* 本文修改后的代码已上传到GitHub网站Apollo项目中。
{ 1 }
线程池技术简介
1线程池的定义
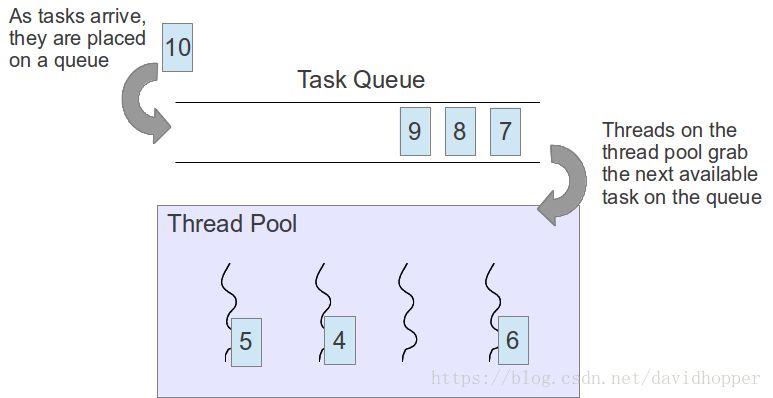
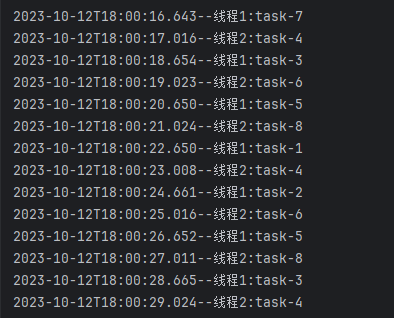
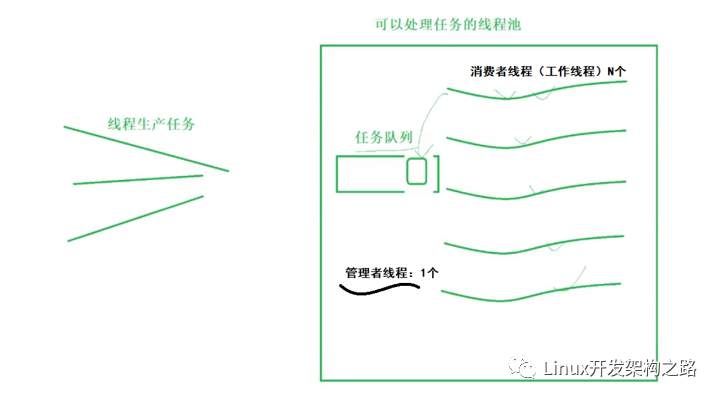
线程池是一种多线程形式,首先开启指定数量的后台工作线程,并将多个待执行任务添加到任务队列,然后将队列中的任务逐个交给空闲的工作线程执行(如下图所示)。
2使用线程池的原因
创建/销毁线程伴随着操作系统的资源开销,过于频繁的创建/销毁线程,会很大程度上影响处理效率。若创建线程消耗时间T1,执行任务消耗时间T2,销毁线程消耗时间T3,如果T1+T3>T2,则开启一个线程来执行一个任务就很不划算,而使用线程池缓存线程,就可利用已有的闲置线程来执行新任务,有效避免T1+T3带来的系统开销。
线程并发数量过多,抢占系统资源从而导致阻塞。我们知道线程会共享系统资源,如果同时执行的线程数量过多,可能会导致系统资源不足而产生操作卡顿甚至出现假死现象,运用线程池能有效地控制线程最大并发数,有效避免上述问题。
对线程进行一些简单的管理。比如:延时执行、定时循环执行等策略,运用线程池就较容易实现。
3C++中如何使用线程池
C++标准库不提供线程池,如需使用需自行撰写线程池类。GitHub中有多个线程池类的实现,Apollo项目也参考了其中的一个实现【https://github.com/vit-vit/CTPL】。
{ 2 }
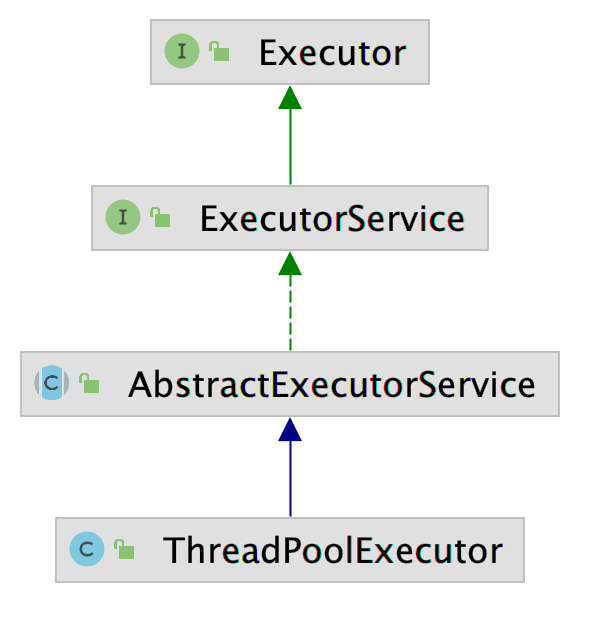
Apollo线程池类源代码分析
Apollo线程池文件位于[your_apollo_root_dir]/modules/common/util/ctpl_stl.h,包含任务队列类Queue和线程池类ThreadPool,其中Queue位于命名空间apollo::common::util::detail内,ThreadPool位于命名空间apollo::common::util内。
1任务队列类Queue
任务队列类Queue基于C++标准库的队列类std::queue实现,只是对push、pop和empty三个函数进行了加锁操作。
|
|
template class Queue { public: bool push(T const &value) { // 使用std::lock_guard效率更高 std::unique_lock lock(mutex_); q_.push(value); return true; } // deletes the retrieved element, do not use for non integral types bool pop(T &v) { // NOLINT // 使用std::lock_guard效率更高 std::unique_lock lock(mutex_); if (q_.empty()) { return false; } v = q_.front(); q_.pop(); return true; } bool empty() { // 使用std::lock_guard效率更高 std::unique_lock lock(mutex_); return q_.empty(); } private: std::queue q_; std::mutex mutex_;}; |
根据这篇博客【https://blog.csdn.net/tgxallen/article/details/73522233】的介绍,可使用std::lock_guard和std::unique_lock提供RAII(资源获取即初始化,Resource Acquisition Is Initialization,参见该网页【https://blog.csdn.net/doc_sgl/article/details/43028009】)风格的加锁操作,其中std::lock_guard的系统开销更小,std::unique_lock更为灵活(可适时解锁)。就我们的任务队列类Queue而言,不需要std::unique_lock提供的灵活性,因此使用std::lock_guard更为合适。另外,我还增加一个接受右值引用的push函数,以方便下文中的ThreadPool使用,修改后的类如下:
|
|
class Queue { public: bool push(const T &value) { std::lock_guard lock(mutex_); q_.push(value); return true; } // 增加一个接受右值引用的push函数 bool push(T &&value) { std::lock_guard lock(mutex_); q_.emplace(std::move(value)); return true; } // deletes the retrieved element, do not use for non integral types bool pop(T &v) { // NOLINT std::lock_guard lock(mutex_); if (q_.empty()) { return false; } v = q_.front(); q_.pop(); return true; } bool empty() { std::lock_guard lock(mutex_); return q_.empty(); } private: std::queue q_; std::mutex mutex_;}; |
2线程池类ThreadPool
线程池类ThreadPool的主要功能是创建n_threads个后台工作线程,将任务函数f包装成std::function的形式存入任务队列q_,根据当前工作线程空闲情况,适时从任务队列q_中提取一个任务函数并执行之。注意复制构造函数ThreadPool(const ThreadPool &)、移动构造函数ThreadPool(ThreadPool &&)、复制运算符ThreadPool &operator=(const ThreadPool &)、移动运算符ThreadPool &operator=(ThreadPool &&)全部设置为private,表明禁止使用这些函数。其实C++11标准完成可以通过在函数声明后加上= delete;的方式来禁用,源代码以注释的方式给出了这种实现方式。
