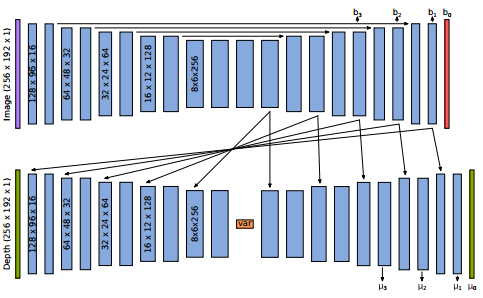
 采用的网络架构,实现了基于图像强度的变分深度自编码器
采用的网络架构,实现了基于图像强度的变分深度自编码器
相信各位小伙伴一定已经学习了今年CVPR的两篇最佳论文了,一篇是来自于斯坦福和伯克利大学的研究人员共同进行的关于如何进行高效迁移学习的:Taskonomy: Disentangling Task Transfer Learning,另一篇来自卡耐基梅隆大学的论文:Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies实现了多尺度人类行为的三维重建和追踪。但除此之外,还有四篇优秀的工作被授予了最佳论文的荣誉提名奖,分别是来自:
帝国理工戴森机器人实验室的:CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM;
加州大学默塞德分校、麻省大学阿默斯特分校和英伟达的:SPLATNet: Sparse Lattice Networks for Point Cloud Processing;
隆德大学、罗马尼亚科学院的:Deep Learning of Graph Matching;
奥地利科技学院、马克思普朗克图宾根研究所、海德巴拉国际信息技术研究所和剑桥大学共同研究的:Efficient Optimization for Rank-based Loss Functions四篇论文分别从几何描述、点云处理、图匹配和优化等方面进行了研究,下面让我们一起学习一下吧!
CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM
在实时三维感知系统中,物体几何的表述一直是一个十分关键的问题,特别是在定位和映射算法中有着重要的作用,它不仅影响着映射的几何质量,更与其采取的算法息息相关。在SLAM特别是单目SLAM中场景几何信息不能从单一的视角得到,而与生俱来的不确定性在大自由度下会变得难以控制。这使得目前主流的slam分成了稀疏和稠密两个方向。虽然稠密地图可以捕捉几何的表面形貌并用语义标签进行增强,但它的高维特性带来的庞大存储计算量限制了它的应用,同时它还不适用于精密的概率推测。稀疏的特征可以避免这些问题,但捕捉部分场景的特征仅仅对于定位问题有用。
为了解决这些问题,这篇文章里作者提出了一种紧凑但稠密的场景几何表示,它以场景的单幅强度图作为条件并由很少参数的编码来生成。研究人员在从图像学习深度和自编码器等工作的启发下设计了这一方法。这种方法适用于基于关键帧的稠密slam系统:每一个关键帧通过编码可以生成深度图,而编码可以通过位姿变量和重叠的关键帧进行优化以保持全局的连续性。训练的深度图可使得编码表示不能直接从图像预测出的局部几何特征。
这篇文章的贡献主要在两个方面:
推导出了一种通过强度图训练深度自编码器的稠密集合表示,并进行了优化;
首次实现了稠密集合与运动估计联合优化的单目系统。
下图是研究人员采用的网络架构,实现了基于图像强度的变分深度自编码器。
下图是编解码阶段不同的输出,以及编码抓取细节的能力:

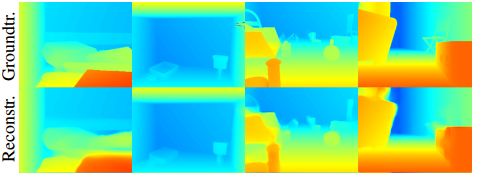
下图是编码后的恢复以及sfm结果:
研究人员们希望在未来构建出完整的基于关键帧的实时SLAM系统,并在更远的将来致力于研究一般三维几何更加紧凑的表示,甚至用于三维物体识别。
如果有兴趣,可以访问项目主页获取更详细信息,也可参看附件的视频简介:
http://www.imperial.ac.uk/dyson-robotics-lab/projects/codeslam/
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
激光雷达等三维传感器的数据经常是不规则的点云形式,分析和处理点云数据在机器人和自动驾驶中有着十分重要的作用。
但点云具有稀疏性和无序性的特征,使得一般的卷积神经网络处理3D点数据十分困难,所以目前主要利用手工特征来对点云进行处理。其中一种方法就是对点云进行预处理使其符合标准空间卷积的输入形式。按照这一思路,用于3D点云分析的深度学习架构都需要对不规则的点云进行预处理,或者进行体素表示,或者投影到2D。这需要很多的人工并且会失去点云中包含自然的不变性信息。
为了解决这些问题,在这篇文章中作者提出了一种用于处理点云的网络架构,其中的关键在于研究发现双边卷积层(e bilateral convolutionlayers——BCLs)对于处理点云有着很多优异的特性。
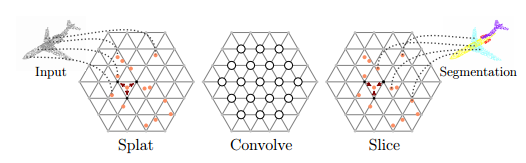
双边卷积层
BCLs提供了一种系统的方法来除了无序点,但同时保持了卷积操作中栅格的灵活性。BCL将输入点云平滑地映射到稀疏的栅格上,并在稀疏栅格上进行卷积操作,随后进行平滑插值并将信号映射到原始输入中去。利用BCLs研究人员们建立了SPLATNet(SParse LATtice Networks)用于分层处理无序点云并识别器空间特征。
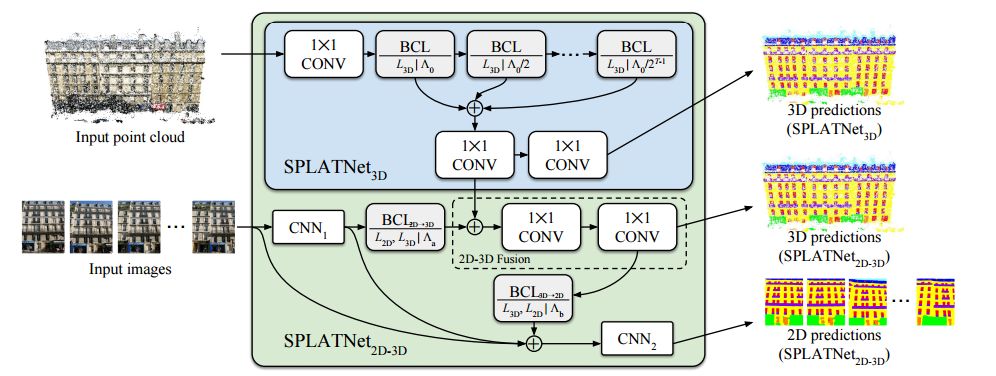
SPLATNet的架构
它具有以下优点:
无需点云预处理;
可以方便实现像标准CNN一样的邻域操作;
利用哈希表可高效处理稀疏输入;
利用稀疏高效的栅格滤波实现对输入点云分层和空间特征的处理;
可实现2D-3D之间的互相映射。
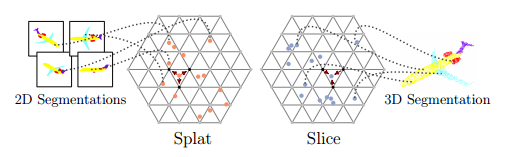
二维到三维的投影
下图是对于建筑物点云的处理结果:

如果有兴趣的小伙伴可以参考项目主页:
http://vis-www.cs.umass.edu/splatnet/
和英伟达的官方介绍:https://news.developer.nvidia.com/nvidia-splatnet-research-paper-wins-a-major-cvpr-2018-award/
如果想要上手练练,这里还有代码可以跑一波:https://github.com/NVlabs/splatnet
今天附件中包含了视频介绍,敬请观看。
https://pan.baidu.com/s/1dIyZyEx-Bc9zYPIr4F_5bw
Deep Learning of Graph Matching
图匹配问题是优化、机器学习、计算机视觉中的重要问题,而如何表示节点与其相邻结构的关系是其中的关键。这篇文章提出了一种端到端的模型来使得学习图匹配过程中的所有参数成为可能。其中包括了单位的和成对的节点邻域、表达成了深度分层的特征抽取。
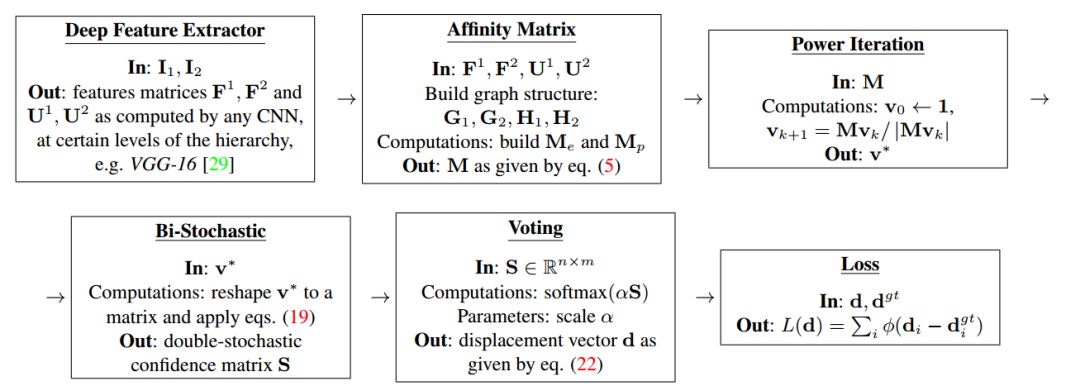
完整训练图匹配模型的计算流程
这其中的难点在于为不同层之间的矩阵运算建立从损失函数开始的完整流程、实现高效、连续的梯度传播。通过结合优化层解决了匹配问题,并利用了分层特征抽取。最后在计算机视觉的实验中取得了很好的结果。
可以看到在外形和位姿都极不同的各个实例中,关键点的图匹配算法依然表现良好。
Efficient Optimization for Rank-based Loss Functions
在信息检索系统中通常利用复杂的损失函数(AP,NDCG)来衡量系统的表现。虽然可以通过正负样本来估计检索系统的参数,但这些损失函数不可微、不可分解使得基于梯度的算法无法使用。通常情况下人们通过优化损失函数hinge-loss上边界或者使用渐进方法来规避这一问题。

系统算法
为了解决这一问题,研究人员们提出了一种用于大规模不可微损失函数算法。提供了符合这一算法的损失函数的特征描述,它可以处理包括AP和NDCC系列的损失函数。同时研究人员们还提出了一种非比照的算法改进了上述渐进过程的计算复杂度。这种方法与更简单的可分解(需要对照训练)损失函数相比有着更好的结果。
-
神经网络
+关注
关注
42文章
4772浏览量
100853 -
图像
+关注
关注
2文章
1086浏览量
40492 -
激光雷达
+关注
关注
968文章
3981浏览量
190035
原文标题:提名也是莫大的荣誉:除了最佳论文,CVPR的这些论文也不容错过
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器介绍
基于稀疏自编码器的属性网络嵌入算法SAANE
基于变分自编码器的海面舰船轨迹预测算法
自编码器基础理论与实现方法、应用综述
一种多通道自编码器深度学习的入侵检测方法


基于变分自编码器的网络表示学习方法
自编码器神经网络应用及实验综述
基于深度稀疏自编码网络的行人检测
基于交叉熵损失函欻的深度自编码器诊断模型
自编码器 AE(AutoEncoder)程序






 工商网监
工商网监
评论