 Linux内存配置:overcommit的设置
Linux内存配置:overcommit的设置
一、前言
终于可以进入Linux kernel内存管理的世界了,但是从哪里入手是一个问题,当面对一个复杂系统的时候,有时候不知道怎么开始。遵守“一切以人为本”的原则,我最终选择先从从userspace的视角来看内核的内存管理。最开始的系列文章选择了vm运行参数这个主题。执行ls /proc/sys/vm的命令,你可以看到所有的vm运行参数,本文选择了overcommit相关参数来介绍。
本文的代码来自4.0内核。
二、背景知识
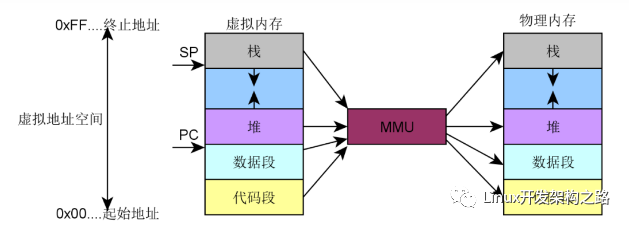
要了解这类参数首先要理解什么是committed virtual memory?使用版本管理工具的工程师都熟悉commit的含义,就是向代码仓库提交自己更新的意思,对于这个场景,实际上就是各个进程提交自己的虚拟地址空间的请求。虽然我们总是宣称每个进程都有自己独立的地址空间,但素,这些地址空间都是虚拟地址,就像是镜中花,水中月。当进程需要内存时(例如通过brk分配内存),进程从内核获得的仅仅是一段虚拟地址的使用权,而不是实际的物理地址,进程并没有获得物理内存。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,产生“缺页”异常,从而进入分配实际物理地址的过程,也就是分配实际的page frame并建立page table。之后系统返回产生异常的地址,重新执行内存访问,一切好象没有发生过。因此,看起来虚拟内存和物理内存的分配被分割开了,这是否意味着进程可以任意的申请虚拟地址空间呢?也不行,毕竟virtual memory需要physical memory做为支撑,如果分配了太多的virtual memory,和物理内存不成比例,对性能会有影响。对于这个状况,我们称之为overcommit。
三、参数介绍
1、overcommit_memory。overcommit_memory这个参数就是用来控制内核对overcommit的策略。该参数可以设定的值包括:
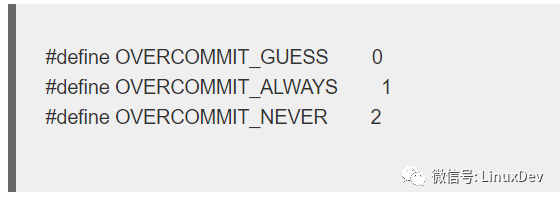
OVERCOMMIT_ALWAYS表示内核并不限制overcommit,无论进程们commit了多少的地址空间的申请,go ahead,do what you like,只不过后果需要您自己的负责。OVERCOMMIT_NEVER是另外的极端,永远不要overcommit。OVERCOMMIT_GUESS的策略和其名字一样,就是“你猜”,多么调皮的设定啊(后面代码分析会进一步描述)。BTW,我不太喜欢这个参数的命名,更准确的命名应该类似vm_overcommit_policy什么的,大概是历史的原因,linux kernel一直都是保持了这个符号。
2、overcommit_kbytes和overcommit_ratio
OVERCOMMIT_ALWAYS可以很任性,总是允许出现overcommit现象,但是OVERCOMMIT_NEVER不行,这种策略下,系统不允许出现overcommit。不过要检查overcommit,具体如何判断呢,总得有个标准吧,这个标准可以从vm_commit_limit这个函数看出端倪:

overcommit的标准有两个途径来设定,一种是直接定义overcommit_kbytes,这时候标准值是overcommit_kbytes+total_swap_pages。什么是total_swap_pages呢?这里要稍微讲一下关于页面回收(page frame reclaim)机制。
就虚拟内存和物理内存的分配策略而言,inux kernel对虚拟地址空间的分配是比较宽松的(虽然有overcommit机制),但是,kernel对用户空间的物理内存申请(创建用户空间进程、用户空间程序的malloc(就是堆的分配),用户空间进程stack的分配等)是非常的吝啬的(顺便提及的是:内存管理模块对来自内核的内存申请是大方的,内核工程师的自豪感是否油然而生,呵呵~~),总是百般阻挠,直到最后一刻实在没有办法了才分配物理内存。这种机制其背后的思想是更好的使用内存,也就是说:在限定的物理内存资源下,可以尽量让更多的用户空间进程运行起来。如果让物理地址和虚拟地址空间是一一映射的时候,那么系统中的可以启动进程数目必定是受限的,进程可以申请的内存数目也是受限的,你的程序不得不经常面内存分配失败的issue。如果你想破解这个难题,就需要将一个较小的物理内存空间映射到一个较大的各个用户进程组成的虚拟地址空间之上。怎么办,最简单的方法就是“拆东墙补西墙”。感谢程序天生具备局部性原理,可以让内核有东墙可以拆,但是,拆东墙(swap out)也是技术活,不是所有的进程虚拟空间都可以拆。比如说程序的正文段的内容就是可以拆,因为这些内存中的内容有磁盘上的程序做支撑,当再次需要的时候(补西墙),可以从磁盘上的程序文件中reload。不是所有的进程地址空间都是有file-backup的,堆、stack这些进程的虚拟地址段都是没有磁盘文件与之对应的,也就是传说中的anonymous page。对于anonymous page,如果我们建立swap file或者swap device,那么这些anonymous page也同样可以被交换到磁盘,并且在需要的时候load进内存。
