 极低功耗的两款全新的神经网络内核AX2185和AX2145
极低功耗的两款全新的神经网络内核AX2185和AX2145
Imagination公司日前基于其神经网络加速器(NNA)架构PowerVR 2NX推出了两款全新的神经网络内核AX2185和AX2145,其设计目的是在极小芯片面积上以极低功耗实现神经网络高性能计算。
不同于CPU/GPU架构,PowerVR 2NX架构是Imagination专为神经网络算法所设计的可扩展架构,支持16位到4位位宽。由于灵活的位宽可基于每一层去支持权重和数据,这意味着PowerVR Series2NX可以保持高推理精度,同时降低带宽/功耗要求,能够为移动和嵌入式平台中的高效神经网络推理提供硬件加速。
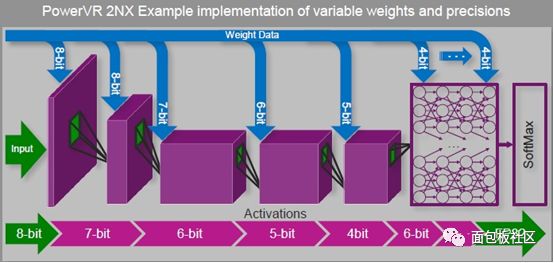
PowerVR 2NX NNA可调精度和低精度实例
神经网络加速器将成SoC标准IP模块
根据Gartner的预估,到2020年深度神经网络(DNN)和机器学习应用将为半导体企业创造100亿美元的市场商机,人工智能与机器学习将逐渐渗透所有事物,成为未来5年科技厂商的主要战场。
“人工智能处理一直以来主要发生在云端,但由于延迟、隐私问题以及日益增长的可扩展性需求,边缘人工智能处理已变得非常必要。”Imagination主管PowerVR视觉和人工智能业务的副总裁Russell James说,要将人工智能引入边缘计算中,首当其冲面临的挑战,就是学会如何在电池寿命的限制下保证电力,管理安全性并提供合理的成本。其次,在终端侧进行AI处理,实时响应、安全性和可靠性也是必须考虑的。
Imagination中国区区域市场和业务拓展总监柯川将AI产业分为四个阶段:一是新技术来临时有前沿院校和公司研究论证,找到产业化可能性;二是应用研究阶段,探讨解决实际问题;三是产业快速发展阶段;四是进入成熟期,成为一个相对稳定的市场。目前来看,AI正处于第三阶段的早期。
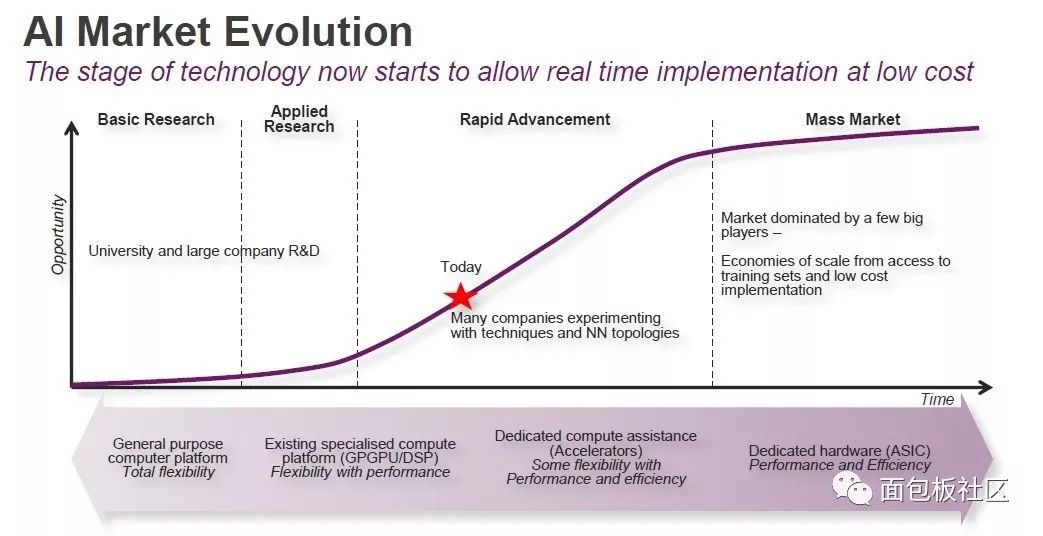
AI市场演进
