 OpenAI举办的首届迁移学习竞赛Retro Contest结束
OpenAI举办的首届迁移学习竞赛Retro Contest结束
OpenAI举办的首届迁移学习竞赛Retro Contest结束,在全部229支队伍里,来自中国的团队获得了冠亚军。冠军是一个6人团队,其中有南京大学和阿里巴巴搜索事业部的研究人员;亚军是中科院的两名研究生。
这个竞赛的目标,是评估强化学习算法从以往的经验中泛化的能力。具体说,就是让AI玩视频游戏《刺猬索尼克》,这是世嘉公司开发的一款竞速式2D动作游戏,其基本上模拟马里奥的游戏方式,玩家在尽可能短的时间内到达目的地,索尼克可以通过不停加速来快速完成关卡。最后可能需要对抗BOSS。
冠军方案展示:由南大和阿里研究人员组成的Dharmaraja队的agent,学习穿越游戏中海洋废墟区域(Aquatic Ruin Zone)。Agent已经在游戏的其他关进行过预训练,但这是第一次遇到这一关。
OpenAI的这个竞赛Retro Contest从2018年4月5日发布,持续时间为2个月。开始有923支队伍报名,但最终只有229个提交了解决方案。OpenAI的自动评估系统对这些结果进行了评估。为了避免参赛者拟合数据集,评审时使用了完全不同的数据集。此外,OpenAI还将前十名的最终提交结果进行了再测试,让这些agents在11个由游戏设计师特别设计的关卡中,分别进行了3次测试,每次都从环境中随机生成初始状态。最终得到的排名如下:
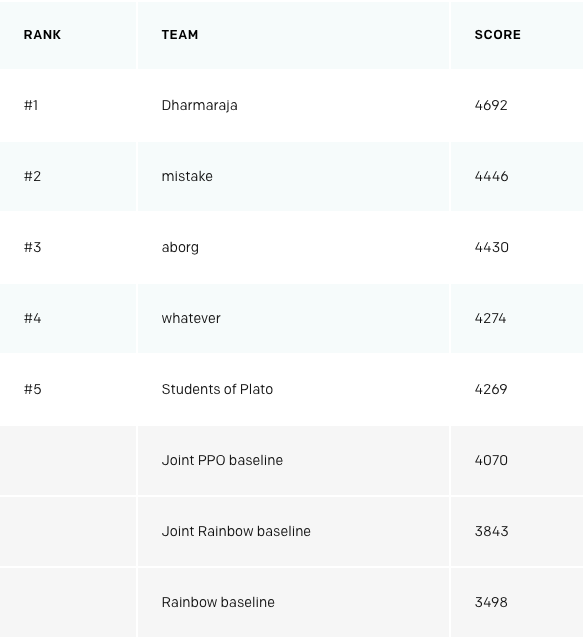
前五名排名
其中,冠军Dharmaraja在测试和评审中始终排名第一,mistake以微弱的优势战胜aborg取得第二。这张图显示了排名前三的三个方案的agent在同一个关卡学习的情况。红点代表初期,蓝点代表后期。从上到下分别是Dharmaraja、aborg和mistake。
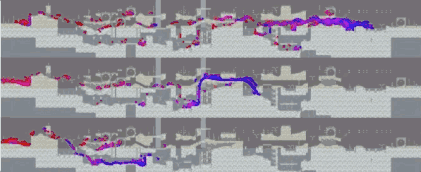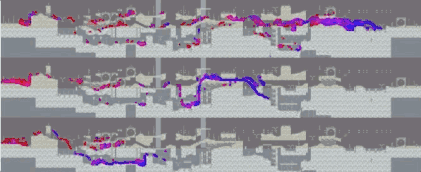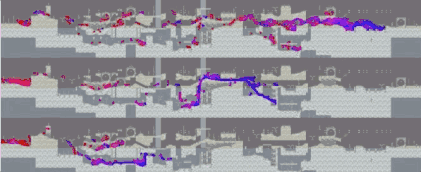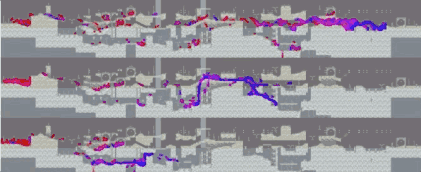
所有关卡平均下来,这几支队伍的学习曲线是这样的:
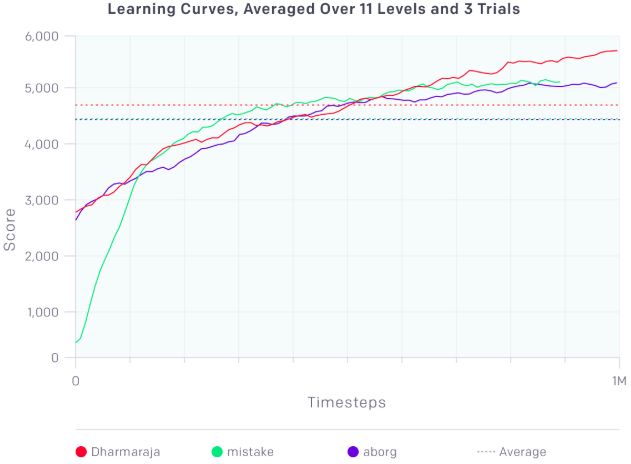
值得注意的是,Dharmaraja和aborg在开始阶段分数相近,而mistake的则要低很多。这是因为前两支队伍的方法,是对预训练网络进行微调(使用PPO),而mistake则是从零开始训练(使用Rainbow DQN)。mistake的学习曲线提前结束,是因为他们在12小时的时候时间用完了。
OpenAI对这次的竞赛的评价是,从整体看,虽然参赛队伍尝试了很多方法,但主要的结果都来自对现有算法(如PPO和Rainbow)的微调或扩展。同时,结果也显示了我们还有很长的路要走:训练后AI玩的最高成绩是4,692分,而理论最好成绩是10,000分。
但是,获胜的解决方案是一般的机器学习方法,而不是针对这次竞赛进行的hacking,表明作弊是不可能的,也就证实了OpenAI的Sonic基准是机器学习研究界一个值得去关注的问题。
获奖团队及方案:PPO和Rainbow优化
