 三大算法模型引领,突围复杂网络语言分析困境
三大算法模型引领,突围复杂网络语言分析困境
6月23-24日,知乎在798举办了一场“阴阳怪气”主题书法展,现场不仅有阴阳怪气粉碎机、“瓦力”实验室等精彩互动,知乎社区治理团队也首次亮相,分享了知乎在识别“阴阳怪气”类内容上的探索。
据了解,知乎还将在近期对该技术进行产品化尝试,向用户提供“瓦力”阴阳怪气智能过滤选项,同时,还将对“瓦力”进行更多训练,不断提升准确率和召回率,最终将阴阳怪气识别技术全面应用到社区治理中。
三大算法模型引领,突围复杂网络语言分析困境
目前,知乎借助AI技术,并辅以人机结合和多元的产品举措,多重手段加强对社区氛围的维护。现阶段,知乎已实现对95%以上的违法违规、广告导流和不友善等内容的主动打击、覆盖和筛查 。
知乎运营总监孙达云表示, 过去一年,知乎全力探索对阴阳怪气类评论的解决方案。阴阳怪气可用“杠精”这个词来指代,通常以“不针对发言内容,而是批评对方的语气”以及“提出反对意见,但不给或给出极少数论据支持”这两类常见言论为代表,此类评论极大了伤害创作者和交流者的体验,但难以解决。
解决阴阳怪气类评论的难点核心主要在于网络语言的复杂性,情感分析不同于普通文本分析,例如经典的“呵呵”,由于双方不同关系、说话的不同场景和时间都会带来迥然不同的表意。即便是人工判定都存在标准化难度,算法模型的训练挑战就更为艰辛。
知乎团队的不懈努力下,针对阴阳怪气评论通常表达负面情感的特点,知乎构建了内容情感倾向性识别的算法模型和识别用户亲密度的模型,并通过训练不断迭代完善。
此外,针对阴阳怪气评论的典型特征,知乎建立了文本识别模型不断标记训练样本。三大模型的结合,不仅摆脱单一算法模型的局限性,也让“瓦力”的阴阳怪气识别准确率超过了大多数人工判断。
持续迭代技术方案 攻克情感分析前沿难题
知乎内容质量管理团队技术负责人刘兆来则详细介绍了“瓦力”最新的阴阳怪气技术方案:首先通过知乎社区里的举报、反对等负向用户行为收集训练数据。然后通过各种同义替换、规则模版方式对训练数据进行扩展,以缓解训练数据稀疏的问题。
同时,“瓦力”提取文本、句法、表情符等特征,并利用一个带attention的CNN和LSTM的融合模型进行分类,最终判断出内容是否为阴阳怪气。
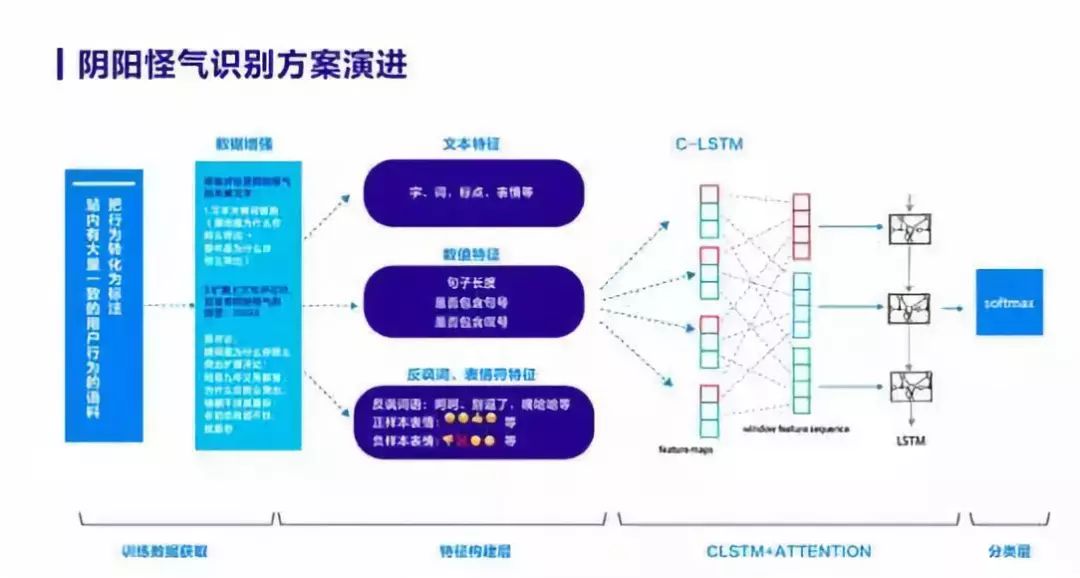
优化技术方案后,“瓦力”已能实现对“暗藏玄机夸奖”(忍不住关注答主了,你的答案很有水平!你博士快毕业了吧!)、“好为人师”(我觉得你挺惨,虽然长这么大了,还真应该回小学改造)、“强行反驳”(你开心就好、请开始你的表演)等数类阴阳怪气内容的识别。而根据知乎社区治理团队的调查,用户最反感的阴阳怪气言论大多属于这些类型,这意味着,“瓦力”在处理网络言语暴力上取得了阶段性进展。
刘兆来表示,未来将不断优化“瓦力”的识别能力,提高模型泛化能力,同时不断迭代更新模型,紧跟学术前沿的同时,适应网络语言的变化潮流。
知乎着力阴阳怪气识别技术,正是知乎“认真、专业、友善”社区精神的一次直观体现和有力践行。日益强大的“瓦力”已能实时解决答非所问、辱骂、贴标签等不友善问题,而人机结合的社区治理方式,以及用户深度参与社区自治,更让歧视、谣言八卦、愚昧偏见等内容在知乎难以找到立足之地。
-
AI算法
+关注
关注
0文章
252浏览量
12291 -
ai技术
+关注
关注
1文章
1281浏览量
24350
原文标题:GGAI 前沿 | 知乎优化AI算法“瓦力” 挑战“阴阳怪气”难题
文章出处:【微信号:ggservicerobot,微信公众号:高工智能未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论