 盘点一些应用于汽车自动驾驶的芯片
盘点一些应用于汽车自动驾驶的芯片
当硬件传感器接收到环境信息后,数据会被导入到计算平台,进而由不同芯片进行运算。无人驾驶硬件平台是多种技术、多个模块的集成,主要包括:传感器平台、计算平台、以及控制平台。本文将详细介绍计算平台现有的解决方案。
无人驾驶硬件平台是多种技术、多个模块的集成,主要包括:传感器平台、计算平台、以及控制平台。本文将详细介绍计算平台现有的解决方案。
经常看我们公众号的朋友应该知道,当硬件传感器接收到环境信息后,数据会被导入到计算平台,进而由不同芯片进行运算。计算平台的设计直接影响无人驾驶系统的实时性和鲁棒性。
目前主流的自动驾驶芯片解决方案主要包括GPU、FPGA、DSP和ASIC四种。本文除了列举这四种之外,还列举其他的一些应用于汽车自动驾驶的芯片。
1.英伟达基于GPU的计算解决方案——DRIVE PX
NVIDIA DRIVE PX 2自动驾驶开发平台
NVIDIA的PX平台是目前领先的基于GPU的无人驾驶解决方案。2016年1月,搭载“Pascal显卡”的DrivePX2自动驾驶平台正式问世。
DRIVE PX 2的一些基本性能参数:
1.基于16nm FinFET工艺,功耗高达250W ,采用水冷散热设计。支持12路摄像头输入、激光定位、雷达和超声波传感器;
2. CPU部分:两颗新一代NVIDIA Tegra处理器,当中包括了8个A57核心和4个Denver核心;
3. 首发NVIDIA的新一代GPU架构Pascal(即帕斯卡,宣称性能是上一代的麦克斯韦构架的10倍),单精度计算能力达到8TFlops,超越TITAN X,有后者10倍以上的深度学习计算能力。
每个PX2由两个Tegra SoC和两个Pascal GPU图形处理器组成,其中每个图像处理器都有自己的专用内存并配备有专用的指令以完成深度神经网络加速。为了提供高吞吐量,每个Tegra SOC使用PCI-E Gen 2 x4总线与Pascal GPU直接相连,其总带宽为4 GB/s。此外,两个CPU-GPU集群通过千兆以太网项链,数据传输速度可达70 Gigabit/s。借助于优化的I/O架构与深度神经网络的硬件加速,每个PX2能够每秒执行24兆次深度学习计算。这意味着当运行AlexNet深度学习典型应用时,PX2的处理能力可达2800帧/秒。
NVIDIA的DRIVE PX 2平台到底如何在自动驾驶汽车上发挥作用呢?这里要重点讲一下它在高精度地图绘制上发挥的优势。DRIVE PX 2能够将外部传感器获取的图像数据加工处理后制成单个的高精度点云。系统将所有DRIVE PX 2平台的点云数据上传至云端服务器,经过DGX-1处理后,可融合为一副完整的高精度地图。所以,车内的DRIVE PX 2,云端的DGX-1配合发挥作用,形成了NVIDIA完整的自动驾驶技术平台解决方案。
Pegasus
NVIDIA于其今年的生态圈大会GTC Eurpoe上发表自动驾驶运算平台Drive PX家族的新成员,其代号为「Pegasus」。 「Pegasus」预计从2018年第二季起提供给NVIDIA的自动驾驶研发伙伴。
据称「Pegasus」的运算能力达到320 TOPS(Trillion OperaTIons Per Second),超越其前代平台「Drive PX 2」之运算能力高达10倍。 此运算能力主要来自于4颗处理器-2颗为以NVIDIA目前最新GPU架构「Volta」为核心的SoC「Xavier」、以及另外2颗为车用机械视觉与深度学习所准备的专用GPU。
2.德州仪器基于DSP的解决方案——TDA2x SoC