下面分析该类中几个比较重要的成员函数。
2.2.1 Push函数
Push函数的作用是将任务函数f包装成std::function的形式存入任务队列q_。Push函数有两个版本,一个允许任务函数f带可变参数Rest &&... rest,一个不允许任务函数f带额外参数,函数体内部代码大同小异,下面以带可变参数的版本进行分析,代码如下:
|
|
template auto Push(F &&f, Rest &&... rest) -> std::future { // std::placeholders::_1表示通过std::bind函数绑定后得到的异步任务对象接受的第一个参数是自由参数 auto pck = std::make_shared>( std::bind(std::forward(f), std::placeholders::_1, std::forward(rest)...)); // 最好使用std::make_shared创建智能指针对象,后面不用操心指针内存的释放 // auto _f = std::make_shared>([pck](int id) { (*pck)(id); }); auto _f = new std::function([pck](int id) { (*pck)(id); }); q_.push(_f); // 这里不要加锁,否则易引起死锁 std::unique_lock lock(mutex_); cv_.notify_one(); return pck->get_future();} |
Push函数的返回值为一个std::future对象,std::future对象内存储的数据类型由(f(0, rest...)函数的返回值类型确定,decltype(f(0, rest...))的作用就是获取(f(0, rest...)函数的返回值类型。std::future提供一种异步操作结果的访问机制,从字面意思来理解,它表示未来,我觉得这个名字非常贴切,因为一个异步操作的结果不可能马上获取,只能在未来某个时候得到。关于std::future,这篇博客【https://blog.csdn.net/yockie/article/details/50595958】讲得挺不错,大家可以借鉴。
因为任务函数f的声明各式各样,有的不带参数,有的接受一个参数,有的接受两个参数……因此不能将其直接存储到任务队列q_,于是先利用std::bind函数将其包装为一个异步操作任务std::packaged_task对象pck(接受一个整型参数,返回值类型为(f(0, rest...)函数的返回值类型),再利用Lambda表达式将pck包装为一个std::function对象,这样就可以存储到任务队列q_中了。这里原作者直接使用new运算符创建裸指针_f,后面还需想办法释放指针内存,我认为不是很合适,使用std::make_shared创建智能指针可以自动管理内存,更加省事,但使用std::shared_ptr>智能指针就不能使用Queue::push(const T &value)版本将其存储到任务队列,为此我在Queue类中添加了一个接受右值引用参数的版本Queue::push(T &&value),使用该版本就可以顺利将智能指针存储进去了。
接下来,使用条件变量std::condition_variable对象cv_.notify_one()函数通知各个线程任务队列已经发生了改变,让空闲线程赶紧从任务队列中拉取新任务执行;最后通过pck->get_future()返回一个std::future对象,以便调用者能从中取出函数执行完毕后的返回值。
我看过很多C++多线程方面的书籍(”C++ Concurrency in Action”比较经典),一般不对cv_.notify_one();进行加锁操作,因为这样做除了降低效率外,还很容易引起死锁,故需去除加锁操作,具体原因参见该网页【https://stackoverflow.com/questions/17101922/do-i-have-to-acquire-lock-before-calling-condition-variable-notify-one】以及另一个网页【http://en.cppreference.com/w/cpp/thread/condition_variable/notify_one】。
以下是修改后的版本:
|
|
template auto Push(F &&f, Rest &&... rest) -> std::future { auto pck = std::make_shared>( std::bind(std::forward(f), std::placeholders::_1, std::forward(rest)...)); auto _f = std::make_shared>( [pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f)); cv_.notify_one(); return pck->get_future();} |
2.2.2Pop函数
Pop函数的作用是从任务队列q_中取出并返回一个任务,代码如下:
|
|
std::function Pop() { std::function *_f = nullptr; q_.pop(_f); // 如果任务队列q_中存储的是智能指针,就不必使用这种小花招来释放内存了。 std::unique_ptr> func( _f); // at return, delete the function even if an exception occurred std::function f; if (_f) f = *_f; return f;} |
首先,从从任务队列q_中取出一个任务函数对象的裸指针_f,若非空,则将其赋值给std::function f并返回。该函数里使用一个小花招,即创建一个智能指针std::unique_ptr> func(_f),当超出该对象的作用域时,就会在其析构函数中调用delete运算符释放内存。如果任务队列q_中存储的是智能指针,就不必使用这种小花招来释放内存了。
以下是修改后的版本:
|
|
std::shared_ptr> Pop() { std::shared_ptr> f; q_.pop(f); return f;} |
2.2.3Stop函数
Stop函数的作用停止线程池工作,若不允许等待,则直接停止当前正在执行的工作线程,同时清空任务队列;若允许等待,则等待当前正在执行的工作线程完成,代码如下:
