 面向AWorks框架管理文件的方法和数据结构
面向AWorks框架管理文件的方法和数据结构

本文导读
文件系统是在存储设备中(SD Card、NAND Flash…)组织文件的方法和数据结构,用于管理文件。AWorks定义了文件系统的通用接口,例如,打开、读/写、关闭文件等等。文件系统的具体实现可以自由选择,例如,FAT、UFFS、YAFFS2 等等。
本文为《面向AWorks框架和接口的编程》第三部分软件篇——第11章文件系统——第1~5小节:文件系统简介、设备挂载管理、文件基本操作、目录基本操作和微型数据库。本章导读
文件系统是用于管理文件的方法和数据结构,文件和文件系统相关的数据存储在实际的物理介质中,例如,NAND FLASH,Nor FLASH或SD Card等。AWorks定义了文件系统的通用接口,无论底层使用何种文件系统,比如常见的FAT16/32、UFFS或YAFFS2等,均可使用同一套接口进行文件相关的操作。
11.1 文件系统简介
在文件系统中,存储数据的基本单位是文件,即数据是按照一个一个文件的方式进行组织的。当文件较多时,将导致文件繁多、不易分类、重名等问题,为此,在文件的基础上,提出了目录的概念,相当于Windows系统中的文件夹,一个目录中,可以包含多个文件。特别地,一个目录中,除包含文件外,还可以包含子目录,子目录可以继续包含子目录。最上层的目录被称为根目录,示意图详见图11.1。

图11.1 目录结构示意图
图中的目录名和文件名仅用作示例,与实际系统的目录树结构并不存在任何关联。在AWorks中,根目录使用斜杠(即:"/")表示,应注意与反斜杠(即:"")进行区分,不可混用。存于根目录中的文件,其完整路径直接使用“斜杠 + 文件名”的形式表示,如图11.1中的test1.txt文件,其路径为"/test1.txt",若一个文件所在目录不是根目录时,则多个目录之间要使用斜杠(即:"/")分隔,比如,test5.txt文件对应的完整路径应表示为"/usr/base/test5.txt"。
AWorks中分隔符使用"/",这与UNIX/Linux的风格是完全相同的,而与Windows则不相同,Windows中使用反斜杠""作为分隔符。
11.2 设备挂载管理
在图11.1中,为用户展示了一个目录树结构,图中的每个文件都存放在相应的目录中,目录是一个虚拟的逻辑概念,便于用户按照逻辑路径访问各个文件。而实质上,文件数据是存放在物理存储介质中的,例如,NAND FLASH,Nor FLASH或SD Card等。为此,就需要在系统中将目录与某一物理存储介质相关联,用户存放在某一目录下的文件都自动保存到对应的物理存储介质中,这种关联操作可以通过“设备挂载”来实现。“设备挂载”用于将物理存储介质挂载到某一目录,使该物理存储介质与该目录对应,后续所有在该目录下的文件(或子目录)实际上都存储到了与之对应的存储介质中。
在一个系统中,往往存在多种存储介质,例如,NAND FLASH,SD Card或外接的U盘等,无论存在多少存储介质,对于用户来讲,其都是使用图11.1所示的一个目录树来进行文件的管理,根目录只会有一个,不会因为具有多个存储介质而产生多个根目录。
实际应用中,为了方便管理,可以进行更细的划分,将一个硬件存储介质分成多个区,此时,每个分区可以看作一个独立的存储介质,挂载到某一目录。例如,一个SD卡的容量是2G,可以分成大小不同的4个分区,例如,SD_S0(1G)、SD_S1(512M)、SD_S2(256M)、SD_S3(256M)。此时,4个分区可以当作4个独立的存储介质,分别挂载到不同的目录。
对于一个物理存储介质,需要使用某一具体的文件系统对其中的文件数据进行管理,比如常见的FAT16/32、UFFS或YAFFS2等,它们各有优缺点,针对特定的存储介质,可以选择合适的文件系统。如FAT16/32常用于U盘、SD卡中,UFFS和YAFFS2常用于NAND FLASH中。同一系统中,不同的物理存储介质可以使用不同的文件系统。一般来讲,初次使用某一硬件存储介质时,需要进行格式化操作,指定使用的文件系统,存储一些与文件系统相关的初始数据。格式化后,才可将该设备挂载到目录树中。通常情况下,存储设备掉电不会丢失数据,因此,格式化操作仅需执行一次,不需要每次上电都执行。
AWorks提供了抽象的文件系统接口和框架,即使系统中不同存储介质使用了不同的文件系统,对于用户来讲,仍然可以使用相同的接口进行文件相关的操作。
AWorks提供了管理硬件存储设备的接口,相关接口的函数原型详见表11.1。
表11.1 存储设备管理相关接口(fs/aw_mount.h)
1. 格式化存储设备
格式化存储设备,以指定使用的文件系统,并存储一些与文件系统相关的初始数据。其函数原型为:

其中,dev_name为存储设备的名字,fs_name为使用的文件系统的名字,fmt_arg为格式化相关的附加信息。返回值为标准的错误号,返回AW_OK时,表示格式化成功,否则,表示格式化失败,可能是由于硬件设备不存在或文件系统不支持造成的。
存储设备的名字与具体的物理存储介质相关。例如,常见的SD卡设备,其对应的设备名为:/dev/sdx,其中,x为SD卡所处的SDIO总线序号,比如:0、1、2等。为便于叙述,这里将SD卡和TF卡统称为SD卡存储设备,SD卡就是常见的大卡,常用于相机中,如图11.2(a)所示。
TF卡又称Micro SD卡,体积比SD卡小,很多手机都配备了TF卡接口,用于扩展存储容量,如图11.2(b)所示。除了体积大小的区别外,SD卡在左侧还有一个LOCK开关,用于锁定SD卡,从硬件上开启写保护,避免数据损坏。

