 特斯拉Autopilot计算机视觉及神经网络最新研究进展
特斯拉Autopilot计算机视觉及神经网络最新研究进展
在上个月的 Train AI 会议上,特斯拉 AI 及计算机视觉部门总监 Andrej Karpathy 谈了自己对当前 Autopilot 发展的见解,Karpathy 表示他目前正利用特斯拉无人车队的大量数据,试图通过训练特斯拉的神经网络模型,来改善 Autopilot 的自动驾驶能力。
首先,他简要介绍了计算机视觉软件的发展历史,以及他称之为 “software2.0” 的过渡时代。所谓的 “software2.0” 时代,是指机器学习能够代替工程师,设计并创建应用程序。
进一步,他解释了它是如何应用于特斯拉日常的开发工作,特别是在无人驾驶方面的应用。
工程师通常把特斯拉的研发车称为“机器人”。因此,Karpathy 表示特斯拉拥有全球规模最大的机器人集群,部署了超过 25 万辆车。而现在他要做的是,训练这些机器人并让它们学会自己开车。
Karpathy 提到加入特斯拉 11 个月以来,他在特斯拉的 Autopilot 部门中推出了更多版本的“软件 2.0”,他用这些图像说明了这一点:

这是在今年3月份推出的 Autopilot 软件更新中推出的,他所指的很可能是重写了特斯拉使用的神经网络模型,从而显著地改善了 Autopilot 的性能。
而现在神经网络模型正在慢慢接收特斯拉 Autopilot 的代码,Karpathy 强调该团队正在致力于数据标签和创建基础数据集架构的研究。
Karpathy 还谈到,自从加入特斯拉以来,他每天睡眠的时间大大缩短,这其中的原因主要是日常工作由实际建模和算法研究转向了处理大量数据库而导致的:
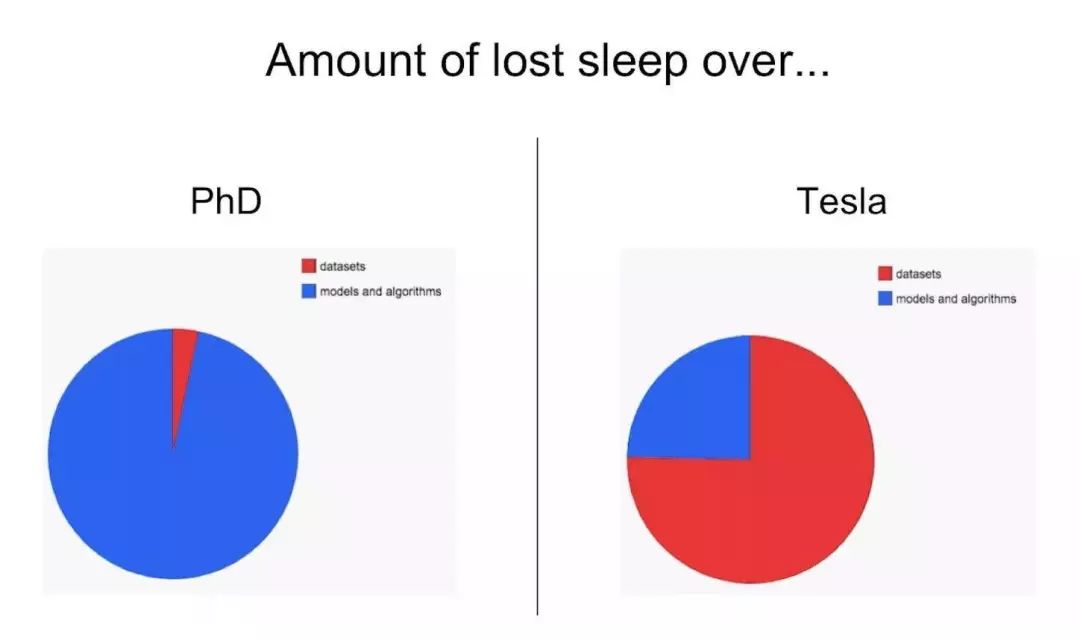
他举了个例子,描述了由于不同地区车道种类的多样性,标记这些不同类型车道线的工作也将变得相当复杂。
他提到的另一个例子是关于交通信号灯的数据集,他说这个数据集真的“非常疯狂”,如下图所示:
Karpathy 解释到构建数据集需要大量的 “时间和精力”,这是非常 “痛苦的” 的一项工作。这就是为什么他们正试图在特斯拉建立新工具上创建 “ 软件 2.0 ”,从而帮助他们完成数据库构建的工作。
-
特斯拉
+关注
关注
66文章
6313浏览量
126566 -
计算机视觉
+关注
关注
8文章
1698浏览量
45993
原文标题:Andrej Karpathy:特斯拉Autopilot计算机视觉及神经网络最新研究进展
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉技术的AI算法模型
全卷积神经网络的工作原理和应用
神经网络三要素包括什么
基于神经网络的全息图生成算法
卷积神经网络在视频处理中的应用
计算机视觉与人工智能的关系是什么
循环神经网络的应用场景有哪些
用于自然语言处理的神经网络有哪些
卷积神经网络分类方法有哪些
卷积神经网络的基本概念和工作原理
深度神经网络模型有哪些
计算机视觉的主要研究方向
利用卷积神经网络实现SAR目标分类的研究






 工商网监
工商网监
评论