|
|
void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { *(flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if (is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command to finish } { // 这里不要加锁,否则易引起死锁 std::unique_lock lock(mutex_); cv_.notify_all(); // stop all waiting threads } for (int i = 0; i < static_cast(threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if there were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // therefore delete them here ClearQueue(); threads_.clear(); flags_.clear();} |
函数中的布尔变量is_stop_、is_done_、flags_[i]为什么都不用加锁呢?这是因为它们都是原子类型std::atomic,所谓原子类型就是一条CPU指令就能完成取值或写值操作的变量类型。C++标准可保证std::atomic类型变量在任何架构操作系统中均只使用一条CPU指令就可完成取值或写值操作,其他形如std::atomic的类型,虽然将其声明为原子类型,但在某些架构操作系统中,并不能只使用一条CPU指令完成取值或写值操作。综上所述,std::atomic类型的变量可以在多线程中不加锁操作。
根据2.2.1节的分析,cv_.notify_all();的加锁操作应去除。
修改后的代码如下:
|
|
void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { *(flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if (is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command to finish } cv_.notify_all(); // stop all waiting threads for (int i = 0; i < static_cast(threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if there were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // therefore delete them here ClearQueue(); threads_.clear(); flags_.clear();} |
2.2.4ClearQueue函数
ClearQueue函数的作用是清空任务队列q_,代码如下:
|
|
void ClearQueue() { std::function *_f; // empty the queue while (q_.pop(_f)) { delete _f; }} |
使用while循环从任务队列q_中逐个弹出任务函数指针_f,因为_f使用new运算符创建,故需使用delete运算符删除以释放内存。如果任务队列q_中存储的是智能指针,就不必手工删除对象来释放内存了。
以下是使用智能指针的版本:
|
|
void ClearQueue() { std::shared_ptr> f; // empty the queue while (q_.pop(f)) { // do nothing } } |
2.2.5Resize函数
Resize函数的作用是更改线程池内工作线程的数量,代码如下:
|
|
void Resize(const int n_threads) { if (!is_stop_ && !is_done_) { int old_n_threads = static_cast(threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) { flags_[i] = std::make_shared>(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; --i) { *(flags_[i]) = true; // this thread will finish threads_[i]->detach(); } { // stop the detached threads that were waiting // 这里不要加锁,否则易引起死锁 std::unique_lock lock(mutex_); cv_.notify_all(); } // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not originals flags_.resize(n_threads); } }} |
如果两个变量is_stop_、is_done_都不为真,表明线程池仍在使用,可以更改线程池内工作线程的数量,否则没必要对一个停用的线程池更改工作线程的数量。若新线程数n_threads大于当前的工作线程数old_n_threads,则将工作线程数组threads_和线程标志数组flags_的尺寸修改为新数目,同时使用for循环调用SetThread(i)函数逐个重新创建工作线程;若新线程数n_threads小于当前的工作线程数old_n_threads,则将先完成old_n_threads - n_threads个线程正在执行的任务,之后将工作线程数组threads_和线程标志数组flags_的尺寸修改为新数目。
根据2.2.1节的分析,cv_.notify_all();的加锁操作应去除,具体原因参见该网页
注意:Resize函数很危险,应尽量少调用,若必须调用,则应当在创建线程池的那个线程内调用,而不要在其他线程中调用。
修改的代码如下:
|
|
