 BP神经网络概述
BP神经网络概述
1 BP神经网络概述
BP 神经网络是一类基于误差逆向传播 (BackPropagation, 简称 BP) 算法的多层前馈神经网络,BP算法是迄今最成功的神经网络学习算法。现实任务中使用神经网络时,大多是在使用 BP 算法进行训练。值得指出的是,BP算法不仅可用于多层前馈神经网络,还可以用于其他类型的神经网络,例如训练递归神经网络。但我们通常说 “BP 网络” 时,一般是指用 BP 算法训练的多层前馈神经网络。
2 神经网络的前馈过程

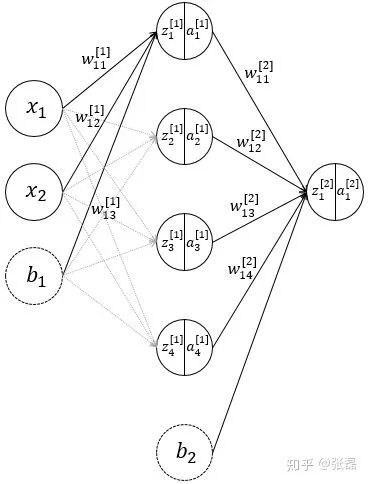
神经网络结构示意图
上述过程,即为该神经网络的前馈 (forward propagation) 过程,前馈过程也非常容易理解,符合人正常的逻辑,具体的矩阵计算表达如
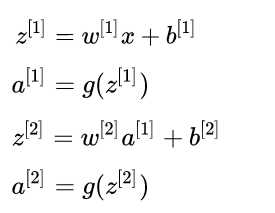
3 逆向误差传播 (BP过程)

我们的任务就是:给定了一组数据集,其中包含了输入数据和输出的真实结果,如何寻找一组最佳的神经网络参数,使得网络计算得到的推测值能够与真实值吻合程度最高?
3.1 模型的损失函数
为了达到这个目标,这也就转换为了一个优化过程,对于任何优化问题,总是会有一个目标函数 (objective function),在机器学习的问题中,通常我们称此类函数为:损失函数 (loss function),具体来说,损失函数表达了推测值与真实值之间的误差。抽象来看,如果把模型的推测以函数形式表达为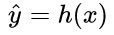 (这里的函数字母使用 h 是源于“假设 hypothesis“ 这一单词),对于有m个训练样本的输入数据而言,其损失函数则可表达为:
(这里的函数字母使用 h 是源于“假设 hypothesis“ 这一单词),对于有m个训练样本的输入数据而言,其损失函数则可表达为:
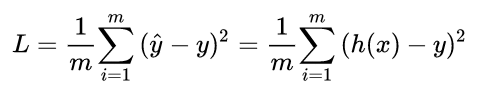
那么在该问题中的损失函数是什么样的呢?抛开线性组合函数,我们先着眼于最终的激活函数,也就是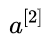 的值,由于 sigmoid 函数具有很好的函数性质,其值域介于 0 到 1 之间,当自变量很大时,趋向于 1,很小时趋向于 0,因此,该模型的损失函数可以定义如下:
的值,由于 sigmoid 函数具有很好的函数性质,其值域介于 0 到 1 之间,当自变量很大时,趋向于 1,很小时趋向于 0,因此,该模型的损失函数可以定义如下:
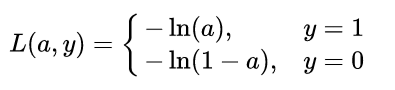
不难发现,由于是分类问题,真实值只有取 0 或 1 两种情况,当真实值为 1 时,输出值a越接近 1,则 loss 越小;当真实值为 0 时,输出值越接近于 0,则 损失函数越小 (可自己手画一下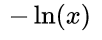 函数的曲线)。因此,可将该分段函数整合为如下函数:
函数的曲线)。因此,可将该分段函数整合为如下函数:
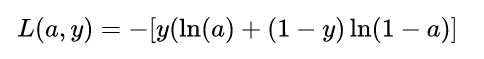
该函数与上述分段函数等价。如果你了解Logistic Regression 模型的基本原理,那么损失函数这一部分与其完全是一致的,现在,我们已经确定了模型的损失函数关于输出量a的函数形式,接下来的问题自然就是:如何根据该损失函数来优化模型的参数。
3.2 基于梯度下降的逆向传播过程 (关于损失函数的逆向求导)
这里需要一些先修知识,主要是需要懂得梯度下降 (gradient descent)这一优化算法的原理,这里我就不展开阐述该方法,不了解的读者可以查看我之前的这篇较为简单清晰的关于梯度下降法介绍的文章 ->[link]。由于如果将神经网络的损失函数完全展开将会极为繁琐,这里我们先根据上面得到的关于输出量a的损失函数来进行一步步的推导。
BP 的核心点在于逆向传播,本质上来说,其实是将模型最终的损失函数进行逆向求导的过程,首先,我们需要从输出层向隐含层的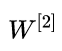 进行求导,也就是需要求得
进行求导,也就是需要求得 ,这里就需要用到求导方法里的 链式求导法则。我们先求得 2 个必要的导数
,这里就需要用到求导方法里的 链式求导法则。我们先求得 2 个必要的导数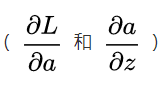 :
:



-
神经网络
+关注
关注
42文章
4779浏览量
101113 -
机器学习
+关注
关注
66文章
8438浏览量
133006 -
BP算法
+关注
关注
0文章
8浏览量
7192
原文标题:BP 神经网络 —— 逆向传播的艺术
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论