TI TDA2x SoC
德州仪器提供了一种基于DSP的无人驾驶的解决方案。其TDA2x SoC拥有两个浮点DSP内核C66x和四个专为视觉处理设计的完全可编程的视觉加速器。相比ARM Cortex-15处理器,视觉加速器可提供八倍的视觉处理加速且功耗更低。类似设计有CEVA XM4。这是另一款基于DSP的无人驾驶计算解决方案,专门面向计算视觉任务中的视频流分析计算。使用CEVA XM4每秒处理30帧1080p的视频仅消耗功率30MW,是一种相对节能的解决方案。
TDA2x SoC 基于异构可扩展架构,该架构包括 TI 定浮点 C66x DSP 内核、全面可编程Vision AccelerationPac、ARM® Cortex™-A15 MPCoreTM 处理器与两个 Cortex-M4 内核,以及视频及图形内核与大量的外设。
该 TDA2x 可实现各种前置摄像机应用的同步运行,其中包括远光灯辅助、车道保持辅助、高级巡航控制、交通信号识别、行人/对象检测以及防碰撞等。此外,TDA2x 还支持智能 2D 及 3D 环绕视图以及后方碰撞警告等泊车辅助应用,并可运行为前置摄像机开发的行人/对象算法。TI TDA2x 还可作为融合雷达与摄像机传感器数据的中央处理器,帮助做出更稳健的 ADAS 决定。
3.Altera基于FPGA的解决方案——CycloneV SoC
Altera Cyclone V芯片
Altera公司的Cyclone V SoC是一个基于FPGA的无人驾驶解决方案,CycloneV SoC FPGA 系列基于28nm低功耗(LP)工艺,提供需要5G收发器应用的最低功耗,和以前的产品检验相比,功耗降低40%.器件集成了基于ARM处理器的硬件处理器系统(HPS),具有更有效的逻辑综合功能,收发器系列和SoC FPGA系列,从而降低系统功耗。主要用在工业无线和有线通信、军用设备和汽车市场。
Cyclone V SoC现已应用在奥迪无人车产品中。Altera公司的FPGA专为传感器融合提供优化,可结合分析来自多个传感器的数据以完成高度可靠的物体检测。类似的产品有Zynq专为无人驾驶设计的Ultra ScaleMPSoC。当运行卷积神经网络计算任务时,Ultra ScaleMPSoC运算效能为14帧/秒/瓦,优于NVIDIA Tesla K40 GPU可达的4帧/秒/瓦。同时,在目标跟踪计算方面,Ultra ScaleMPSoC在1080p视频流上的处理能力可达60fps。
奥迪全新A8车型上搭载的zFAS域控制器就使用了Altera提供的FPGA芯片-Cyclonev Soc
4.Mobileye基于ASIC的解决方案——Eyeq5SOC
ASIC(Application SpecificIntegrated Circuits)即专用集成电路,是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。Mobileye是一家基于ASIC的无人驾驶解决方案提供商。
Mobileye EyeQ5芯片将装备8枚多线程CPU内核,同时还会搭载18枚Mobileye的下一代视觉处理器。“传感器融合”是EyeQ5推出的主要目的。
其Eyeq5 SOC装备有四种异构的全编程加速器,分别对专有的算法进行了优化,包括有:计算机视觉、信号处理和机器学习等。Eyeq5 SOC同时实现了两个PCI-E端口以支持多处理器间通信。这种加速器架构尝试为每一个计算任务适配最合适的计算单元,硬件资源的多样性使应用程序能够节省计算时间并提高计算效能。
