着极强的表示能力,能够处理复杂的任务,自然,我们需要使用深度学习来解决无人驾驶中一直以来的问题(基于深度学习的计算机视觉,基于深度学习的决策,基于强化学习的决策等等)。下面我们就开始深度学习的相关基础。
▌深度前馈神经网络——为什么要深?
在第九篇博客的末尾其实我们已经接触了深度前馈神经网络,我们使用一个规模很大的深度前馈网络来解决MNIST手写字识别问题,我们的这个网络取得了98%98%的识别率。简单来说,深度前馈网络就是早前的三层BP网络的“加深版”,如图所示:
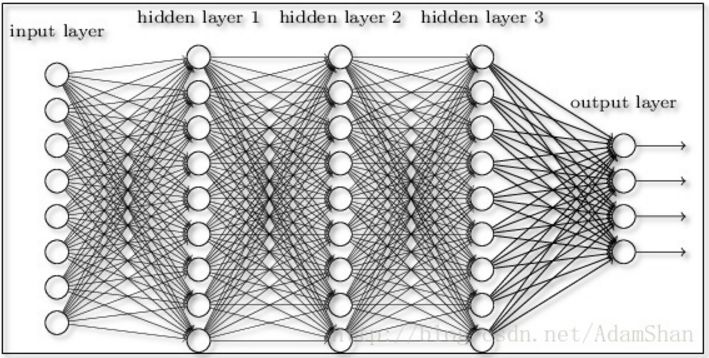
其中的层被我们称为全连接层。那么根据前面的神经网络的介绍我们知道,即使仅仅使用3层的神经网络,我们就能够拟合任意函数了,神经网络在设计的时候往往遵循奥卡姆剃刀原则,即我们往往使用最简单的结构来建模,那么为什么要加深网络的层数呢?
这个问题要从两个方面来看:一是大数据下的模型训练效率,一是表示学习。
大数据下的模型训练效率
有人把深度学习突破的起因归结于三个要素:
神经网络理论(一直以来的理论基础)
大量数据(得益于互联网的发展)
当代更强的并行计算能力(以GPU计算为代表)
其中的大量数据是深度神经网络能够在性能上取得成功的一个重要因素,传统机器学习算法在数据量增大到一定的数量级以后似乎会陷入一个性能的瓶颈(即使是基于结构风险最小化的支持向量机,其性能也会在数据量到达一定程度以后饱和),但是神经网路似乎是可以不断扩容的机器学习算法,数据量越大,可以通过增加神经元的个数以及隐含层的层数,训练更加强大的神经网络,其变化趋势大致如下:
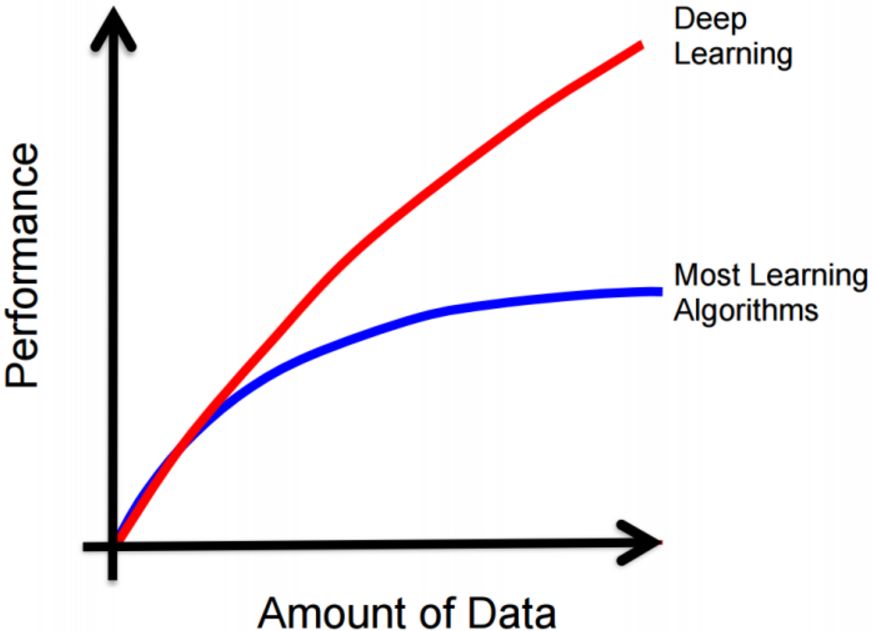
但是我们之前的文章也提到,当前已经可以证明,仅仅是简单的三层神经网络,通过增加隐含层神经元数量,理论上也可以拟合任意函数。那么我们为什么不直接使用单纯的三层网络结构,只增加隐含层神经元数量来提高模型容量,从而拟合复杂问题呢?
单纯的增加单层神经元数量能够是的模型具有更加强的表示能力,但是,相比于增加层数,每层使用相对少的神经元的策略,前者在实际训练中训练成功的难度更大,包含大量隐含层神经元的三层网络的过拟合问题难以控制,并且要达到相同的性能,深层神经网络的结构往往要比三层网络需要的神经元更少。
表示学习
另一种对深度学习前若干层作用的解释就是表示学习。深度学习=深度表示学习(特征学习),下图是一个多层卷积网络在输入图像以后,神经网络隐含层神经元激活的可视化结果:
如图,神经网络的前若干层实际上发挥这特征提取和表示建立的作用,区别与传统机器学习方法的人为设计特征,神经网络的特征设计是伴随着神经网络的训练而进行的,是一个自动的表示建立过程。从图中我们还能发现,越靠近输入端的层(越底层)提取的特征越简单,层数越高建立的特征越复杂。比如说图中,第一层提取了“边缘”特征,第二层则提取了轮廓特征,那么到了第三个隐含层,通过组合简单的底层特征,综合出了更加高级的表示,提取的是识别目标的局部特征。通过对特征的逐层抽象化,神经网络的层数越多,其能够建立的特征表示也就越丰富。
▌应用于深度神经网络的正则化技术
当神经网络的隐含层数和神经元数量增大时,随之而来的是参数数量的大幅度增大。这是的我们的神经网络更加容易过拟合,即模型在训练集上表现好,但是泛化能力差。在机器学习中,许多策略显式地被设计为减少测试误差(可能会以增大训练误差为代价)。这些策略被统称为正则化。