void Resize(const int n_threads) { if (!is_stop_ && !is_done_) { int old_n_threads = static_cast(threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) { flags_[i] = std::make_shared>(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; --i) { *(flags_[i]) = true; // this thread will finish threads_[i]->detach(); } // stop the detached threads that were waiting cv_.notify_all(); // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not originals flags_.resize(n_threads); } }} |
2.2.6SetThread函数
SetThread函数的作用重新创建指定序号i的工作线程,代码如下:
|
|
void SetThread(int i) { std::shared_ptr> flag( flags_[i]); // a copy of the shared ptr to the flag auto f = [this, i, flag /* a copy of the shared ptr to the flag */]() { std::atomic &_flag = *flag; std::function *_f; bool is_pop_ = q_.pop(_f); while (true) { while (is_pop_) { // if there is anything in the queue // 如果任务队列q_中存储的是智能指针,就不必使用这种小花招来释放内存了。 std::unique_ptr> func( _f); // at return, delete the function even if an exception // occurred // 执行任务函数 (*_f)(i); if (_flag) { // the thread is wanted to stop, return even if the queue is not // empty yet return; } else { is_pop_ = q_.pop(_f); } } // the queue is empty here, wait for the next command // 这里必须使用std::unique_lock,因为后面条件变量cv_等待期间,需要解锁。 std::unique_lock lock(mutex_); ++n_waiting_; // 等待任务队列传来的新任务 cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || is_done_ || _flag; }); --n_waiting_; if (!is_pop_) { // if the queue is empty and is_done_ == true or *flag // then return return; } } }; threads_[i].reset( new std::thread(f)); // compiler may not support std::make_unique() } |
上述代码看起来比较复杂,实际上只有三条语句,第一条是std::shared_ptr> flag(flags_[i]);,即使用flags_[i]来初始化标志变量flag;第二条看起来很长,实际上就是创建一个Lambda表达式变量f;第三条是threads_[i].reset(new std::thread(f));,使用Lambda表达式变量f作为工作线程的任务函数,创建序号为i的工作线程。
那么Lambda表达式变量f何时启动呢?当任务队列q_.pop(_f)的返回值为true时,表明从任务队列q_中取到了一个新任务,于是调用(*_f)(i);执行之,如果当前任务队列没有任务,则使用:
|
|
cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || is_done_ || _flag;}); |
等待新任务的到来,在新任务到来之前,当前工作线程处于休眠状态。
该函数同样使用一个小花招,即创建一个智能指针std::unique_ptr> func(_f),当超出该对象的作用域时,就会在其析构函数中调用delete运算符释放内存。如果任务队列q_中存储的是智能指针,就不必使用这种小花招来释放内存了。
2.2.7修改后的ThreadPool类代码
为完整起见,这里给出修改后的ThreadPool类代码。
|
|
class ThreadPool { public: ThreadPool() { Init(); } explicit ThreadPool(int n_threads) { Init(); Resize(n_threads); } // the destructor waits for all the functions in the queue to be finished ~ThreadPool() { Stop(true); } // get the number of running threads in the pool int size() { return static_cast(threads_.size()); } // number of idle threads int NumIdle() { return n_waiting_; } std::thread &GetThread(const int i) { return *(threads_[i]); } // change the number of threads in the pool // should be called from one thread, otherwise be careful to not interleave, // also with stop() // n_threads must be >= 0 void Resize(const int n_threads) { if (!is_stop_ && !is_done_) { int old_n_threads = static_cast(threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) { flags_[i] = std::make_shared>(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; --i) { *(flags_[i]) = true; // this thread will finish threads_[i]->detach(); } // stop the detached threads that were waiting cv_.notify_all(); // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not originals flags_.resize(n_threads); } } } // empty the queue void ClearQueue() { std::shared_ptr> f; // empty the queue while (q_.pop(f)) { // do nothing } } // pops a functional wrapper to the original function std::shared_ptr> Pop() { std::shared_ptr> f; q_.pop(f); return f; } // wait for all computing threads to finish and stop all threads // may be called asynchronously to not pause the calling thread while waiting // if is_wait == true, all the functions in the queue are run, otherwise the // queue is cleared without running the functions void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { *(flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if (is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command to finish } cv_.notify_all(); // stop all waiting threads for (int i = 0; i < static_cast(threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if there were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // therefore delete them here ClearQueue(); threads_.clear(); flags_.clear(); } template auto Push(F &&f, Rest &&... rest) -> std::future { auto pck = std::make_shared>( std::bind(std::forward(f), std::placeholders::_1, std::forward(rest)...)); auto _f = std::make_shared>( [pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f)); cv_.notify_one(); return pck->get_future(); } // run the user's function that excepts argument int - id of the running // thread. returned value is templatized // operator returns std::future, where the user can get the result and rethrow // the catched exceptins template auto Push(F &&f) -> std::future { auto pck = std::make_shared>( std::forward(f)); auto _f = std::make_shared>( [pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f)); cv_.notify_one(); return pck->get_future(); } private: // deleted ThreadPool(const ThreadPool &); // = delete; ThreadPool(ThreadPool &&); // = delete; ThreadPool &operator=(const ThreadPool &); // = delete; ThreadPool &operator=(ThreadPool &&); // = delete; void SetThread(int i) { std::shared_ptr> flag( flags_[i]); // a copy of the shared ptr to the flag auto f = [this, i, flag /* a copy of the shared ptr to the flag */]() { std::atomic &_flag = *flag; std::shared_ptr> _f; bool is_pop_ = q_.pop(_f); while (true) { while (is_pop_) { // if there is anything in the queue (*_f)(i); if (_flag) { // the thread is wanted to stop, return even if the queue is not // empty yet return; } else { is_pop_ = q_.pop(_f); } } // the