图11.2 SD卡与TF卡
在i.MX28x硬件平台中,仅在SDIO0总线上设置了一个TF卡卡槽,因而仅能插入一张TF卡,不能插入SD卡。若正确插入了TF卡,则该TF卡对应的设备名为"/dev/sd0"。为便于验证后续程序,读者可以准备一张TF卡。
除使用TF卡外,还可以使用U盘进行测试,在i.MX28x平台中设置了USB接口,默认情况下,USB HOST1接口用于外接USB设备,USB HOST0接口用于外接USB主机,将自身模拟为一个USB设备。可以通过USB HOST1接口外接U盘,U盘在系统中对应的存储设备名为"/dev/ms0-ud0"。
在编程上,不同的物理存储设备仅仅是设备名发生了变化,没有其它任何区别,U盘和TF卡的具体细节差异用户无需关心。为便于叙述,后文统一使用TF卡存储设备进行举例说明,若读者使用的是U盘,仅需将范例程序中出现的TF卡设备名修改为"/dev/ms0-ud0"。
fs_name为文件系统的名字,比如:
"vfat"、"uffs"、"yaffs"等,其代表了此硬件设备使用的具体文件系统。如使用FAT,则文件系统名为"vfat",其会自动根据存储器特性选择使用合适的FAT文件系统:FAT12、FAT16或FAT32。
fmt_arg为格式化相关的信息,不同文件系统使用的信息可能会不同,其类型struct aw_fs_format_arg (fs/aw_fs_type.h)定义如下:

对于FAT文件系统, 其管理的一个存储设备或分区称之为“卷”(volume),vol_name即为该卷指定一个卷名,当前系统中,卷名仅作标识,未用作其它特殊用途,可任意指定一个合理的名字,比如:"awdisk"。
在FAT文件系统中,存储设备是以“分配单元”(allocation unit)为单位进行数据管理的, unit_size指定了每个分配单元的大小,分配单元在FAT中又被称为“簇”(cluster)。
在允许范围内,分配单元大小设置越大,读写速度越快,反之则越慢。但是,需要注意的是,分配单元越大,也越有可能造成空间的浪费,因为即便一个文件的大小远远小于分配单元大小,也会占用一个完整的分配单元。unit_size必须为硬件存储设备扇区大小(通常固定为512)的整数倍,且倍数必须是2的幂,比如:1、2、4、8等,可以将unit_size设置为4096(512×8),通常情况下,unit_size的有效范围为:512 ~ 32768。为了便于使用,避免设置错误,也可以将该值设置为0,系统将自动根据存储器容量选择一个合适的值。
FAT文件系统又可以细分为FAT12、FAT16、FAT32,它们最明显的区别就是对分配单元进行寻址的位数不同,分别为12位、16位、32位。例如,对于FAT12,其使用12位地址对分配单元进行寻址,因此,理论上最大只能管理212=4096个分配单元(实际上,部分地址用作它用,管理的分配单元要略小于该值),若每个分配单元的大小为32K,则FAT12管理存储设备的最大容量为:32K*4096 = 128M。同理,可得到FAT16管理的存储设备最大容量为2G,虽然FAT32理论上可以管理的容量达到T级别,但实际中,当存储设备的容量超过32G时,不再建议使用FAT,例如,在Windows中,可以使用NTFS等其它文件系统。用户无需明确指定使用何种FAT文件系统,系统将根据设备容量自动进行选择。
对于FAT文件系统,flags标志未使用,设置为0即可。基于此,格式化TF卡的范例程序详见程序清单11.1。
程序清单11.1 式化范例程序


若未插入TF卡或刚插入TF卡但还未初始化完成,则"/dev/sd0"设备是不存在的,此时,aw_make_fs()函数将返回错误号:
-AM_ENODEV。
由于程序在系统启动后将立即执行,TF卡可能还未及时插入或初始化完成。因此,程序中,当格式化函数的返回值为-AM_ENODEV时,继续重试。为便于测试,用户应尽快插入TF卡。格式化操作通常比较费时,作者在使用程序清单11.1所示程序格式化一张8G的TF卡时,耗时约8秒。
格式化仅需执行一次,若本次格式化成功,则后续再进行其它操作时,无需再格式化。特别地,格式化操作会删除存储设备上所有的原始数据,应谨慎使用。
在程序清单11.1中,若TF卡还未准备就绪(TF卡未插入或刚插入但还未初始化完成),则不断重试。为了避免不断重试,使程序逻辑更加清晰易懂,可以在上电后等待设备就绪后再执行格式化操作,等待设备就绪的函数原型为(fs/aw_blk_dev.h):

该接口是用于等待一个块设备准备就绪,常见的U盘、SD卡、TF卡等都属于块设备(即在物理操作上,数据是以块为单位,比如:512字节,进行数据的写入和读取的,而不是以单个字节为单位)。其中p_name为设备名,例如,"/dev/sd0",timeout用于指定超时时间(单位为系统节拍)。
若设备已就绪,则直接返回AW_OK;若设备未就绪,则具体的行为与timeout的值相关。若timeout的值为AW_WAIT_FOREVER。则程序会阻塞于此,永久等待,直到设备准备就绪;若值为AW_NO_WAIT,则不会阻塞,立即返回错误号-AW_EAGAIN;若值为一个正整数,则表示最长的等待时间(单位为系统节拍),在超时时间内设备就绪则返回AW_OK,否则,返回-AW_ETIME表示超时。
优化程序清单11.1,避免不断重试,仅当设备就绪后再执行格式化操作。范例程序详见程序清单11.2。
程序清单11.2 格式化范例程序(设备就绪后再执行格式化操作)

2. 挂载设备
为了使用目录树结构管理文件,并将文件保存到存储设备(如TF卡)中,必须将存储设备挂载到某一目录。挂载操作的函数原型为:

其中,mnt为挂载点,其为新建的一个目录结点,使用全路径表示,比如:"/test",其表示在根目录下创建了一个名为test的挂载点,后续访问"/test "目录即表示访问本次挂载的存储设备;dev为存储设备的名字,如果使用TF卡,则对应的设备名为"/dev/sd0";fs为存储设备使用的文件系统名,如果使用FAT文件系统,则文件系统名为"vfat";flags为挂载时的一些选项标识,当前无可用标识,预留给后续扩展使用,设置为0即可。返回值为标准的错误号,返回AW_OK时,表示挂载成功,否则,表示挂载失败。挂载TF卡的范例程序详见程序清单11.3。
程序清单11.3 挂载TF卡范例程序

