 一种用深度学习框架对普通视频进行流畅稳定的慢动作回放的技术
一种用深度学习框架对普通视频进行流畅稳定的慢动作回放的技术
编者按:生活中总有许多特殊时刻值得被记录,而慢动作回放能让你看得更清晰,比如宝宝第一次蹒跚学步、第一次完成了酷炫的滑板技巧等。但是这些时刻无法预料,大多都是用手机或普通相机拍摄的视频,其中的帧率对慢回放并不友好。在这篇论文中,英伟达AI团队提出了一种用深度学习框架对普通视频进行流畅稳定的慢动作回放的技术。以下是论智的编译。
大多数高端单反相机和智能手机都能拍摄慢动作,但是这项技术并未普及,因为这一过程需要大量数据。例如,索尼Xperia XZ2手机的Super Slow Motion模式可以每秒拍摄960帧的视频,是默认的30fps捕捉数据的32倍。这不仅需要大量内存,还要有高性能处理器对每一帧画面进行处理。
最近,英伟达推出了一种新算法,可以将原视频进行慢放处理。该论文将在本周的CVPR 2018上进行展示。与传统的使用时间拉伸帧来填补镜头间隙的慢动作技术不同,英伟达团队用的是机器学习来进行慢动作处理,看起来像是出现了新的帧。
来自英伟达、马萨诸塞大学阿默斯特分校和加利福尼亚大学默塞德分校的科学家们提出了一种无监督的端到端神经网络,它可以生成任意数量的中间帧,从而输出非常流畅的慢动作镜头。这项技术被称为“可变长度多帧插值(variable-length multi-frame interpolation)”。论智将论文大致编译如下。

视频插值问题向来富有挑战性,因为它需要生成多个视频中间帧,保证在空间和时间上的连贯性。例如,从标准的序列(30fps)中生成240fps的视频,就需要在每两个帧之间插入七个中间帧。为了生成高质量的插入结果,不仅仅需要正确理解两张输入图像之间的动作,还要掌握图像之间的遮挡,否则就会造成失真效果。
目前技术的主要关注点都在单帧视频插值上,但是这些方法不能直接用于生成任意高帧率的视频。在这篇论文中,科学家们提出了一种高质量的“可变长度多帧插值”方法,它可以在任意时间在两帧之间插入中间帧。这种方法的主要原理是将两个输入图片扭曲到同一时间点,然后进行适应调整后将两张图像结合生成一个中间图像,其中的运动轨迹和遮挡推理都在单一的端到端网络中进行建模。
Super SloMo
首先用其中一个光流计算卷积神经网络估算两张输入图片之间的光流(场景中目标物体、表面和边缘运动的轨迹),在两个输入帧之间的时间线上同时计算向前和向后的光流。
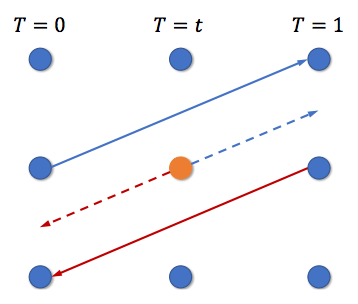
中间光流估算的过程。橙色的像素参考的是第一和第二张图片的相同位置的像素光流
之后,CNN会预测像素的移动轨迹,为每一帧生成一个2D的预测轨迹作为光流场(flow field),之后它会融合在一起,为中间帧计算大概的光流场。这一估计过程在平滑的区域表现得很好,但是遇到边界线时性能有所下降。
