 我们目前在机器学习方面的进展有多可靠?
我们目前在机器学习方面的进展有多可靠?
导语:可以这样说,对机器学习的进展进行正确评估是很微妙的。毕竟,学习算法的目标是生成一个能够很好地泛化到不可见数据中的模型。因此,为了理解当前机器学习进展的可靠性如何,加州大学伯克利分校(UC Berkeley)和麻省理工学院(MIT)的科学家们设计并开展了一种新的再现性研究。其主要目标是衡量当代分类器从相同分布中泛化到新的、真正不可见数据中的程度如何。
可以这样说,机器学习目前主要是由聚焦于一些关键任务的改进上的实验性研究所主导的。但是,性能表现最佳的模型的令人印象深刻的准确性是值得怀疑的,因为用相同的测试集来选择这些模型已经很多年了。为了理解过度拟合(overfitting)的危险,我们通过创建一个真正看不见的图像的新测试集来衡量CIFAR-10分类器的准确性。尽管我们确保新测试集尽可能接近原始数据分布,但我们发现大部分深度学习模型的精确度大幅下降(4%至10%)。然而,具有较高原始精确度的较新模型显示出较小的下降和较好的整体性能,这表明这种下降可能不是由于基于适应性的过度拟合造成的。相反,我们将我们的结果视为证据,证明当前的准确性是脆弱的,并且易受数据分布中的微小自然变化的影响。
在过去五年中,机器学习已经成为一个决定性的实验领域。在深度学习领域大量研究的推动下,大部分已发表的论文都采用了一种范式,即一种新的学习技术出现的主要理由是其在几个关键基准上的改进性性能表现。与此同时,对于为什么现在提出的技术相对于之前的研究来说具有更可靠的改进,几乎没有什么解释。相反,我们的进步意识很大程度上取决于少数标准基准,如CIFAR-10、ImageNet或MuJoCo。这就提出了一个关键问题:
我们目前在机器学习方面的进展有多可靠?
可以这样说,对机器学习的进展进行正确评估是很微妙的。毕竟,学习算法的目标是生成一个能够很好地泛化到看不见的数据中的模型。由于我们通常无法访问真实数据分布,因此替代性地,我们会在单独的测试集上评估一个模型的性能。而只要我们不使用测试集来选择我们的模型,这就确实是一个有原则的评估协议。
图1:从新的和原始的测试集中进行的类均衡随机抽取结果。
不幸的是,我们通常对相同分布中的新数据的访问受限。现如今,人们已经普遍接受在整个算法和模型设计过程中多次重复使用相同的测试集。这种做法的示例非常丰富,包括在单一发布产品中调整超参数(层数等),并且在其他研究人员的各种发布产品的研究上进行架构构建。尽管将新模型与以前的结果进行比较是自然而然的愿望,但显然目前的研究方法破坏了分类器独立于测试集的关键性假设。这种不匹配带来了明显的危险,因为研究社区可以很容易地设计一些模型,但这些模型只能在特定的测试集上运行良好,实际上却不能推泛化到新的数据中。
因此,为了理解当前机器学习进展的可靠性如何,我们设计并开展了一种新的再现性研究。其主要目标是衡量当代分类器从相同分布中泛化到新的、真正不可见的数据中的程度如何。我们聚焦于标准的CIFAR-10数据集,因为它的透明性创建过程使其特别适合于此任务。而且,CIFAR-10现在已经成为近10年来研究的热点。由于这个过程的竞争性,这是一个很好的测试案例,用于调查适应性是否导致过度拟合。
过度拟合
我们的实验是否显示过度拟合?这可以说是对我们的结果进行解释时的主要问题。准确地说,我们首先定义过度拟合的两个概念:
•训练集过度拟合:量化过度拟合的一种方法是确定训练精确度和测试精确度之间的差异。需要注意的是,我们实验中的深度神经网络通常达到100%的训练精确度。所以这种过度拟合的概念已经出现在现有的数据集上。
•测试集过度拟合:过度拟合的另一个概念是测试精确度和基础数据分布的精确度之间的差距。通过将模型设计选择适配于测试集,我们关心的是我们隐含地将模型拟合到测试集。然后,测试精确度作为在真正看不见的数据上性能的精确衡量,将失去其有效性。