下面我们介绍四种常见的正则化技术,它们分别是:
数据集增强(Data Agumentation)
提前终止(Early Stopping)
参数范数惩罚(Parameter Norm Penalties)
Dropout
数据集增强
增强机器学习鲁棒性的最直观的一个策略就是使用更多的数据来训练模型,即数据集增强。然而,在现实情况下,我们的数据是有限的,所以我们往往通过创建假数据来增加我们的数据集合,而对于某些机器学习任务而言(如图像分类),创建假数据是非常简单的,下面我们以MNIST手写字为例来说明:
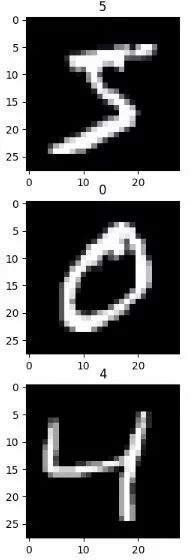
上图中的三个字符是MNIST数据集的训练集中的三个数字,对于图像这样的高维并且包含巨大的可变性的数据,我们可以对数据进行简单的平移,旋转,缩放等等来产生新的数据。
def expend_training_data(train_x, train_y): """ Augment training data """ expanded_images = np.zeros([train_x.shape[0] * 5, train_x.shape[1], train_x.shape[2]]) expanded_labels = np.zeros([train_x.shape[0] * 5]) counter = 0 for x, y in zip(train_x, train_y): # register original data expanded_images[counter, :, :] = x expanded_labels[counter] = y counter = counter + 1 # get a value for the background # zero is the expected value, but median() is used to estimate background's value bg_value = np.median(x) # this is regarded as background's value for i in range(4): # rotate the image with random degree angle = np.random.randint(-15, 15, 1) new_img = ndimage.rotate(x, angle, reshape=False, cval=bg_value) # shift the image with random distance shift = np.random.randint(-2, 2, 2) new_img_ = ndimage.shift(new_img, shift, cval=bg_value) # register new training data expanded_images[counter, :, :] = new_img_ expanded_labels[counter] = y counter = counter + 1 return expanded_images, expanded_labelsagument_x, agument_y = expend_training_data(x_train[:3], y_train[:3])
得到5倍于原数据集的新数据集:

后面的四个图像是我们通过一定的变换得到的,我们并没有去采集新的数据,通过创造假数据,我们的数据集变成了原来的若干倍,这种处理方法能够显著提高神经网络的泛化能力,即使是具有平移不变性的卷积神经网络(我们后面会详述),使用这种简单处理方式得到的新数据也能大大改善泛化。
提前终止
当训练参数数量大的神经网络时,即模型容量大于实际需求时,神经网络最终总是会过拟合,但是我们总是能够观察到,训练误差会随着训练时间的推移逐渐降低,但是验证集的误差却会先降低后升高,如下图所示:
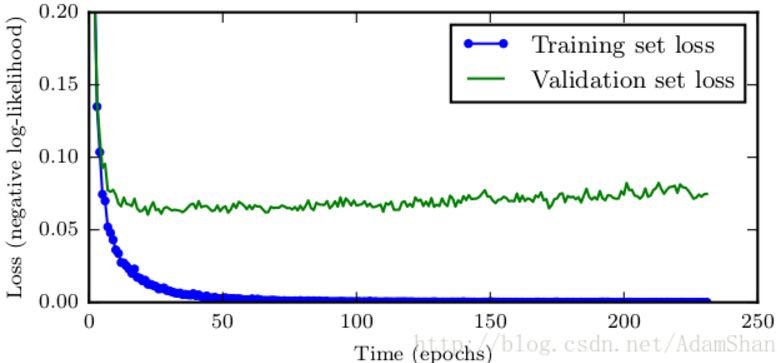
那么基于这个现象,我们可以在每次观察到验证集误差有所改善以后保存一份模型的副本,如果误差恶化,则将 耐心值 +1,当耐心值到达一个事先设定的阈值的时候,终止训练,返回保存的最后一个副本。这样,我们能够得到整个误差曲线中最低的点的模型。
参数范数惩罚
许多正则化方法会向神经网络的损失函数L(θ)添加一个惩罚项Ω(w),一次来约束模型的学习能力,形式如下:
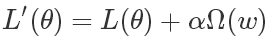
其中的θ是包括权重和偏置(w,b)在内的神经网络的参数,需要注意的是,惩罚项往往只对仿射变换中的权重(即w)进行惩罚,偏置单元b不会被正则化,原因在于:每个权重明确表明两个变量之间是如何相互作用的。要将权重拟合地很好,需要在各种不同的条件下观察这些变量。每一个偏置只会控制一个单独的变量,这也就意味着在保留不被正则化的偏置时,不需要引入过多的方差。 同样,对偏置参数进行正则化会引入相当程度的欠拟合可能。因此往往只对权重进行惩罚。α是一个需要人为设置的超参数,称为惩罚系数, 当α为 0 的时候,表示没有参数惩罚,α越大,则对应的参数的惩罚也就越大。以 L2 正则化为例,我们在损失函数的后面添加了的正则项为:
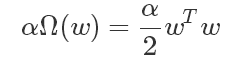
那么最小化权重的平方会带来什么结果呢?
神经网络将倾向于使所有的权重都很小,除非误差导数过大。
防止拟合错误的样本。
使得模型更加“光滑”,即输入输出敏感性更低,输入的微小变化不会明显的反映到输出上。
如果输入端输入两个相同的输入,网络的权重分配会倾向于均分权重而不是将所有的权重都分到一个连接上。
L2惩罚一方面降低了权重的学习自由度,削弱了网络的学习能力,另一方面相对均匀的权重又能使模型光滑化,使模型对输入的细微变化不敏感,从而增强模型的鲁棒性。
Dropout
参数范数惩罚通过改变神经网络的损失函数来实现正则化,而Dropout则通过改变神经网络的结构来增强网络的泛化能力,如图是一个神经网络训练时的结构:
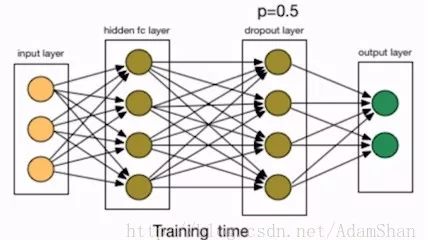
我们在第一个隐含层后面添加了一个Dropout层,Dropout 就是指随机地删除掉网络中某层的节点,包括该节点的输入输出的边,如下图所示:
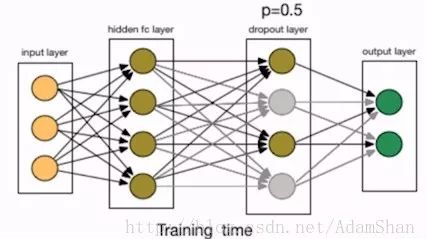
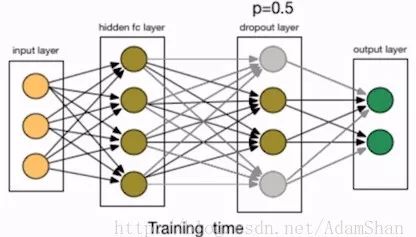
这也等价与以一定的几率保留节点。在本例中,p即保留节点的几率,我们设置为50%, 在实践中,保留概率通常设置在[0.5,1]。那么Dropout为什么有助于防止过拟合呢?简单的解释就是,运用了dropout的训练过程,相当于训练了很多个只有半数隐层单元的神经网络(后面简称为“半数网络”),每一个这样的半数网络,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。随着训练的进行,大部分半数网络都可以给出正确的分类结果,那么少数的错误分类结果就不会对最终结果造成大的影响。
那么等到训练结束的时候,我们的我们的网络可以看作是很多个半数网络的集成模型,到应用网络的阶段,我们就不再使用Dropout,即p=1,网络的最终输出结果是所有半数网络的集成结果,其泛化能力自然就会更好。
▌基于深度前馈神经网络的交通信号识别
Belgium Traffic Sign Dataset 数据集
我们使用BelgiumTS(Belgium Traffic Sign Dataset)来做一个简单的识别实例,BelgiumTS是一个交通信号的数据集,包含62中交通信号。
训练集的下载连接:
http://btsd.ethz.ch/shareddata/BelgiumTSC/BelgiumTSC_Training.zip
