 OpenAI的由5个神经网络组成的OpenAI Five,已经开始击败Dota 2的业余玩家队伍
OpenAI的由5个神经网络组成的OpenAI Five,已经开始击败Dota 2的业余玩家队伍

刚刚,OpenAI宣布了一个大新闻——他们的一个由5个神经网络组成的OpenAI Five,已经开始击败Dota 2的业余玩家队伍。
刚刚,OpenAI 宣布了一个大新闻——还记得去年他们的AI在 Dota2 1v1 比赛中战胜了人类职业玩家 Dendi吗?现在,OpenAI的由5个神经网络组成的OpenAI Five,已经开始击败Dota 2的业余玩家队伍。
4月23日,OpenAI Five首次击败了脚本基线。5月15日,OpenAI Five与第一队平分秋色,赢得了一场比赛并输掉了另一场。6月6日,OpenAI Five在与队伍1、2、3的比赛中全部获胜。之后,我们又与第4和第5队进行了非正式的比赛,预计会输得很惨,但OpenAI Five在前3场比赛中赢得了两场。
OpenAI表示,虽然他们现在玩的是有限制的游戏,但他们的目标是在8月份击败国际顶级职业团队(不过只限于一组有限的英雄)。同时,他们也坦承这个任务艰巨——“我们可能不会成功:Dota 2是世界上最流行和最复杂的电子竞技游戏之一,每年都有来自全世界最富有创造力和积极性的专业人员参赛,竞争Dota年度价值4000万美元的奖金(这也是所有电子竞技游戏中份额最大的奖金)。
如今,OpenAI Five每天都通过自我对战(self-play)来学习,而每天自我对战的量是180年的游戏——没错,是180年。它使用OpenAI提出的算法“近端策略优化”(PPO)的扩展版,在256个GPU和128,000个CPU内核上进行训练。每个英雄都使用单独的LSTM,不使用人类数据,最终AI能够学会识别策略。这表明,强化学习能够进行大但却可实现规模(large but achievable scale)的长期规划,而不发生根本性的进展,这与OpenAI开始项目时的预期相悖。
为了对他们所取得的进步衡量基准,OpenAI将在7月28日举行一场比赛,欢迎观看直播甚至亲临现场。
OpenAI Five与OpenAI玩DOTA最好的团队竞赛。比赛由暴风游戏的专业评论员和OpenAI Dota团队成员Christy Dennison进行了评论,也得到了玩家的观战。
国内首家决策智能公司创始人兼CEO袁泉点评:
Dota游戏是一个典型的AI难题,它综合了决策周期长,空间大而且敌我双方是在非完全信息下博弈。OpenAI继去年解决1v1的问题后,1年内能在5v5的更复杂情况下,完全依靠自我对抗学习、无显式通讯信道的前提下,即展现出了类似于人的长期规划协作能力,代表了多智能体决策智能的国际最高水准,也体现了大规模算力带来的美感。
Dota2究竟有多难?复杂程度超乎想象
玩星际争霸或Dota,需要AI在不确定的情况下进行推理与规划,涉及多个智能体协作完成复杂的任务,权衡短中长期不同的收益。相比下围棋这样的确定性问题,星际争霸/Dota的搜索空间要高出10个数量级。
因此,攻克星际争霸或者Dota这样的复杂电子竞技游戏,是AI的最大挑战之一,也将是AI的一个里程碑式的成就。
Dota 2 是一个实时竞技电子游戏,有两支5人队伍组成,每个人都控制一个英雄,能玩Dota的AI,必须掌握以下技巧:
很长的时间线。Dota游戏以每秒30帧的速度运行,平均时间为45分钟,因此每场游戏的时间tick为80,000次。大多数行为(例如命令英雄移动到某个位置)单独产生的影响较小,但有些个别的行为,比如在城市间移动(回城卷轴),可能会在战略上影响游戏。还有一些策略,则能影响整个战局。OpenAI Five每4帧观察一次,产生20,000次移动。相比之下,国际象棋通常在40次移动之前就结束,围棋则是150手移动前结束,而且几乎每一次移动都是战略性的。
部分观察状态。在Dota过程中,队伍(units)和建筑物只能看到他们周围的区域。地图的其他部分隐藏在雾中,敌人和他们的战略也是隐藏的。因此,比赛需要根据不完整的数据进行推断,并且需要对对手的最佳状态进行建模。相比之下,国际象棋和围棋都是信息完全显露出来的游戏。
高维连续动作空间。在Dota中,每个英雄可以采取数十个动作,而许多动作都是针对另一个单位(unit)或地面上的某个位置。OpenAI将每个英雄的空间分割成170,000个可能的行动;不计算连续部分,每个tick平均有大约1000次有效操作。国际象棋中的平均动作数为35,在围棋中,这是数字也只有250。
高维连续的观察空间。Dota在包含十个英雄,几十个建筑物,几十个NPC以及诸如符文、树木和病房等游戏长尾特征。OpenAI的模型通过Valve的Bot API观察Dota游戏的状态,其中20,000(大多是浮点)数字表示允许人类访问的所有信息。相比之下,国际象棋棋盘有大约70个枚举值(8x8的棋盘加6种棋子类型和其他一些的历史信息),而围棋则有大约400个枚举值(19x19的棋盘加黑白两种棋子)。
Dota规则也非常复杂。这是一个已经被积极开发了十多年的游戏,游戏逻辑在几十万行代码中实现。这个逻辑需要几毫秒的时间才能执行,而对于国际象棋或围棋引擎则只需要几纳秒。游戏也每两周更新一次,不断改变环境语义。
完全从自我对战中学习,128000CPU+256 P100GPU
OpenAI的系统使用Proximal Policy Optimization的大规模版本进行学习。OpenAI Five和OpenAI早期的1v1 bot都是完全从自我对战中学习。它们从随机参数开始,不使用来自人类回放(replay)的搜索或引导。
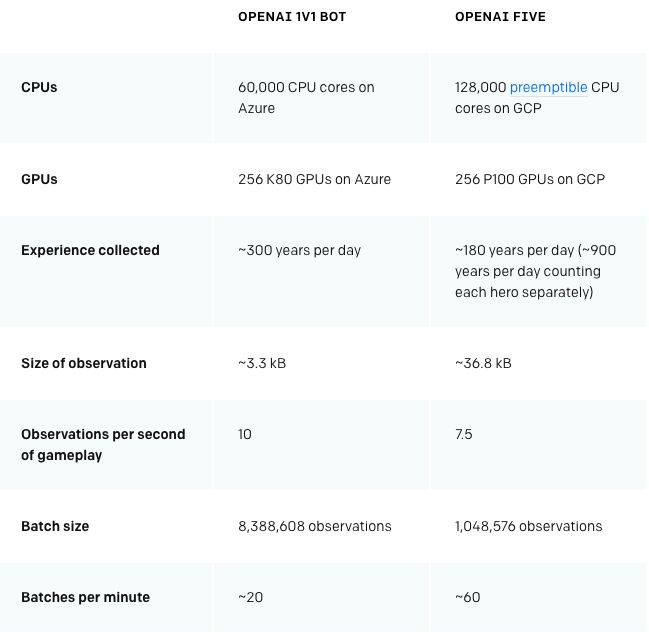
RL研究人员(包括OpenAI自己)一般认为,长时间视野(long time horizons)需要从根本上取得新的进展,比如分层强化学习。结果表明,实际上现如今的算法已经足够,至少当它们以足够的规模和合理的探索方式运行时。
OpenAI的agent经过训练,可以最大化未来奖励的指数衰减总和,并由称为γ的指数衰减因子加权。在最新的OpenAI Five训练中,他们从0.998(评估未来奖励的半衰期为46秒)到0.9997(评估未来奖励的半衰期为五分钟)退化γ。相比之下,PPO论文中最长的half-life是0.5秒,Rainbow论文中最长的半衰期为4.4秒。
尽管当前版本的OpenAI Five在最后一击时表现不佳,但其objective prioritization已经堪比一个常见的专家。获得战略地图控制等长期回报往往需要牺牲短期回报,例如从农业获得的黄金,因为组建攻击塔需要时间。这表明系统真正在进行长期的优化。
模型结构
每个OpenAI Five网络都包含一个单层的、1024-unit的LSTM,它可以查看当前的游戏状态(从Valve的Bot API中提取),并通过几个可能的action heads发出动作。每个 head都具有语义含义,例如,延迟动作的刻度数,选择一个动作时,该动作在单元周围网格中的X或Y坐标等。Action heads是独立计算的。