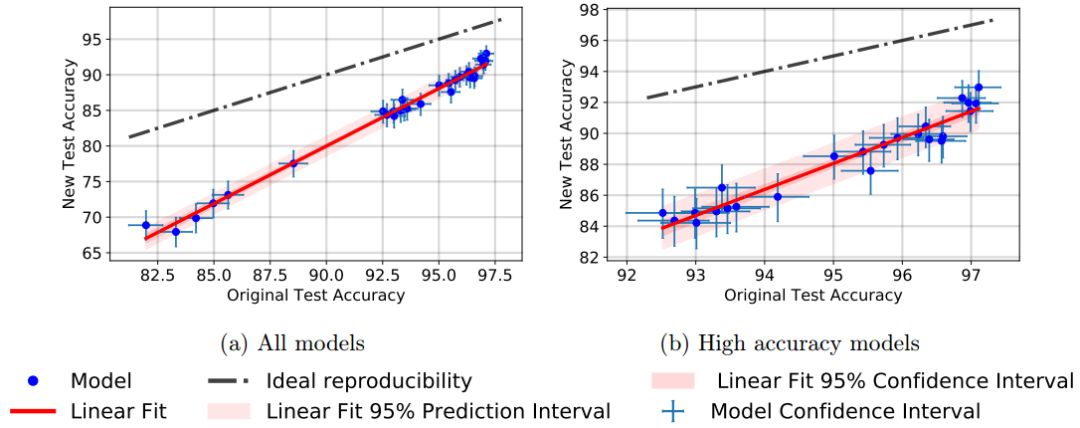
图2:新测试集的模型精确度VS原始测试集的模型精确度
由于机器学习的总体目标是泛化到看不见的数据中,所以我们认为,第二个概念,通过测试集自适应性事物过度拟合更为重要。令人惊讶的是,我们的研究结果显示在CIFAR-10上没有出现这种过度拟合的迹象。尽管在这个数据集上有多年的竞争自适应性,但真正持有的数据并没有停滞不前。事实上,在我们的新测试集中,性能最好的模型要比更多已建立的基线更具优势。尽管这种趋势与通过适应性的过度拟合所表明的相反。虽然一个确凿的图片需要进一步的复制实验,但我们认为我们的结果是支持基于竞争的方法来提高精确度分数的。
我们注意到,可以阅读Blum和Hardt的Ladder算法的分析来支持这一说法。事实上,他们表明,通过加入对标准机器学习竞赛的小修改,可以避免那种通过积极的适应性来实现的过度拟合。我们的结果显示,即使没有这些修改,基于测试误差的模型调整也不会导致标准数据集的过度拟合。
分布位移(distribution shift)
尽管我们的结果不支持基于适应性的过度拟合的假设,但仍需要对原始精确度分数和新精确度分数之间的显著差距进行解释。我们认为这种差距是原始CIFAR-10数据集与我们新测试集之间的小分布位移的结果。尽管我们努力复制CIFAR-10的创建过程,但这种差距很大,影响了所有模型,从而出现这种情况。通常,对于数据生成过程中的特定变化(例如,照明条件的变化)或对抗性环境中的最坏情况攻击,我们就会研究分布位移。我们的实验更加温和,并没有带来这些挑战。尽管如此,所有模型的精确度下降了4-15%,误差率的相对增加高达3倍。这表明目前的CIFAR-10分类器难以泛化到图像数据的自然变化中。
未来的研究
具体的未来实验应该探索竞争方法在其他数据集(例如ImageNet)和其他任务(如语言建模)上是否同样对过度拟合具有复原性。这里的一个重要方面是确保新测试集的数据分布尽可能地接近原始数据集。此外,我们应该了解什么类型的自然发生的分布变化对图像分类器是具有挑战性的。
更广泛地说,我们将我们的结果看作是对机器学习研究进行更全面评估的动机。目前,主要的范式是提出一种新的算法并评估其在现有数据上的性能。不幸的是,这些改进在多大程度上可以进行广泛适用,人们往往知之甚少。为了真正理解泛化问题,更多的研究应该收集有洞察力的新数据并评估现有算法在这些数据上的性能表现。由于我们现在在开源代码库中拥有大量预先注册的分类器,因此此类研究将符合公认的统计有效研究标准。重要的是要注意区分机器学习中的当前可再现性性努力,其通常集中在计算的再现性上,即在相同的测试数据上运行发布的代码。相比之下,像我们这样的泛化实验,通过评估分类器在真实新数据(类似于招募新参与者进行医学或心理学的再现性实验)上的性能表现来关注统计再现性。
-
机器学习
+关注
关注
66文章
8425浏览量
132774 -
深度学习
+关注
关注
73文章
5507浏览量
121298
原文标题:伯克利与MIT最新研究:「CIFAR-10分类器」能否泛化到CIFAR-10中?
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是机器学习? 机器学习基础入门

携程信息安全部在web攻击识别方面的机器学习实践之路
介绍Facebook在机器学习方面的软硬件基础架构,来满足其全球规模的运算需求
袁进辉:分享了深度学习框架方面的技术进展
我们对目前机器学习进展的衡量有多可靠?
如果要从事机器学习方面的研发,可以按照以下几个步骤学习
工业机器人目前面临哪些技术方面的问题
机器学习框架里不同层面的隐私保护
2020 年十大机器学习研究进展汇总
2020年十大机器学习研究进展






 工商网监
工商网监
评论