注意,当前挂载信息不会保存到存储设备中,相关信息仅保留在内存中,因此,每次重新上电时,都应该执行挂载操作。
挂载完毕后,即在根目录下创建了一个test挂载点,对于用户来讲,后续即可在该目录下进行文件相关的操作,例如,创建文件、读取文件、写入文件等操作。此外,还可以在该目录下创建子目录,这些文件和子目录信息都存储在TF卡中,掉电不会丢失。
3. 取消挂载
当设备不再使用时,可以取消该设备的挂载,挂载点将删除,用户不可再访问该目录。取消挂载的函数原型为:

其中,path为路径名,可以是设备名(比如:"/dev/sd0"),也可以是挂载点(即挂载时指定的mnt参数,比如:"/test")。flags为挂载时的一些选项标识,当前无可用标识,预留给后续扩展使用,设置为0即可。返回值为标准的错误号,返回AW_OK时,表示取消挂载成功,否则,表示取消挂载失败。取消挂载的范例程序详见程序清单11.4。
程序清单11.4 取消挂载范例程序


由于在挂载设备时,已经将挂载点和设备名进行了关联,因此,在取消挂载时,只要知道挂载点和设备名中任何一个信息,均可得到完整的挂载信息,然后取消挂载。在程序清单11.4中,是通过挂载时使用的挂载点取消挂载,也可以通过设备名取消挂载,例如,将第19行代码中的"/test"修改为"/dev/sd0"。
11.3 文件基本操作
文件相关的操作主要包括打开文件(创建文件)、关闭文件、读取文件数据、写入数据等。相关接口的原型详见表11.2。
表11.2 文件基本操作相关接口
1.打开文件
打开或创建一个文件的函数原型为:

其中,path为包含文件名的完整路径,如需在test目录下创建一个fs_test.txt文件,则path应为"/test/fs_test.txt",文件名建议使用8.3格式,即主文件名长度不超过8,扩展名长度不超过3。因为部分文件系统不支持更长的文件名,使用8.3格式的文件名兼容性更好。
oflag指定打开文件的方式,当前支持的打开方式详见表11.3。
表11.3 打开文件方式(io/aw_fcntl.h)

mode用于控制访问权限,其类型为mode_t,mode_t是一个整数类型,实际类型与具体平台相关,通常情况下,其为32位无符号整数。在当前系统中,mode为与POSIX标准接口兼容的参数,目前没有使用,可以设置为0。在支持该参数的平台中,其用于控制用户访问文件的权限,仅当创建文件时有效,有效位共计9位,每3位为1组,共计3组。3组分别控制3类用户的权限:当前用户、组用户、其它用户。每组3位分别控制3种权限:读、写、执行,相应位为1,表明该类用户具有相应的权限。各组用户权限的控制位详见表11.4。
表11.4 权限控制

由于mode中每3位为一组,而3位二进制数据恰好可以使用1位八进制数据(0 ~ 7)表示。因此,为了便于阅读,mode的值往往使用八进制表示。如0777(在C语言中,数据前加0表示八进制数据),表示所有用户都具有读、写、执行的权限。为了使应用程序更具有兼容性,可以将mode的值设置为0777。
若文件打开成功,则返回文件的句柄,后续使用该句柄进行文件的读写操作。特别地,若返回值为-1,则表示打开文件失败。如打开test目录下的fs_test.txt文件(若不存在该文件,则创建该文件)的范例程序详见程序清单11.5。
程序清单11.5 打开文件范例程序

2. 创建文件
创建文件的函数原型为:

其中,path为包含文件名的完整路径,注意,创建文件时,需要保证path指定的路径是有效的,若其父文件夹不存在,则会创建失败。mode为文件的模式。其本质上等效于:

由此可见,其是以只写方式打开文件的,若文件不存在,由于使用了O_CREAT标识,则创建文件,若文件已穿在,由于使用了O_TRUNC标识,则会将原文件的内容清空,长度截断为0,相当于创建了一个新文件。
若文件创建成功,则返回文件的句柄,后续使用该句柄进行文件的读写操作。特别地,若返回值为-1,则表示创建文件失败。如在test目录下创建一个fs_test2.txt文件的范例程序详见程序清单11.6。
程序清单11.6 创建文件范例程序

3. 关闭文件
文件打开或创建后,若不再需要使用文件,则必须关闭该文件,文件关闭后,文件相关的数据才会被可靠的写回硬件存储设备。关闭文件的函数原型为:

其中,filedes为待关闭文件的句柄,其值是打开文件或创建文件时返回的文件句柄。返回值为错误号,若返回AW_OK,则表示关闭文件成功,否则,表示关闭文件失败。范例程序详见程序清单11.7。
程序清单11.7 关闭文件范例程序

4. 写入数据
文件打开后,可以写入数据至文件中,其函数原型为:

其中,filedes为文件句柄,buf为待写入数据的缓冲区,nbytes为写入数据的字节数。返回值为成功写入的字节数,特别地,若返回值为负值,则表示写入数据失败,可能是由于打开文件的方式不对造成的,例如,打开文件时,使用了只读的方式打开文件;若返回值小于nbytes,则可能是由于存储设备容量不足造成的。
对于每个打开的文件,系统中都使用了一个与其关联的整数变量来表示该文件的读写位置,其值为相对于文件起始位置的偏移量。文件读写位置将决定下一次读/写数据时的位置。打开文件时,若未指定O_APPEND标志,则读写位置初始为0,否则,读写位置在文件结尾,例如,文件大小为10,则读写位置的值即为10。每次写入数据完毕后,都将自动更新读写位置至本次写入数据的尾部,例如,写入10个数据,则读写位置的值将自动增加10,以便下次写入数据时,紧接着尾部继续写入。
例如,打开文件,写入一串字符串,最后再关闭文件的完整范例程序详见程序清单11.8。
程序清单11.8 写入数据范例程序