测试集的下载链接:http://btsd.ethz.ch/shareddata/BelgiumTSC/BelgiumTSC_Testing.zip
此数据集在不采用科学上网的方式时下载速度偏慢。
▌数据的读取和可视化
下载好数据以后,解压,使用如下目录结构存放数据:
data/Training/data/Testing/
该数据集的训练集和测试集均包含了62个目录,表示62种交通信号。使用如下函数读取数据:
def load_data(data_dir): """Loads a data set and returns two lists: images: a list of Numpy arrays, each representing an image. labels: a list of numbers that represent the images labels. """ # Get all subdirectories of data_dir. Each represents a label. directories = [d for d in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, d))] # Loop through the label directories and collect the data in # two lists, labels and images. labels = [] images = [] for d in directories: label_dir = os.path.join(data_dir, d) file_names = [os.path.join(label_dir, f) for f in os.listdir(label_dir) if f.endswith(".ppm")] # For each label, load it's images and add them to the images list. # And add the label number (i.e. directory name) to the labels list. for f in file_names: images.append(skimage.data.imread(f)) labels.append(int(d)) return images, labels # Load training and testing datasets.ROOT_PATH = "data"train_data_dir = os.path.join(ROOT_PATH, "Training")test_data_dir = os.path.join(ROOT_PATH, "Testing")images, labels = load_data(train_data_dir)
输出训练集的类别数和总的图片数量:
print("Unique Labels: {0} Total Images: {1}".format(len(set(labels)), len(images)))
Unique Labels: 62Total Images: 4575
我们显示每一个类别的第一张图片看看。
def display_images_and_labels(images, labels): """Display the first image of each label.""" unique_labels = set(labels) plt.figure(figsize=(15, 15)) i = 1 for label in unique_labels: # Pick the first image for each label. image = images[labels.index(label)] plt.subplot(8, 8, i) # A grid of 8 rows x 8 columns plt.axis('off') plt.title("Label {0} ({1})".format(label, labels.count(label))) i += 1 _ = plt.imshow(image) plt.show()display_images_and_labels(images, labels)