于是,研究人员们用另一个光流插值CNN调整之前计算出的光流场,并将预测路线进行可视化。通过将可视化线路应用到两图像上,研究人员可以删除被视频中物体遮挡住的像素,并且还可以减少轨迹上以及周围的“人工痕迹”。
可视化线路的预测
最后,中间光流场对两图片进行扭曲,以让帧的过度更加平滑流畅。由于这两个CNN的参数在每个被插入的时间点是不同的,这一方法可以同时生成任意多的中间帧。整个网络过程如下图所示:
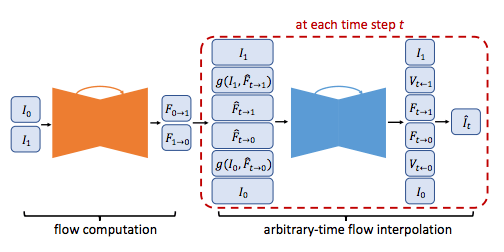
对于光流计算和光流插值CNN,研究人员使用的是U-Net结构。U-Net是完全卷积神经网络,它包含一个编码器和一个解码器。
训练
接着,研究人员从YouTube和摄像机中选取了一些240fps的视频,其中包括The Slow Mo Guys(一个总共有11000个视频的资料库)的剪辑片段,最终得到了1132段视频片段和37.6万个独立的视频帧数。在设备方面,他们用的是英伟达Tesla V100 GPU和经过cuDNN加速的PyTorch深度学习框架进行训练。
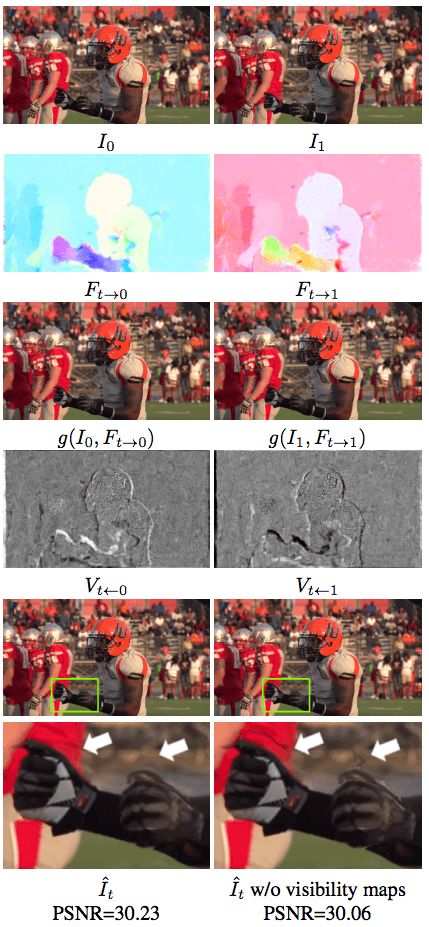
最后的结果对比非常明显,在下面这个从UCF101中截取的视频片段中可以看到本文提出的方法和当前其他方法的对比:
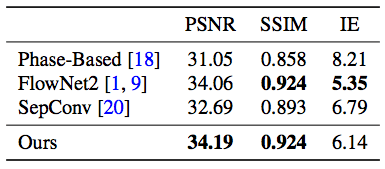
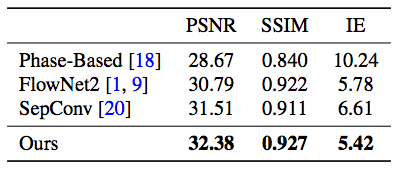
可以看到,英伟达的方法在眉毛和眉刷周围都没有什么失真的画面,非常清晰。
结语
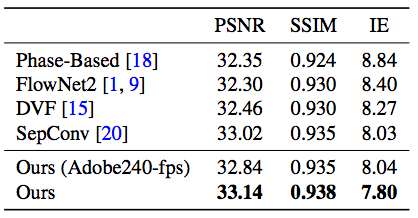
研究人员认为,他们的方法在所有数据集上都达到了顶尖效果,生成了单一或多个中间帧。并且这一模型不用更改设置就能直接应用到不同场景上,这一点是很了不起的。
但是据英伟达方面的消息,这一技术目前仍需要优化改进,投入到现实中仍需要解决很多问题。研究人员表示,他们希望未来如果在消费者设备和软件商使用时,大部分处理过程能在云端完成。
-
神经网络
+关注
关注
42文章
4762浏览量
100517 -
视频
+关注
关注
6文章
1932浏览量
72805 -
深度学习
+关注
关注
73文章
5491浏览量
120958
原文标题:CVPR 2018:英伟达用深度学习实现任意视频的完美慢镜头回放
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Nanopi深度学习之路(1)深度学习框架分析
一种基于图像平移的目标检测框架
什么是深度学习?使用FPGA进行深度学习的好处?
基于视频深度学习的时空双流人物动作识别模型
一种用于交通流预测的深度学习框架






 工商网监
工商网监
评论