queue is empty here, wait for the next command { std::unique_lock lock(mutex_); ++n_waiting_; cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || is_done_ || _flag; }); --n_waiting_; if (!is_pop_) { // if the queue is empty and is_done_ == true or *flag // then return return; } } } }; threads_[i].reset( new std::thread(f)); // compiler may not support std::make_unique() } void Init() { is_stop_ = false; is_done_ = false; n_waiting_ = 0; } std::vector> threads_; std::vector>> flags_; detail::Queue>> q_; std::atomic is_done_; std::atomic is_stop_; std::atomic n_waiting_; // how many threads are waiting std::mutex mutex_; std::condition_variable cv_;}; |
2.2.8增加的单元测试代码
为检验修改后代码的正确性,增添如下单元测试代码。第一个待测试函数filter_duplicates_str接受的第一个参数为一个整型ID值,我在测试代码中只是将其作为一个占位符,实际并未使用,后面接受四个C风格字符串,该函数的任务是去除四个字符串中的重复词并把去重后的结果按字母升序排列,结果以std::string的形式返回;第二个待测试函数filter_duplicates只接受的一个整型ID值参数,我在测试代码中只是将其作为一个占位符,实际并未使用,该函数的任务是去除一串固定字符串中的重复词并把去重后的结果按字母升序排列,结果以std::string的形式返回。因为C++编译器不能推导出重载函数的正确版本,因此第二个待测函数并未使用重载函数形式。两个待测函数均使用线程池执行1000次,最后检查返回结果与预期结果的一致性。
|
|
#include "modules/common/util/ctpl_stl.h"#include #include #include #include #include #include #include "gtest/gtest.h"namespace apollo {namespace common {namespace util {namespace {// ...// Attention: don't use overloaded functions, otherwise the compiler can't// deduce the correct edition.std::string filter_duplicates_str(int id, const char* str1, const char* str2, const char* str3, const char* str4) { // id is unused. std::stringstream ss_in; ss_in << str1 << " " << str2 << " " << str3 << " " << str4; std::set string_set; std::istream_iterator beg(ss_in); std::istream_iterator end; std::copy(beg, end, std::inserter(string_set, string_set.end())); std::stringstream ss_out; std::copy(std::begin(string_set), std::end(string_set), std::ostream_iterator(ss_out, " ")); return ss_out.str();}std::string filter_duplicates(int id) { // id is unused. std::stringstream ss_in; ss_in << "a a b b b c foo foo bar foobar foobar hello world hello hello world"; std::set string_set; std::istream_iterator beg(ss_in); std::istream_iterator end; std::copy(beg, end, std::inserter(string_set, string_set.end())); std::stringstream ss_out; std::copy(std::begin(string_set), std::end(string_set), std::ostream_iterator(ss_out, " ")); return ss_out.str();}} // namespaceTEST(ThreadPool, filter_duplicates) { const unsigned int hardware_threads = std::thread::hardware_concurrency(); const unsigned int threads = std::min(hardware_threads != 0 ? hardware_threads : 2, 50U); ThreadPool p(threads); std::vector> futures1, futures2; for (int i = 0; i < 1000; ++i) { futures1.push_back(std::move(p.Push( filter_duplicates_str, "thread pthread", "pthread thread good news", "today is a good day", "she is a six years old girl"))); futures2.push_back(std::move(p.Push(filter_duplicates))); } for (int i = 0; i < 1000; ++i) { std::string result1 = futures1[i].get(); std::string result2 = futures2[i].get(); EXPECT_STREQ( result1.c_str(), "a day girl good is news old pthread she six thread today years "); EXPECT_STREQ(result2.c_str(), "a b bar c foo foobar hello world "); }}} // namespace util} // namespace common} // namespace apollo |