Imagination方面认为NNA的用途非常多,所以是绝对不容忽视的。例如根据正在观看的人和他们的年龄调整电视频道的顺序和访问权限;识别混合现实场景中的物体,以确保在现实世界中没有任何重要的东西被忽视(如楼梯或火灾);实时增强电视、手机或视频通话中的图像;实现自主系统,如自动驾驶车辆等。
在此前的采访中,Imagination市场传播副总裁David Harold就曾表示,未来NNA一定会成为SoC中的标准IP模块,就像CPU、GPU和视频编解码器一样,因为“PowerVR 2NX NNA的逻辑比我们最小的GPU还小,但是却大大节省了功耗和带宽,提高了可用性。”根据柯川提供的数据,与最接近的竞争方案相比,PowerVR 2NX可以用25%的带宽提供两倍的性能。在位宽调整后,如将8位调整到4位,性能提升了60%,带宽降至54%,功耗降至69%,但精度下降不到1%。
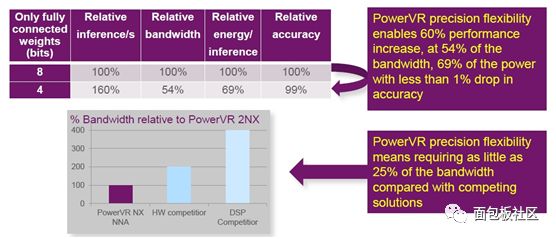
灵活的多精度支持优势
两个新成员
AX2185拥有8个全宽度计算引擎,每个时钟周期可处理2048个MAC(每秒4.1兆次运算),以高端智能手机、智能监控和汽车市场中的图像分类和驾驶辅助系统等应用为目标,据称能够代表市场上单位面积(每平方毫米)的最高性能。
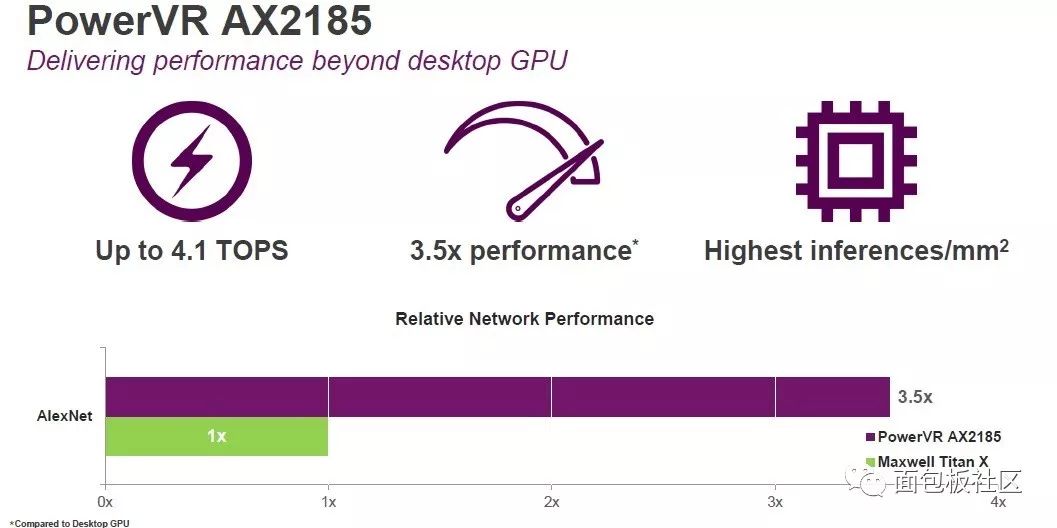
AX2145针对成本敏感型设备进行了优化,以中档智能手机、数字电视/机顶盒、智能相机和消费性安全市场中的图像管理与基于视觉的应用为目标。其精简型架构能够为超低带宽系统提供高性能的神经网络推理功能,从而支持原始设备制造商(OEM)和原始设计制造商(ODM)在芯片面积预算有限的情况下开展工作。
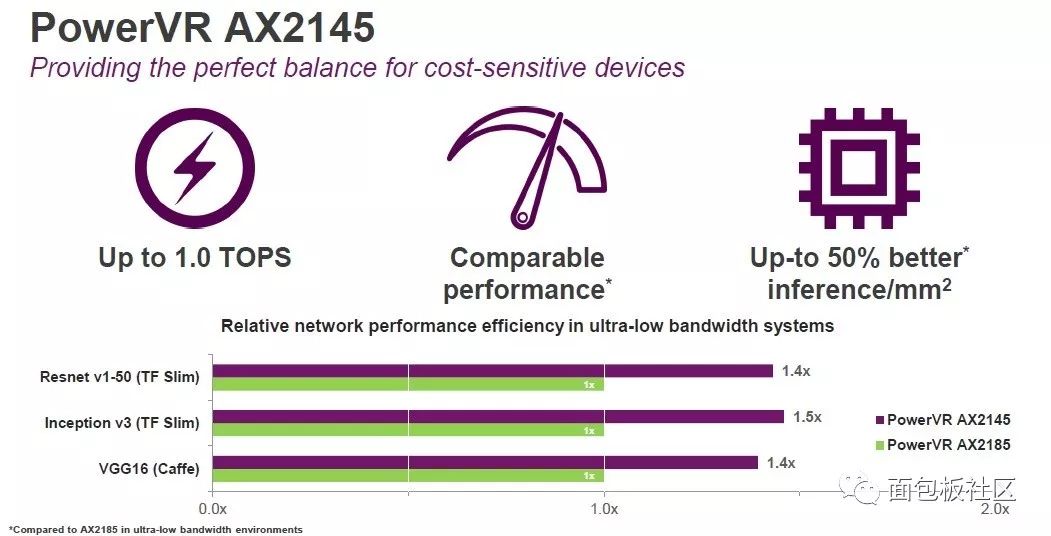
当然,只有NNA是不够的,还需要提供工具和软件。两款内核都完全支持安卓(Android)的神经网络应用程序编程接口(Neural Networks API, NNAPI),开发人员使用NNAPI可以将神经网络功能带入基于Android的移动设备。为配合PowerVR Series2NX内核,Imagination还提供了一整套工具来简化人工智能应用的开发、部署、调试和分析。