若程序运行成功,则在TF卡中创建了一个fs_test.txt文件,同时,在文件中写入了字符串"just for test:0123456789"。为了验证操作是否成功,可以拔下TF卡,将TF卡通过读卡器连接到PC上(Windows系统),通过PC查看TF卡中的内容,可以看到TF卡目录内容和fs_test.txt文件内容详见图11.3。

图11.3 通过PC查看TF卡的内容(1)
5. 读取数据
文件打开后,可以从文件中读取数据,其函数原型为:

其中,filedes为文件句柄,buf为保存读取数据的缓冲区,nbytes为读取数据的字节数。返回值为成功读取的字节数,特别地,若返回值为负值,则表示读取数据失败,可能是由于打开文件的方式不对造成的,例如,打开文件时,使用了只写的方式打开文件;若返回值不小于0,但小于nbytes,则表示文件数据不足,已经读取至文件结尾。
每次读取数据完毕后,都将自动更新读写位置至本次读取数据的尾部,例如,读取10个数据,则读写位置的值将自动增加10,以便下次读取数据时,紧接着尾部继续读取。
例如,以只读方式打开之前创建的:
/test/fs_test.txt文件,读取文件内容,以判断读写是否正确的范例程序详见程序清单11.9。
程序清单11.9 读取数据范例程序


6. 改变文件读写位置
对于每个打开的文件,都有一个“读写位置(相对于文件起始位置的偏移量)”来表示下一次读/写数据时的起始位置,其值除在每次读/写数据时自动更新外,还可以使用aw_lseek()函数手动改变,aw_lseek()的函数原型为:

其中,filedes为文件句柄,offset为设置的偏移量,whence指定offset偏移量的基准位置。返回值为新的“读写位置”。
若whence的值为SEEK_SET,表示offset偏移量是以文件起始位置为基准,就相当于直接设置“读写位置”的值为offset。使用SEEK_SET的范例程序详见程序清单11.10。
程序清单11.10 SEEK_SET范例程序

若whence的值为SEEK_CUR,表示offset偏移量是以当前“读写位置”为基准,即将“读写位置”的值加上offset作为新的“读写位置”,offset可正可负,为正时,增大“读写位置”的值,表示“读写位置”向文件尾部方向移动,为负时,减小“读写位置”的值,表示“读写位置”向文件头部方向移动。使用SEEK_CUR的范例程序详见程序清单11.11。
程序清单11.11 SEEK_CUR范例程序

若whence的值为SEEK_END,表示offset偏移量是以文件尾部为基准,即将“读写位置”的值设置为文件大小加上offset作为新的“读写位置”。使用SEEK_END的范例程序详见程序清单11.12。
程序清单11.12 SEEK_END范例程序

值得注意的是,若移动后的“读写位置”大于当前文件大小,则移动的结果将与具体的文件系统相关。通常情况下,“读写位置”被重置为当前文件大小,即原文件尾部,部分特殊情况下,也可能会扩充文件的大小。可以通过返回值判断当前实际的“读写位置”。出于兼容性考虑,不建议将“读写位置”移动至当前文件的有效范围之外。
可以修改程序清单11.9所示的程序,在读取数据前,设定“读写位置”为14,然后读取10个字符,即可仅读取出字符串:"0123456789",范例程序详见程序清单11.13。
程序清单11.13 读取指定位置数据段的范例程序


7. 截断文件
用于将文件截断为指定长度,超出长度的内容将被删除,一般情况下,都通过文件描述符filedes指定要截断的文件,其函数原型如下:

其中,filedes为文件句柄,length为新的文件长度,如果length小于原文件长度,文件将被截断。返回值为AW_OK时,表示截断成功,否则,表示截断失败。如将fs_test.txt文件长度截断为14,以删除结尾的字符串:"0123456789",则范例程序详见程序清单11.14。
程序清单11.14 截断文件范例程序

在程序清单11.14中,截断一个文件主要分为3步:打开文件、截断文件、关闭文件。为了简化截断文件的操作,AWorks提供了另外一个功能相同的接口,但其通过文件名指定要截断的文件,使用起来更加便捷,其函数原型为:

其中,path为文件的路径,length为新的文件长度。用户无需在截断文件前打开文件,该函数将在内部打开文件,截断后关闭文件。如使用该接口,则一行代码即可实现与程序清单11.14相同的功能,即:

8. 修改文件名
该函数用于修改指定文件的文件名,函数原型为:

其中,oldpath为原文件名,newpath为新文件名。返回值为AW_OK时表示更名成功,否则表示更名失败。修改
"/test/fs_test.txt"为"/test/fs_test3.txt"的范例程序详见程序清单11.15。
程序清单11.15 修改文件名范例程序

注意,若newpath指定的文件已存在,则该文件将会被覆盖。特别地,若newpath与oldpath相同,则函数不做任何处理,直接返回成功。
9. 同步文件
通常情况下,在操作文件的过程中,文件相关的数据并不会立即写入到存储设备中,而是保存在内存中,这样可以在一定程度上提高数据读写的效率。在关闭文件时,再将该文件相关的所有数据保存到存储设备中。在一些比较耗时的文件操作过程中,为了避免中途突然掉电导致数据丢失,也可以通过aw_fsync()函数立即执行回写操作,使文件相关的数据保存到存储设备中。这就类似于在编写一个Word文档的过程中,需要时常点击保存按钮,避免突然掉电导致部分数据丢失。其函数原型为:

其中,filedes为文件句柄。返回值为AW_OK时表示同步成功,否则,表示同步失败。范例程序详见程序清单11.16。
程序清单11.16 同步文件范例程序

10. 删除文件
当一个文件不再使用,可以删除该文件,删除指定文件的函数原型为:

其中,path为文件的路径。返回值为AW_OK时表示删除成功,否则,表示删除失败。范例程序详见程序清单11.17。
程序清单11.17 删除文件范例程序

11. 获取文件状态信息
对于一个文件,除基本数据外(使用读写接口操作的数据),还具有一些与文件相关的其它信息,比如:文件实际大小、文件占用大小、修改时间、访问权限等。这些信息统一被称为状态信息,可以通过aw_fstat()接口获取文件的状态信息,其函数原型为:

其中,fildes为文件句柄,buf为文件状态信息的缓存。返回值为AW_OK时表示获取成功,否则,表示获取失败。文件状态信息的类型为struct aw_stat,其完整定义如下:
(io/sys/aw_stat.h):

其中的绝大部分成员在当前系统中并未使用,预留给后续扩展。这里仅简要介绍几个常用的数据成员:st_mode、st_size、st_atim、st_mtim和st_ctim。
st_mode包含了文件类型及权限相关的信息,权限相关信息与创建文件时指定的mode参数一致。
st_size表示文件的实际长度。通常情况下,文件占用的磁盘空间会大于该值。如在FAT文件系统中,存储文件的基本单元为“簇”,即使文件小于基本的存储单元大小,也会占用一个完整的存储单元。文件占用的磁盘空间可由st_blksize和st_blocks获得,st_blksize表示存储单元的大小,st_blocks表示文件占用的存储单元个数,两者的乘积则表示文件占用的空间大小。
st_atim、st_mtim、st_ctim表示文件相关的时间,st_atim为最后访问文件的时间,st_mtim为最后修改文件内容的时间,st_ctim为最后修改文件状态的时间。在部分平台中,可能没有严格细分这些时间,而是统一的使用一个时间表示,此时,各个时间的值将是相同的。这些时间的类型为struct timespec,其表示精确日历时间,即:

精确日历时间中包含了秒和纳秒信息。可以通过将该时间转换为细分时间,得到年、月、日、时、分、秒等信息。获取文件状态信息的范例程序详见程序清单11.18。
程序清单11.18 获取文件状态信息的范例程序


和截断文件类似,AWorks也提供了另外一个功能相同的接口,可以通过文件名指定要获取状态信息的文件,使用起来更加便捷,其函数原型为:

其中,path为文件路径,buf为文件状态信息的缓存。返回AW_OK时表示获取成功,否则,表示获取失败。可以使用该接口简化程序清单11.18的第21、22、29共计3含代码,使用一行代码代替,即:

12. 修改文件时间
一个文件的存取和修改时间可以用 aw_utime() 函数更改,其函数原型为:

其中,path为文件的路径,times为设置的时间。struct aw_utimbuf类型的定义(io/aw_utime.h)如下:

其中,actime表示文件最近一次的访问时间,modtime表示文件最近一次的内容修改时间,它们的类型均为time_t,time_t是日历之间类型,即actime和modtime均使用日历时间表示。返回AW_OK时,表示时间设置成功,否则,表示时间设置失败。如设置文件访问时间和文件修改时间均为2016年8月26日09:32:30,则范例程序详见程序清单11.19。
程序清单11.19 修改文件时间的范例程序



程序中,首先使用aw_utime()修改了文件时间,然后使用aw_stat()获取文件的状态信息,以查看时间是否设置成功。
11.4 目录基本操作
目录相关的操作主要包括创建目录、打开目录、读取目录、关闭目录、删除目录等。相关接口的原型详见表11.5。
表11.5 目录基本操作相关接口

1. 创建目录
创建一个空目录,其函数原型为:

其中,path是待创建目录的完整路径,包括待创建目录的父目录和新目录的名字,如需在"/test"目录下创建一个"newdir"目录,则path为"/test/newdir",注意,必须保证父目录已存在,且父目录下不存在即将创建的同名目录。mode指定目录相关的权限,默认使用0777。
返回值为标准的错误号,若返回AW_OK,表示新目录创建成功,否则,表示新目录创建失败。如在"/test"目录下创建一个"newdir"目录,则范例程序详见程序清单11.20。
程序清单11.20 创建目录范例程序

若程序运行成功,则在TF卡中创建了一个newdir目录。为了验证操作是否成功,可以拔下TF卡,将TF卡通过读卡器连接到PC上(Windows系统),通过PC查看TF卡中的内容,TF卡目录的内容详见图11.4 (a),其中新增了newdir目录,且newdir当前是一个空目录,详见图11.4(b)。

图11.4 通过PC查看TF卡的内容(2)
可以尝试在newdir目录中新建文件,例如:

2. 打开目录
在目录操作中,遍历已存在的一个目录是一种常见的操作,即遍历一个目录下所有的子项(包括文件和子目录)。遍历过程主要分为3个步骤:打开目录、读取目录、关闭目录。
在遍历一个目录前,首先需要打开该目录,其函数原型为:

其中,dirname为目录名,如需打开根目录下的test目录,则其值为"/test"。返回值为指向一个目录对象的指针,目录类型struct aw_dir 在io/aw_dirent.h文件中定义,其具体定义用户无需掌握,仅需保存下该指针,后续使用该指针代表打开的目录即可,特别地,若返回值为NULL,则表示目录打开失败。打开目录的范例程序详见程序清单11.21。
程序清单11.21 打开目录范例程序

3. 读取目录
打开目录后,即可依次读取该目录中的各个子项(文件或子目录),获得它们的名字等信息,其函数原型为:

其中,dirp为指向目录对象的指针,可通过打开目录获得。返回值为目录项指针,即为本次读取的一条目录项,其类型struct aw_dirent的定义如下:

其中,d_ino为项目序列号,其值为一个整数,每个子项都有一个对应的序列号,在一个目录中,若共计有10个子项,则各子项的序列号依次为0 ~ 9。d_name为该子项的名字。
打开目录后首次调用读取目录接口,获得的子项序列号为0,要获取一个目录下所有的子项,可以多次调用读取目录接口,每次调用结束后,都会将序列号加1,下次读取时将读取到下一个子项。特别地,若读取目录的返回值为NULL,表示读取结束。读取一个目录下所有子项的范例程序详见程序清单11.22。
程序清单11.22 读取目录范例程序(1)

aw_readdir()接口通过返回值返回一个指向读取目录子项的指针,该指针指向的实际内存是由系统内部分配的静态内存,在多任务环境中,这份内存是共享的,因此,该接口不是线程安全的,例如,在一个任务中读取了一次目录,则静态内存中存放了本次读取的结果,其地址返回给用户,用户通过指针访问读取目录的结果。若在这个过程中,另外一个任务也读取了一次目录,则内存中的数据将发生改变,这将覆盖前一个任务读取目录的结果。由此可见,当多个任务同时访问一个目录时,必须使用互斥机制。
为此,AWorks提供了另外一个线程安全的接口:aw_readdir_r(),它们在功能上是完全一样的,唯一的不同是,使用该接口读取目录时,读取结果存储在用户提供的一段内存中,其原型为:

其中, dirp为指向目录对象的指针,可通过打开目录获得;entry为存储读取结果的缓存,result为一个二维指针,即一个指针的地址,程序执行结束后,指针的值即被设置为指向本次读取目录的结果。
若返回值为AW_OK,则读取成功,否则,读取失败。值得注意的是,当目录读取未达结尾,成功读取到一个子项时,由于读取的结果存储在entry指向的内存中,因此,result的值被设置为entry(即:*result=entry),当目录读取达到结尾时,result的值将被设置为NULL(即:*result=NULL)。范例程序详见程序清单11.23。
程序清单11.23 读取目录范例程序(2)

4. 关闭目录
若读取目录完毕,或不再需要读取目录时,则可以关闭目录,其函数原型为:

其中,dirp为指向目录对象的指针,可通过打开目录获得。返回值为AW_OK时表示关闭成功,否则,表示关闭失败。
综合打开目录、读取目录、关闭目录三个接口,遍历一个目录下所有子项的范例程序详见程序清单11.24。
程序清单11.24 遍历目录范例程序


5. 删除目录
当一个目录不再使用,可以删除该目录,删除指定目录的函数原型为:

其中,path为目录的路径。返回值为AW_OK时表示删除成功,否则,表示删除失败。该函数仅可用于删除一个空目录,若目录非空,则删除失败。范例程序详见程序清单11.25。
程序清单11.25 删除目录范例程序

11.5 微型数据库
AWorks提供了一个基于文件系统实现的微型数据库,用以管理信息记录,每条记录由“关键字”和“值”两部分构成,关键字可用于记录的查找、删除等。微型数据库是基于哈希表原理实现的,具有简洁、高效的特点。为了便于理解,本节首先对哈希表进行简要介绍,然后再介绍微型数据库的各个接口。
11.5.1 哈希表
在数据存储应用中,存储的记录往往都具有唯一的关键字,以便于管理。例如,为了管理学生信息(包含姓名、性别、身高、体重等),会为每个学生分配一个学号,通过学号就可以唯一的定位一个学生,这里的学号即为关键字。常见的身份证号也具有类似的作用。
假设需要设计一个信息管理系统,用于管理学生信息,可以将每条学生信息看作一条记录。
一条记录包含学号、姓名、性别、身高、体重等信息,可定义与学生记录对应的结构体类型,详见程序清单11.26。
程序清单11.26 学生信息类型定义

作为一个信息管理系统,首先要能够实现学生记录的存储,基于文件系统接口可以很容易实现:直接将记录写入到文件中即可。增加一条学生记录的范例程序详见程序清单11.27。
程序清单11.27 增加一条学生记录

程序中,假定了存储学生记录的文件名为:"/test/students.txt",这就要求系统中,将/test目录挂载到特定的存储器,比如SD卡或U盘等。增加一条记录的实现非常简单,仅仅是将p_info指向的学生记录顺序的存入了文件尾部,因此,使用这种方法增加学生记录的效率还是比较高的。
如果使用student_add()函数增加了若干学生记录,将学生记录存储在了文件中,接下来,最常见的操作就是根据学号查询学生信息。基于学生信息的存储方式,可以实现一个学生信息查询函数,范例程序详见程序清单11.28。
程序清单11.28 根据学号查询学生记录

由此可见,程序仅仅从文件头部顺序读取文件学生记录,逐一与待查找的学号进行比对,直到查找到与学号完全一致的学生记录。
上述简单的范例程序实现了记录的添加和查找。由于查找学生记录是采用顺序查找的方式,随着学生记录的增加,查找效率将逐步降低。例如,一所大学往往有几万学生,则使用该系统管理学生记录时,一次简单的查找则可能要顺序对比上万次学号,显然,效率不高。
如何以更高的效率实现查找呢?在查找算法中,非常经典高效的算法是“二分法查找”,按10000条记录算,最多也只需要比较14次(log210000)。但是,使用“二分法查找”的前提是信息必须有序排列,即要求学生记录必须按照学号从大到小或从小到大的顺序进行存储,这就导致在添加学生信息时,必须将学生记录按照学号顺序,插入到指定位置,而不能像程序清单11.27那样,简单的将信息添加至文件尾部。对于文件操作来讲,插入操作是非常繁琐的,若已经有大量学生记录按学号顺序存储在文件中,在此基础上再插入一条记录到这些记录的中间某个位置,则需要将其后的所有记录后移,以预留出一条记录的存储空间,这意味着需要将后续所有记录读出,再重新写入到其后的地址中。由此可见,虽然使用这种方法可以提高查找效率,却牺牲了添加信息的效率。
“顺序查找”管理方式牺牲了查找记录的效率,“二分法查找”牺牲了写入记录的效率。能否将二者折中一下呢?“二分法查找”的本质是每次缩小一半的查找范围,基于缩小查找范围的思想,可以尝试缩小每次“顺序查找”的范围。同样以10000条记录为例,为了缩小每次“顺序查找”的范围,将记录分为两个部分,例如,制定以下规则:学号小于某一值时,作为第一部分存储在某一文件中;反之,作为第二部分存储在另外一个文件中。
如此一来,在写入记录时,只需要多一条判断语句,对性能并没太大影响。而在查找时,只要根据学号判断出记录应存储在哪一个文件中,然后按照顺序查找的方式进行查找即可。此时,若用于分界的学号选择恰当,使两个部分的学生记录数量基本相同,则顺序查找需要比较的次数就从最大的10000次降低到了约5000次。由此可见,通过一个简单的方法,将信息分别存储在两个文件中,就可以明显地提高查找效率。
为了继续提高查找的效率,还可以将记录分为更多的部分,比如,分成250个部分,序号为0~ 249,若划分规则恰当,使各个部分的学生记录数量基本相同,则每个部分的记录数目就约为40条,此时,顺序查找需要比较的次数就仅需约40次即可!示意图详见图11.5。