{ 3 }
Apollo Planning模块对于线程池的使用分析
Apollo Planning模块通过PlanningThreadPool类来完成对线程池ThreadPool的包装调用。PlanningThreadPool类位于头文件[your_apollo_root_dir]/modules/planning/common/planning_thread_pool.h及对应的实现文件[your_apollo_root_dir]/modules/planning/common/planning_thread_pool.cc中,位于命名空间apollo::planning内。
1PlanningThreadPool类
PlanningThreadPool类的声明如下:
|
|
class PlanningThreadPool { public: void Init(); void Stop() { if (thread_pool_) { thread_pool_->Stop(true); } } template void Push(F &&f, Rest &&... rest) { func_.push_back(std::move(thread_pool_->Push(f, rest...))); } template void Push(F &&f) { func_.push_back(std::move(thread_pool_->Push(f))); } void Synchronize(); private: std::unique_ptr thread_pool_; bool is_initialized = false; // 这里的func_用得非常不恰当,因为这里保存的是std::future对象, // 而非std::function对象,将其修改为futures_很有必要。 std::vector> func_; DECLARE_SINGLETON(PlanningThreadPool);}; |
PlanningThreadPool通过宏DECLARE_SINGLETON定义一个单实例类,因此不能直接在栈(stack)和堆(heap)上创建该类对象,而只能通过PlanningThreadPool::instance()获取该类的唯一实例。该类中的成员变量func_非常具有误导性,实际上它是一个保存着多个std::future对象的动态数组,而不是保存std::function对象,也就是说它保存的是函数的异步返回值对象,而非异步函数对象本身,因此这里将其修改为futures_很有必要。
2PlanningThreadPool类的使用
在Planning模块使用PlanningThreadPool类的步骤如下:
3.2.1初始化线程池
在Planning::Init()函数(位于[your_apollo_root_dir]/modules/planning/planning.cc)中添加如下语句完成PlanningThreadPool类对象的初始化:
|
|
// initialize planning thread pool PlanningThreadPool::instance()->Init(); |
3.2.2 利用线程池完成并发处理
在合适的位置调用线程池完成某个功能的并发处理,一般而言是在某个循环体内。注意:需进行并发处理的任务,相互之间不能有先后依赖关系,因为使用线程池执行并发任务时根本不知道哪个任务会先执行,哪个任务会后执行。
Planning模块目前在以下几处使用了线程池:
ReferenceLineInfo::AddObstacles函数ReferenceLineInfo::AddObstacles函数(位于[your_apollo_root_dir]/modules/planning/common/reference_line_info.cc中)在for循环内使用PlanningThreadPool::instance()->Push添加线程池任务,用于增加当前的障碍物信息,使用PlanningThreadPool::instance()->Synchronize()等待线程池任务全部完成。
|
|
bool ReferenceLineInfo::AddObstacles(const std::vector& obstacles) {if (FLAGS_use_multi_thread_to_add_obstacles) {std::vector ret(obstacles.size(), 0);for (size_t i = 0; i < obstacles.size(); ++i) { const auto* obstacle = obstacles.at(i); PlanningThreadPool::instance()->Push(std::bind( &ReferenceLineInfo::AddObstacleHelper, this, obstacle, &(ret[i])));}PlanningThreadPool::instance()->Synchronize();if (std::find(ret.begin(), ret.end(), 0) != ret.end()) { return false;}} else {// ...}return true;} |