在Russell James看来,目前市场中三种主流的AI芯片架构(CPU/DSP/FPGA等通用型处理器、CPU/GPU+AI加速器、以及定制化ASIC)设计思路不同,各有优缺点,面对的应用也五花八门,在选择时需加以谨慎。具体而言,第一类适合性能要求和精度要求不太高的应用,如人脸识别;第二类适合高性能应用,如智能手机、智能监控、自动驾驶等;第三类AISC芯片适合某些特定场景。例如在IoT领域中,很多应用要求在有限的功耗下完成相应的AI任务,且芯片出货量大,此时性能功耗比高的ASIC就很值得关注。
-
神经网络
+关注
关注
42文章
4771浏览量
100744 -
低功耗
+关注
关注
10文章
2399浏览量
103685
原文标题:王者归来,这颗中国芯霸气宣布带来顶尖AI创新
文章出处:【微信号:gh_bee81f890fc1,微信公众号:面包板社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
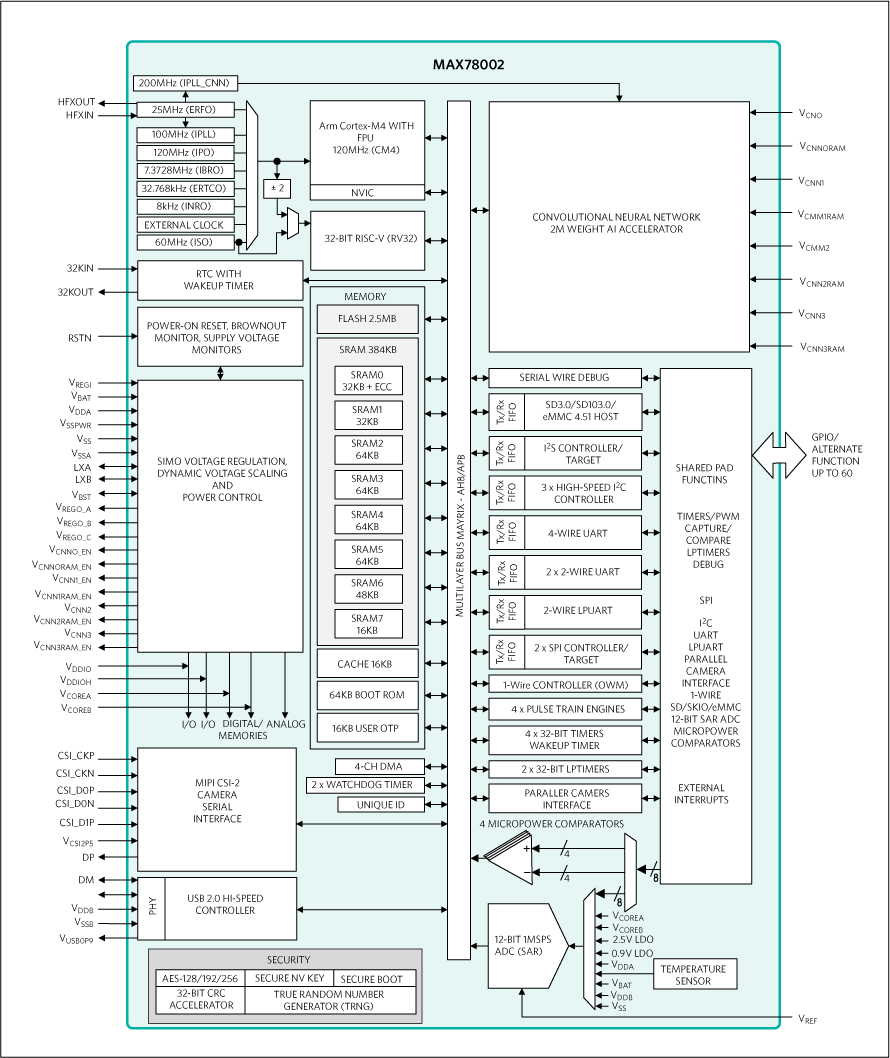
芯品#MAX78002 新型AI MCU,能够使神经网络以超低功耗运行
TP-Link推出两款入门级用户路由器——Archer AX3000和AX1500
采用AX88796C实现低功耗以太网接口模块设计
【案例分享】ART神经网络与SOM神经网络
CMSIS-NN神经网络内核助力微控制器效率提升
如何构建神经网络?
基于BP神经网络的PID控制
神经网络移植到STM32的方法
亚信电子推出低功耗SPI或Non-PCI以太网控制器AX88
Imagination首发了两款神经网络内核AX2185和AX2145
基于Imagination革命性的NNA架构PowerVRSeries2NX设计的神经网络内核详解





 工商网监
工商网监
评论