图11.5 将记录分为多个部分
图11.5可以看作大小为250的“哈希表”,“哈希表”的每个表项对应了一部分记录。哈希表的核心思想是将一个很大范围的关键字空间(例如,学号为6字节,6字节数据共计48位,其表示的数值空间大小为:248,约280万亿,是一个相当大的范围),映射到一个较小的空间(范围序号:0 ~ 249,大小为250)。由于是大范围映射到小范围,因此可能有一部分关键字(学号)映射到同一个表项中,也就是每个表项可能包含多条记录。
哈希表的关键是确定映射关系,即如何将关键字(学号)映射到表项的序号,也就是将所有记录划分为多个部分的具体规则。当写入或查找一条记录时,可以通过映射关系确定该记录属于哪一部分。这个映射关系对应的函数即为“哈希函数”,其作用就是将学号转换为哈希表的表项序号。例如,假定学号是均匀分布的,则可以将6字节学号直接求和再对250取余,进而得到一个0 ~ 249的数,范例程序详见程序清单11.29。
程序清单11.29 映射关系——通过学号得到分组索引

db_id_to_idx()函数就是“哈希函数”,哈希函数的结果(分组索引)称之为“哈希值”。
“哈希函数”是整个哈希表的关键,哈希函数应尽可能确保记录均匀的分布到各个表项中,不能差异太大,极端地,若哈希函数选择有误,将所有记录分布到了一个表项中,那这样的哈希表将没有任何意义,因为每次查找记录又回到了最初的状态:遍历所有记录。
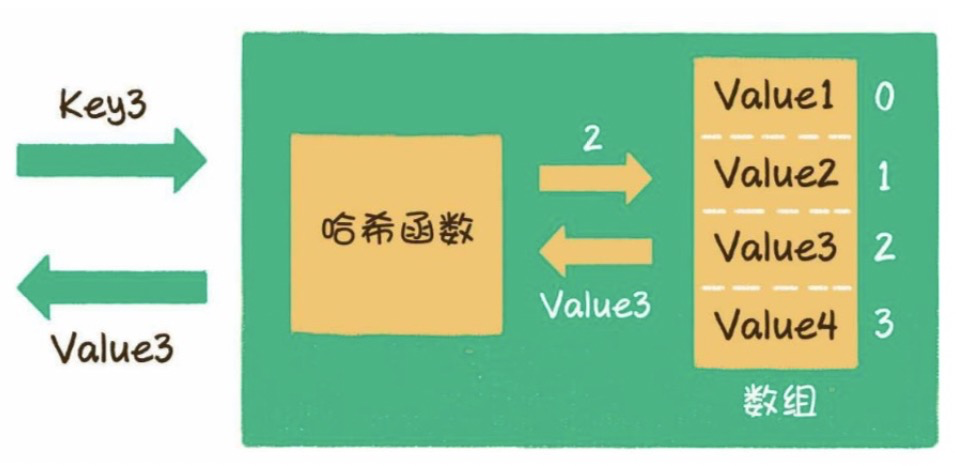
实际应用中,记录往往是动态管理的,可以随时动态添加、删除。因此,每一部分(哈希表的表项)包含的记录数也会动态增加或减少。为了便于动态管理每一部分的记录,各部分可以使用链表管理该部分中可能存在的多条记录,示意图详见图11.6,图中所示的链式哈希表结构就是AWorks中微型数据库原理。

图11.6 链式哈希表结构
11.5.2 微型数据库接口
前面简要介绍了哈希表的原理,AWorks提供了一个基于哈希表思想实现的微型数据库,提供了增加、删除、查找等接口,相关接口的原型详见表11.6。
表11.6 微型数据库接口(aw_db_micro_hash_kv.h)

微型数据库相关的文件和接口以“aw_db_micro_hash_kv”作为命名空间,其中,“aw_”表示AWorks,“db”表示数据库(data base),“micro”表示微型,hash_kv表示基于的是hash关键字和值的思想。
1. 定义数据库实例
所有接口的第一个参数均为
aw_db_micro_hash_kv_t类型的指针,用于指向待操作的数据库实例。该类型的具体定义(如具体包含哪些成员)用户无需关心,仅需在使用微型数据库前,使用该类型定义一个数据库实例即可,例如:

其中,students_db的地址即可作为各个接口p_db参数的实参传递。
2. 初始化
在使用数据库前,需要完成数据库的初始化,以指定哈希表大小、关键字长度、值长度以及存储整个数据库的文件名等信息。其函数原型为:

其中,p_db指向待初始化的数据库实例。size表示哈希表的大小,即表项的数目,如需设计图11.6所示的哈希表,由于其哈希表的大小为250,则该值应设置为250。key_size为关键字长度,例如,以学号为关键字,由于学号的长度为6字节,则该值应设置为6。
value_size表示记录中值的长度,以学生记录为例,一条学生记录包含学号、姓名、性别、身高、体重等信息。最初的学生记录对应的结构体类型详见程序清单11.26。在使用微型数据库时,关键字和值是不同的两个部分,均会被存储到文件中。因此,可以将关键字学号分离出来,剩余的信息作为一条学生记录的“值”。详见程序清单11.30。
程序清单11.30 学生记录信息类型(不包括关键字——学号)

基于此,value_size的值则应设置为:sizeof(student_t)。
pfn_hash用于指定一个哈希函数,其作用是将关键字转换为一个哈希值,哈希值即为哈希表的索引。其类型aw_db_micro_hash_kv_func_t定义如下:

该类型为一个函数指针类型,其指向函数的形参为关键字,返回值为哈希值(类型为无符号整数),哈希值将作为哈希表的索引。通过对哈希表的介绍可知,哈希函数的选择直接决定了记录的分布,必须尽可能地确保所有记录均匀地分布在各个表项中。不同的关键字数据具有不同的分布特性,因此,哈希函数需要由用户根据实际情况提供,简单的实现可以将关键字按字节求和后再对哈希表大小取余,详见程序清单11.31。
程序清单11.31 简易的哈希函数实现