显然,数据集的图片并不是统一的尺寸的,为了训练神经网络,我们需要将所有图片resize到一个相同的尺寸,在本文中,我们将图片resize到(32,32):
# Resize imagesimages32 = [skimage.transform.resize(image, (32, 32)) for image in images]display_images_and_labels(images32, labels)

输出resize以后的图片信息:
for image in images32[:5]: print("shape: {0}, min: {1}, max: {2}".format(image.shape, image.min(), image.max()))
shape: (32, 32, 3), min: 0.0, max: 1.0shape: (32, 32, 3), min: 0.13088235294117614, max: 1.0shape: (32, 32, 3), min: 0.057059972426470276, max: 0.9011967677696078shape: (32, 32, 3), min: 0.023820465686273988, max: 1.0shape: (32, 32, 3), min: 0.023690257352941196, max: 1.0
图像的取值范围已经归一化好了,下面我们使用TensorFlow构造神经网络来训练一个深度前馈网络识别这个交通信号。
数据预处理
我们对数据进行预处理,首先将三通道的RGB转成灰度图:
images_a = color.rgb2gray(images_a)display_images_and_labels(images_a, labels)

注意,这里现实的并不是灰度图,原因在于我们使用了之前的display_images_and_labels函数,只需要在该函数的imshow部分添加cmap='gray'即可显示灰度图。
我们使用前面的方法对数据进行扩充(将数据扩充为原来的5倍),我们现实其中的三张图片:

然后我们对数据进行shuffle,并且把数据切分为训练集和验证集,并对标签进行one-hot编码:
from sklearn.utils import shuffleindx = np.arange(0, len(labels_a))indx = shuffle(indx)images_a = images_a[indx]labels_a = labels_a[indx]print(images_a.shape, labels_a.shape)train_x, val_x = images_a[:20000], images_a[20000:]train_y, val_y = labels_a[:20000], labels_a[20000:]train_y = keras.utils.to_categorical(train_y, 62)val_y = keras.utils.to_categorical(val_y, 62)print(train_x.shape, train_y.shape)
▌使用Keras构造并训练深度前馈网络
我们仍然使用上一篇文章中用到的深度前馈网络,看看在这类复杂问题中的性能如何:
model = Sequential()model.add(Flatten(input_shape=(32, 32)))model.add(Dense(512, activation='relu'))model.add(Dropout(0.5))model.add(Dense(512, activation='relu'))model.add(Dropout(0.5))model.add(Dense(62, activation='softmax'))model.summary()model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(train_x, train_y, batch_size=128, epochs=20, verbose=1, validation_data=(val_x, val_y)) ### print the keys contained in the history objectprint(history.history.keys())model.save('model.json')
现实训练loss和验证loss为:
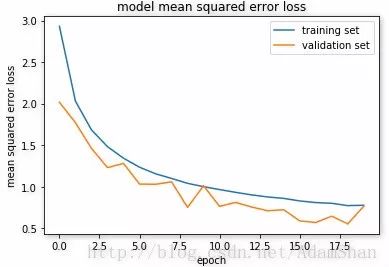
加载测试数据集,查看精度:
('Test loss:', 0.8060373229994661)('Test accuracy:', 0.7932539684431893)
我们的这个简单神经网络在测试集合上取得了79%的精度,我们现实几个测试样本的预测结果:

虽然精度不高,但效果似乎还行。。当然,这个例子只是一个入门的网络,首先,它抛弃了3通道的图像,所以信息会有一定的损失,其次,全连接网络的第一步就是把图像向量化了,我们能不能使用更加深,更加符合图片二维特征的网络呢?我们在后面的文章中继续探讨!
完整代码链接:
http://download.csdn.net/download/adamshan/10217607
原文链接:
https://blog.csdn.net/adamshan/article/details/79127573
-
无人驾驶
+关注
关注
98文章
4054浏览量
120447 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:无人驾驶汽车系统入门:深度前馈网络,深度学习的正则化,交通信号识别
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
详解深度学习、神经网络与卷积神经网络的应用

无人驾驶电子与安全
人脸识别、语音翻译、无人驾驶...这些高科技都离不开深度神经网络了!
英伟达无人驾驶Xavier处理器帮助应用程序使用深度学习神经网络算法
快速了解神经网络与深度学习的教程资料免费下载
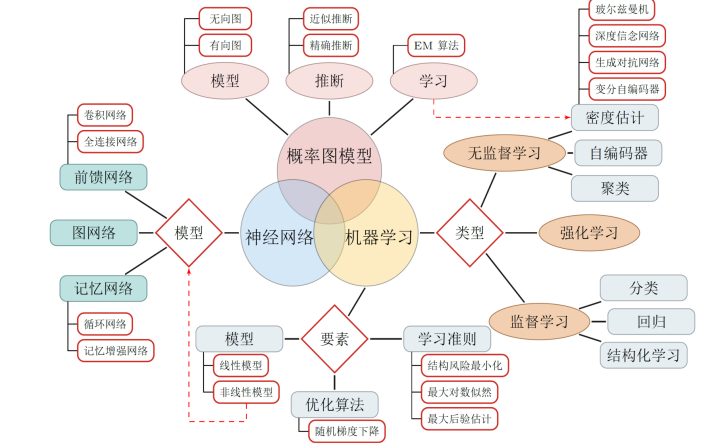

浅析三种主流深度神经网络
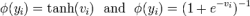
浅析三种主流深度神经网络






 工商网监
工商网监
评论