OK,我们回到total_swap_pages这个变量,它其实就是系统可以将anonymous page交换到磁盘的大小,如果我们建立32MB的swap file或者swap device,那么total_swap_pages就是(32M/page size)。
overcommit的标准的另外一个标准(在overcommit_kbytes设定为0的时候使用)是和系统可以使用的page frame相关。并不是系统中的物理内存有多少,totalram_pages就有多少,实际上很多的page是不能使用的,例如linux kernel本身的正文段,数据段等就不能计入totalram_pages,还有一些系统reserve的page也不算数,最终totalram_pages实际上就是系统可以管理分配的总内存数目。overcommit_ratio是一个百分比的数字,50表示可以使用50%的totalram_pages,当然还有考虑total_swap_pages的数目,上文已经描述。
还有一个小细节就是和huge page相关的,传统的4K的page和huge page的选择也是一个平衡问题。normal page可以灵活的管理内存段,浪费少。但是不适合大段虚拟内存段的管理(因为要建立大量的页表,TLB side有限,因此会导致TLB miss,影响性能),huge page和normal page相反。内核可以同时支持这两种机制,不过是分开管理的。我们本节描述的参数都是和normal page相关的,因此在计算allowed page的时候要减去hugetlb_total_pages。
3、admin_reserve_kbytes和user_reserve_kbytes
做任何事情都要留有余地,不要把自己逼到绝境。这两个参数就是防止内存管理模块把自己逼到绝境。
上面我们提到拆东墙补西墙的机制,但是这种机制在某些情况下其实也不能正常的运作。例如进程A在访问自己的内存的时候,出现page fault,通过scan,将其他进程(B、C、D…)的“东墙”拆掉,分配给进程A,以便让A可以正常运行。需要注意的是,“拆东墙”不是那么简单的事情,有可能需要进行磁盘I/O操作(比如:将dirty的page cache flush到磁盘)。但是,系统很快调度到了B进程,而B进程立刻需要刚刚拆除的东墙,怎么办?B进程立刻需要分配物理内存,如果没有free memory,这时候也只能启动scan过程,继续找新的东墙。在极端的情况下,很有可能把刚刚补好的西墙拆除,这时候,整个系统的性能就会显著的下降,有的时候,用户点击一个button,很可能半天才能响应。
面对这样的情况,用户当然想恢复,例如kill那个吞噬大量内存的进程。这个操作也需要内存(需要fork进程),因此,为了能够让用户顺利逃脱绝境,系统会保留user_reserve_kbytes的内存。
对于支持多用户的GNU/linux系统而言,恢复系统可能需要root用来来完成,这时候需要保留一定的内存来支持root用户的登录操作,支持root进行trouble shooting(使用ps,top等命令),找到那个闹事的进程并kill掉它。这些为root用户操作而保留的memory定义在admin_reserve_kbytes参数中。
四、代码分析
用户空间进程在使用内存的时候(更准确的说是分配虚拟内存,其实用户空间根本无法触及物理内存的分配,那是内核的领域),内核都会调用__vm_enough_memory函数来验证是否可以允许分配这段虚拟内存,代码如下:
int __vm_enough_memory(struct mm_struct *mm, long pages, int cap_sys_admin) { …… if (sysctl_overcommit_memory == OVERCOMMIT_ALWAYS) ----(1) return 0;
if (sysctl_overcommit_memory == OVERCOMMIT_GUESS) { free = global_page_state(NR_FREE_PAGES); free += global_page_state(NR_FILE_PAGES); free -= global_page_state(NR_SHMEM);
free += get_nr_swap_pages(); free += global_page_state(NR_SLAB_RECLAIMABLE); ------(2)
if (free <= totalreserve_pages) ------------------(3) goto error; else free -= totalreserve_pages;
if (!cap_sys_admin) ----------------------(4) free -= sysctl_admin_reserve_kbytes >> (PAGE_SHIFT - 10);
if (free > pages) ------------------------(5) return 0;
goto error; }