其中,函数名hash_func_id_to_idx即可作为pfn_hash的实参传递。
file_name用于指定存储该数据库信息及所有记录的文件名,若一个系统中存在多个数据库(定义了多个数据库实例),则在初始化各个数据库时,为各个数据库指定的文件名应该不同,以使各个数据库使用不同的文件存储数据。在程序清单11.27和程序清单11.28所示的简易范例程序中,每次写入记录或查找记录前,都会执行一次打开文件操作,并在写入或查找结束后关闭文件。在实际应用中,可能会频繁的执行写入、查找等操作,这样就会导致频繁的打开、关闭文件,降低了程序运行的效率,为此,AWorks提供的数据库仅仅在初始化时打开文件,后续其它操作均无需再执行打开文件操作。若初始化时指定的文件名对应文件已经存在,则仅仅打开该文件,然后再该文件的基础上进行记录的管理(添加、删除等);若文件名对应文件不存在,则创建该文件,以建立一个全新的数据库(数据库中没有任何有效记录)。初始化数据库的范例程序详见程序清单11.32。
程序清单11.32 初始化数据库范例程序

3. 增加一条记录
该函数用于向数据库中增加一条记录,其函数原型为:

其中,p_db指向已经初始化的数据库实例。p_key指向本次增加记录的关键字,其长度必须与初始化指定的key_size一致。p_value指向本次增加记录的具体“值”。例如,待增加一条学生记录,其各项信息详见表11.7。
表11.7 待增加的学生信息举例
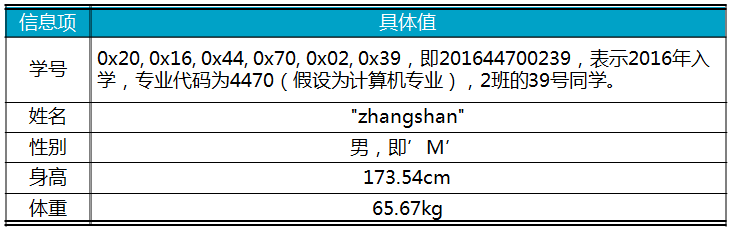
则向数据库中增加该学生记录的范例程序详见程序清单11.33。
程序清单11.33 增加记录范例程序

4. 根据关键字查找记录
向数据库中添加记录后,可以根据关键字查找记录的详细信息,查找记录的函数原型为:

其中,p_db指向数据库实例。p_key为输入参数,指向本次查找记录的关键字,关键字长度必须与初始化时指定的key_size一致。p_value为输出参数,返回本次查找到的记录。
例如,若使用程序清单11.33所示的范例程序增加了一条学生记录,作为测试,可以使用查找记录接口查找学号为201644700239的记录,以查看其对应的“值”信息是否与写入的信息一致。范例程序详见程序清单11.34。
程序清单11.34 根据关键字查找记录的范例程序

程序中,为了避免使用aw_kprintf()打印浮点数,将身高和体重分为整数部分和小数部分打印,最终等效于保留2位小数的浮点数打印效果。
5. 删除一条记录
通过该接口可以删除数据库中的一条记录,其函数原型为:

其中,p_db指向数据库实例。p_key指向本次需要删除记录的关键字,关键字长度必须与初始化时指定的key_size一致。
例如,若使用程序清单11.33所示的范例程序增加了一条学生记录,作为测试,可以将学号为201644700239的记录删除。范例程序详见程序清单11.35。
程序清单11.35 根据关键字删除记录的范例程序

使用程序清单11.35所示程序删除记录后,若再查找学号为201644700239的记录,将会查找失败。
6. 解初始化
与数据库初始化函数对应。当暂时不使用一个数据库时,可以执行该函数,以释放相关资源。注意,解初始化后,数据库中已经存储的内容保持不变。解初始化函数的原型为:

其中,p_db指向数据库实例。例如,在一次应用中,添加了100个学生记录,添加结束后,暂时不再使用该数据库,则可以解初始化该数据库,范例程序详见程序清单11.36。
程序清单11.36 解初始化范例程序

在初始化函数的介绍中提到,为了避免频繁的打开文件和关闭文件,在初始化时打开了文件,使得在添加记录、删除记录、查找记录时,无需再打开文件。与初始化函数对应,在解初始化函数中,关闭了文件。关闭文件后,文件中的内容保持不变。如需再次使用该数据库,则应该重新执行一次初始化操作。
上面介绍了各个接口的使用方法,基于这些接口,可以实现一个学生记录管理的综合范例程序,详见程序清单11.37。
程序清单11.37 微型数据库综合范例程序






测试程序主要由test_db_micro_hash_kv()完成,在aw_min()主程序中,仅仅是简单调用了该函数。在test_db_micro_hash_kv()函数中,首先初始化了一个数据库,然后向其中添加了100个学生记录(为了快捷产生这些记录,以随机数的方式自动生成,随机数无实际意义,仅供测试使用。同时,为了保证添加的学生学号唯一,在添加记录前,通过搜索接口查看是否存在该学号的学生,若存在,则不再重复添加)。接着测试了查找接口,查找最后添加的学生记录。然后测试删除接口,删除了最后添加的学生记录,删除成功后,再次查找将会失败。最后,所有操作执行完毕,解初始化数据库。
-
周立功
+关注
关注
38文章
130浏览量
38829 -
AWorks
+关注
关注
1文章
16浏览量
6116
原文标题:AWorks软件篇 — 文件系统
文章出处:【微信号:ZLG_zhiyuan,微信公众号:ZLG致远电子】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
新书创作谈:周立功教授数十年之心血力作《程序设计与数据结构》
【完整资料】《程序设计与数据结构》周立功数十年心血力作
数据结构的几个重要知识点
GPIB命令的数据结构
什么是数据结构
《程序设计与数据结构》——框架与重用

什么是数据结构?为什么要学习数据结构?数据结构的应用实例分析
算法和数据结构基础知识分享(上)
算法和数据结构基础知识分享(中)
算法和数据结构基础知识分享(下)
NetApp的数据结构是如何演变的

epoll的基础数据结构



评论