DPRoadGraph::GenerateMinCostPath函数DPRoadGraph::GenerateMinCostPath函数(位于[your_apollo_root_dir]/modules/planning/tasks/dp_poly_path/dp_road_graph.cc中)在每级航点(way point)上多个横向采样点的for循环内使用PlanningThreadPool::instance()->Push添加线程池任务,用于计算本级航点的最小代价,使用PlanningThreadPool::instance()->Synchronize()等待线程池任务全部完成。
|
|
bool DPRoadGraph::GenerateMinCostPath( const std::vector &obstacles, std::vector *min_cost_path) { // ... for (std::size_t level = 1; level < path_waypoints.size(); ++level) { const auto &prev_dp_nodes = graph_nodes.back(); const auto &level_points = path_waypoints[level]; graph_nodes.emplace_back(); for (size_t i = 0; i < level_points.size(); ++i) { const auto &cur_point = level_points[i]; graph_nodes.back().emplace_back(cur_point, nullptr); auto &cur_node = graph_nodes.back().back(); if (FLAGS_enable_multi_thread_in_dp_poly_path) { PlanningThreadPool::instance()->Push(std::bind( &DPRoadGraph::UpdateNode, this, std::ref(prev_dp_nodes), level, total_level, &trajectory_cost, &(front), &(cur_node))); } else { UpdateNode(prev_dp_nodes, level, total_level, &trajectory_cost, &front, &cur_node); } } if (FLAGS_enable_multi_thread_in_dp_poly_path) { PlanningThreadPool::instance()->Synchronize(); } } // ...} |
DpStGraph::CalculateTotalCost函数DpStGraph::CalculateTotalCost函数(位于[your_apollo_root_dir]/modules/planning/tasks/dp_st_speed/dp_st_graph.cc中)在for循环内使用PlanningThreadPool::instance()->Push添加线程池任务,对于时间采样值c上的不同距离采样值r: next_lowest_row<=r<=next_highest_row计算抵达节点(c, r)的最小总代价,使用PlanningThreadPool::instance()->Synchronize()等待线程池任务全部完成。
|
|
Status DpStGraph::CalculateTotalCost() { // col and row are for STGraph // t corresponding to col // s corresponding to row uint32_t next_highest_row = 0; uint32_t next_lowest_row = 0; for (size_t c = 0; c < cost_table_.size(); ++c) { int highest_row = 0; int lowest_row = cost_table_.back().size() - 1; for (uint32_t r = next_lowest_row; r <= next_highest_row; ++r) { if (FLAGS_enable_multi_thread_in_dp_st_graph) { PlanningThreadPool::instance()->Push( std::bind(&DpStGraph::CalculateCostAt, this, c, r)); } else { CalculateCostAt(c, r); } } if (FLAGS_enable_multi_thread_in_dp_st_graph) { PlanningThreadPool::instance()->Synchronize(); } for (uint32_t r = next_lowest_row; r <= next_highest_row; ++r) { const auto& cost_cr = cost_table_[c][r]; if (cost_cr.total_cost() < std::numeric_limits::infinity()) { int h_r = 0; int l_r = 0; GetRowRange(cost_cr, &h_r, &l_r); highest_row = std::max(highest_row, h_r); lowest_row = std::min(lowest_row, l_r); } } next_highest_row = highest_row; next_lowest_row = lowest_row; } return Status::OK();} |
3.2.3 销毁线程池
在Planning::Stop()函数(位于[your_apollo_root_dir]/modules/planning/planning.cc)中添加如下语句以便 销毁线程池:
|
1 |
PlanningThreadPool::instance()->Stop(); |
自Apollo平台开放已来,我们收到了大量开发者的咨询和反馈,越来越多开发者基于Apollo擦出了更多的火花,并愿意将自己的成果贡献出来,这充分体现了Apollo『贡献越多,获得越多』的开源精神。为此我们开设了『开发者说』板块,希望开发者们能够踊跃投稿,更好地为广大自动驾驶开发者营造一个共享交流的平台!
 线程池技术简介与Apollo线程池类源代码分析
线程池技术简介与Apollo线程池类源代码分析






 工商网监
工商网监
评论