allowed = vm_commit_limit(); -------------------(6) if (!cap_sys_admin) allowed -= sysctl_admin_reserve_kbytes >> (PAGE_SHIFT - 10); --参考(4)的解释
if (mm) { ----------------------------(7) reserve = sysctl_user_reserve_kbytes >> (PAGE_SHIFT - 10); allowed -= min_t(long, mm->total_vm / 32, reserve); }
if (percpu_counter_read_positive(&vm_committed_as) < allowed) ----(8) return 0;
……}
(1)OVERCOMMIT_ALWAYS奏是辣么自由,随你overcommit,只要你喜欢。return 0表示目前有充足的virtual memory资源。
(2)OVERCOMMIT_GUESS其实就是让内核自己根据当前的状况进行判断,因此首先进入收集信息阶段,看看系统有多少free page frame(NR_FREE_PAGES标记,位于Buddy system的free list中),这些是优质资源,没有任何的开销就可以使用。NR_FILE_PAGES是page cache使用的page frame,主要是用户空间进程读写文件造成的。这些cache都是为了加快系统性能而增加的,因此,如果直接操作到磁盘,本质上这些page cache都是free的。不过,这里有一个特例就是NR_SHMEM,它主要是用于进程间的share memory机制,这些shmem page frame不能认为是free的,因此要减去。get_nr_swap_pages函数返回swap file或者swap device上空闲的“page frame”数目。本质上,swap file或者swap device上的磁盘空间都是给anonymous page做腾挪之用,其实这里的“page frame”不是真的page frame,我们称之swap page好了。get_nr_swap_pages函数返回了free swap page的数目。这里把free swap page的数目也计入free主要是因为可以把使用中的page frame swap out到free swap page上,因此也算是free page,虽然开销大了一点。至于NR_SLAB_RECLAIMABLE,那就更应该计入free page了,因为slab对象都已经标注自己的reclaim的了,当然是free page了。
(3)要解释totalreserve_pages需要太长的篇幅,我们这里略过,但这是一个能让系统运行需要预留的page frame的数目,因此我们要从减去totalreserve_pages。如果当前free page数目小于totalreserve_pages,那么当然拒绝vm的申请。
(4)如果是普通的进程,那么还需要保留admin_reserve_kbytes的free page,以便在出问题的时候可以让root用户可以登录并进行恢复操作。
(5)最关键的来了,比对本次申请virtual memory的page数目和当前“free”(之所以加引号表示并真正free page frame数目)的数据,如果在保留了足够的page frame之后,还有足够的page可以满足本次分配,那么就批准本次vm的分配。
(6)从这里开始,进入OVERCOMMIT_NEVER的处理。从vm_commit_limit函数中可以获取一个基本的判断overcommit的标准,当然要根据具体情况进行调整,例如说admin_reserve_kbytes。
(7)如果是用户空间的进程,我们还要为用户能够从绝境中恢复而保留一些page frame,具体保留多少需要考量两个因素,一个是单一进程的total virtual memory,一个用户设定的运行时参数user_reserve_kbytes。更具体的考量因素可以参考https://lkml.org/lkml/2013/3/18/812,这里就不赘述了。
(8)allowed变量保存了判断overcommit的上限,vm_committed_as保存了当前系统中已经申请(包括本次)的virtual memory的数目。如果大于这个上限就判断overcommit,本次申请virtual memory失败。
五、参考文献
1、Documentation/vm/overcommit-accounting
2、Documentation/sysctl/vm.txt
-
Linux
+关注
关注
87文章
11316浏览量
209814 -
内存
+关注
关注
8文章
3034浏览量
74132
原文标题:郭健:Linux内存管理系统参数配置之overcommit
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Linux的内存管理是什么,Linux的内存管理详解
走进Linux内存系统探寻内存管理的机制和奥秘
MCUXpresso如何根据“构建配置”设置不同的内存配置?
如何设置电脑的虚拟内存
深入剖析Linux共享内存原理





 工商网监
工商网监
评论