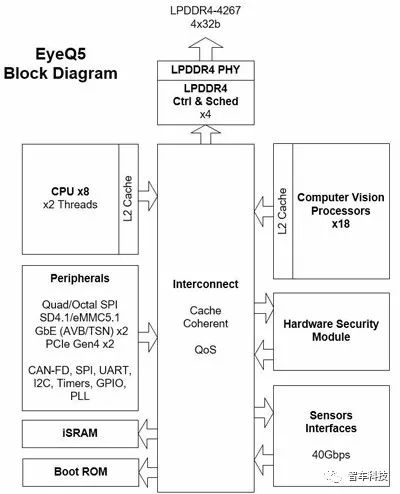
mobileyeEyeQ5 芯片的电路系统块图(block diagram)
5.其他
1)谷歌的计算平台——TPU芯片
谷歌TPU芯片
谷歌公布了AlphaGo战胜李世石的“秘密武器”就是芯片TPU(张亮处理单元,Tensor Processing Unit),TPU专门为谷歌TensorFlow等机器学习应用打造,能够降低运算精度,在相同时间内处理更复杂、更强大的机器学习模型并将其更快投入使用。其性能把人工智能技术往前推进了7年左右,相当于摩尔定律的3代时间。
TPU使得机器学习类深度神经网络模型在每瓦特性能上由于传统硬件。TPU在2016谷歌I/O大会上首次被提及,然而谷歌早在2013年就已经开始秘密研发TPU,并于2014年就应用在了谷歌的数据中心。
相比GPU的适合训练,TPU更适合做训练后的分析决策。这一点在谷歌的官方生命中得到印证:TPU只在特定的机器学习应用中起到辅助作用,公司将继续使用其他厂商制造的CPU和GPU。
在2018谷歌I/O大会上,谷歌宣布新的张量处理单元(TPU)将帮助谷歌改进使用AI的应用程序,新版本TPU与它的前身类似,也将通过谷歌的公共云服务向第三方开发者开放,并表示,每个芯片的性能都是去年的8倍,远远超过了100Petaflops(Petaflops:每秒一千兆/一千万亿(10^15)次的浮点运算)。”而目前,容纳16个英伟达最新GPU的盒子仅能提供2Petaflops的计算能力。
2)恩智浦NXP自动驾驶汽车的计算平台BlueBox
BlueBox是一款基于Linux系统打造的开放式计算平台,可供主机厂和一级供应商开发、试验自己的无人驾驶汽车。它的主要功能是将之前彼此隔离的单个传感器节点和处理器进行功能上的结合。BlueBox能够在40W功率下实现90000 DMIPS(每秒百万条指令)的计算速度。但相比其他竞争对手提供的ADAS/自动驾驶解决方案,BlueBox减少了对风扇、液冷及不稳定热能管理系统等电器元件的使用。
BlueBox装备了一枚恩智浦NXP S32V汽车视觉处理器和一枚LS2088A内嵌式计算机处理器。S32V属于安全控制器范畴,能够分析驾驶环境,评估风险因素,然后指示汽车的行为,而LS2088则是为其保驾护航的高性能计算平台。
S32V芯片包含有不同的图形处理引擎,特制的高性能图形处理加速器,高性能ARM内核,高级APEX图形处理和传感器融合。它的功能包括了传感器/执行器管理和故障检验。其中故障检验除能够对内存、硬件配置和程序流实时检测外,它还具备错误管理能力。
而负责进行高性能运算的LS2088A内嵌式处理器是由8个64位ARM Cortex-A72内核组成,配合频率2GHz的特制加速器、高性能通信接口和DDR4内存控制器,延时极低。
除了S32V和LS2088A这两枚核心的处理器之外,BlueBox还搭载了其他为实现不同传感器节点功能的芯片,它们能够处理从V2X、雷达、视觉系统、激光雷达以及车辆状态获取的信息。
3)概率芯片
“S1”概率芯片示意图
2016年4月,MIT TechnologyReview报道,DARPA投资了一款由美国Singular Computing公司开发的“S1”概率芯片。其优点包括:算法逻辑异常简单,不需要复杂的数据结构,不需要数值代数计算;计算精度可以模拟不同数目的随机行走自如控制;不同的随机行走相互独立,可以大规模并行模拟;模拟过程中,不需要全局信息,只需要网络局部信息即可。模拟测试中,使用S1追踪视频里的移动物体,每帧处理速度比传统处理器快了近100倍,而能耗还不到传统处理器的2%。专用概率芯片可以发挥概率算法简单并行的特点,极大提高系统性能。