Dharmaraja(法王)是一个6人组成的团队:Qing Da、Jing-Cheng Shi、Anxiang Zeng、Guangda Huzhang、Run-Ze Li 和 Yang Yu。其中,Qing Da和Anxiang Zeng来自阿里巴巴搜索事业部AI团队,他们最近与南京大学副教授Yang Yu合作,研究如何将强化学习用于现实世界问题,尤其是电子商务场景。
Dharmaraja的解决方案是联合PPO的变体。PPO(proximal policy optimization,近端策略优化算法),是此前OpenAI为强化学习提出的一类新的策略梯度法,可以通过与环境的交互在样本数据中进行转换,使用随机梯度下降优化替代目标函数(surrogate objective function)。标准的策略梯度法是在每一个数据样本上执行一次梯度更新,而PPO的新目标函数可以在多个训练步骤(epoch)中实现小批量(minibatch)的更新。PPO 拥有置信域策略优化(TRPO)的一些好处,但更加容易实现,也更通用,并且有更好的样本复杂度。OpenAI研究人员认为,考虑到总体的复杂度、操作简便性和 wall-time,PPO 是比在线策略梯度法更好的选择。
在PPO的基础上,Dharmaraja的解决方案做了一些改进。首先,使用RGB图像而不是灰度图做输入。其次,使用了稍微扩大的动作空间,并使用更常见的按钮组合。第三,使用了增强奖励功能,奖励agent访问新的状态(根据屏幕的感知散列来判断)。
除了这些改进外,团队还尝试了许多东西,比如DeepMimic,使用YOLO进行对象检测,以及一些针对索尼克游戏的特定想法。不过这些方法并没有特别起效。
代码:https://github.com/eyounx/RetroCodes
Mistake
Mistake队有两名成员,Peng Xu和Qiaoling Zhong。他们都是研二的学生,来自中国科学院网络数据科学与技术重点实验室。
他们的解决方案是基于Rainbow基准。Rainbow是DeepMind对DQN算法进行的组合改良。DeepMind的实验表明,从数据效率和最终性能方面来说,Rainbow能够在Atari 2600基准上提供最为先进的性能。
Mistake团队进行了一些有助于提升性能的修改:n对n步Q-learning的更好的值;额外添加了一层CNN层到模型,这使得训练速度更慢但更好;DQN目标更新间隔更短。此外,团队还尝试与Rainbow进行联合训练,但发现这样做实际上降低了性能。
代码:https://github.com/xupe/mistake-in-retro-contest-of-OpenAI
-
阿里巴巴
+关注
关注
7文章
1625浏览量
47606 -
机器学习
+关注
关注
66文章
8454浏览量
133171 -
强化学习
+关注
关注
4文章
268浏览量
11313
原文标题:OpenAI首届迁移学习竞赛,南大阿里团队夺冠,中科院第二
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
迁移学习的原理,基于Keras实现迁移学习

我国首届人工智能·多媒体信息识别技术竞赛启动仪式在京召开
首届国网北京电力人工智能数据竞赛正式启动
腾讯宣布其人工智能球队获首届谷歌足球Kaggle竞赛冠军

一文详解迁移学习
商密大会传捷报|海泰方圆喜获首届“熵密杯”密码应用安全竞赛优胜奖

视觉深度学习迁移学习训练框架Torchvision介绍

OpenAI首届开发者日举办,新模型实现六大升级
高能回顾 | 首届OpenHarmony竞赛训练营精彩瞬间
深圳举办首届网络创新发展峰会,OpenAI市值突破1000亿美元






 工商网监
工商网监
评论