早在2018年MIT Technology Review“十大科技突破技术”预测中,概率芯片就榜上有名。通过牺牲微小的计算精度换取能耗的显著降低,概率芯片在历来追求精准的芯片领域独树一帜,但正因为如此,概率芯片很可能后来居上。
4)中国芯片解决方案
寒武纪的芯片
寒武纪1M处理器
“寒武纪”是中国科学院计算技术研究所发布的全球首个能够“深度学习”的“神经网络”处理器芯片。2012年中科院计算所和法国Inria等机构共同提出了国际上首个人工神经网络硬件的基准测试集benchNN。此后,中科院计算所和法国Inria的研究人员共同推出了一系列不同结构的DianNao神经网络硬件加速器结构。当前寒武纪系列包含四种处理器机构:DianNao(面向多种功能人工神经网络的原型处理器结构)、DaDianao(面向大规模人工神经网络)和PuDianNao(面向多种机器学习算法),面向卷积神经网络的ShiDianNao。寒武纪进入产业化运营,其主要方向是高性能服务器芯片、高性能终端芯片和服务机器人芯片。
寒武纪1M处理器IP主打的是智能驾驶领域,后将应用领域拓宽到了智能手机、智能音箱、摄像头、自动驾驶等方面。寒武纪官方数据,1M的int 8(8位运算)效能比高达达5Tops/watt(每瓦5万亿次运算),并且提供了2Tops、4Tops、8Tops三种尺寸的处理器内核,以满足不同需求。1M还将支持CNN、RNN、SVM、k-NN等多种深度学习模型与机器学习算法的加速,能够完成视觉、语音、自然语言处理等任务。
中星微的芯片——星光智能一号
“星光智能一号”芯片和主板
2016年6月,中星微率先推出了中国首款嵌入式神经网络处理器(NPU)芯片“星光智能一号”,这也是全球首枚具备深度学习人工智能的嵌入式视频采集压缩编码系统级芯片,并已实现量产。该芯片采用“数据驱动”并行计算的架构,单颗NPU(28nm)能耗仅为400mW,极大地提升了计算能力与功耗的比例,可以广泛应用于智能驾驶辅助、无人机机器人等嵌入式机器视觉领域。
地平线的芯片——征程和旭日
2017年 12月,地平线发布了两款款嵌入式人工智能芯片——面向智能驾驶的征程(Journey)1.0处理器和面向智能摄像头的旭日(Sunrise)1.0处理器。这两款芯片属于ASIC人工智能专用芯片。
地平线征程1.0处理器
征程1.0:面向智能驾驶,能够同时对行人、机动车、非机动车、车道线、交通标志牌、红绿灯等多类目标进行精准的实时监测与识别,同时满足车载严苛的环境要求以及不同环境下的视觉感知需求。征程1.0属于工业级的处理器,不是车规级的。因此地平线一开始会去做ADAS的后装市场,不过他们有计划,把他们的处理器推向车规级。
地平线旭日1.0处理器
旭日1.0:面向智能摄像头,能够在本地进行大规模人脸抓拍与识别、视频结构化处理等,可广泛用于商业、安防等多个实际应用场景。
目前新一代自动驾驶处理器征程2.0正在研发中,而未来在软硬件的进一步协同优化后,是面向L3/L4的自动驾驶解决方案,可满足自动驾驶场景下高性能和低功耗的需求。
-
芯片
+关注
关注
454文章
50526浏览量
422435 -
无人驾驶
+关注
关注
98文章
4040浏览量
120360 -
自动驾驶
+关注
关注
783文章
13722浏览量
166234
原文标题:盘点自动驾驶硬件计算平台解决方案
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论