OpenAI Five使用观察空间和动作空间进行交互式演示。OpenAI Five将世界视为20000个数字的列表,并通过发出一个包含8个枚举值的列表来采取行动。选择不同的行动和目标以了解OpenAI Five如何编码每个动作,以及它如何观察世界。下图显示了人类会看到的场景。
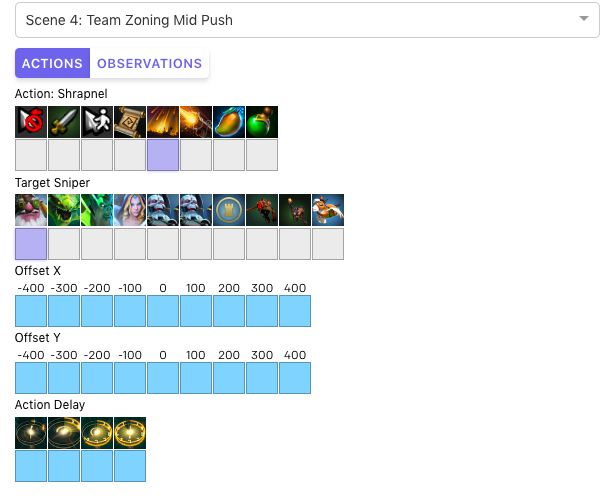
OpenAI Five可以对丢失的与它所看到的相关的状态片段做出反应。例如,直到最近,OpenAI Five的观察都还没有包括弹片区域(弹片落在敌人身上的区域),人类在屏幕上能看到这些区域。然而,我们观察到OpenAI Five学习走出(虽然不能避免进入)活跃的弹片区域,因为当进入弹片区时,它可以看到它的健康状况在下降。
探索
尽管有学习算法能够处理较长的视野,我们仍然需要探索环境。即使我们设了限制,仍然有数百个物品,几十种建筑,法术和单元类型,以及需要了解的复杂的游戏机制——其中许多产生了强大的组合。要有效地探索这个巨大的空间并不容易。
OpenAI Five从自我玩游戏(self-play)过程中学习(从随机权重开始),这为探索环境提供了一个自然的设置。为了避免“战略崩溃”,agent在80%的游戏中进行自我训练,其余20%的游戏则与过去的自己对战。在第一场比赛中,英雄漫无目的地在地图上漫步。经过几个小时的训练后,出现了诸如laning、farming或中期战斗等概念。几天之后,它们一直采用基本的人类策略:试图从对手手中夺取神符,步行到一级塔去农场,并在地图周围旋转英雄以获得lane优势。通过进一步的训练,它们变得精通5-hero push 这样的高级战略了。
在2017年3月,我们的第一个agent击败了bot,但仍然搞不定人类。为了强制在战略空间进行探索,在训练期间(并且只在训练期间),我们对这些单元的属性(健康,速度,启动级别等)进行了随机化,然后用它开始能与人类对打。后来,当一名测试玩家一直不断地击败我们的1v1 bot时,我们增加了随机训练,测试玩家开始出现失败。(我们的机器人团队同时将类似的随机化技术应用于物理机器人身上,以便从模式世界转换到现实世界。)
OpenAI Five使用我们为1v1 bot编写的随机数据。它还使用一个新的“lane assignment”。在每次训练游戏开始时,我们随机地将每个英雄“分配”给一些lane的子集,并在它发生偏离是对其进行惩罚,直到游戏中随机选择的时间。
这样的探索得到了很好的回报。我们的奖励主要由衡量人类如何在游戏中做决定的指标组成:净价值,kills,死亡,助攻,上次命中等等。我们通过减去另一组的平均奖励后处理每个agent的奖励,以防止agent找到 positive-sum 的情况。
我们硬编码项目和技能构建(最初为我们的脚本基准编写),并选择随机使用哪些构建。
协调
OpenAI Five不包含英雄神经网络之间的明确通信渠道。团队合作由我们称为“团队精神”(team spirit)的超参数控制。team spirit的范围从0到1,对OpenAI Five的每个英雄应该关心其个人奖励函数与团队奖励函数的平均值赋予权重。我们在训练中将它的值从0降到1。
快速
我们的系统是一个称为Rapid的通用RL训练系统,可用于任何Gym环境。我们已经使用Rapid解决了OpenAI的其他一些问题,包括竞争性的自我对战。
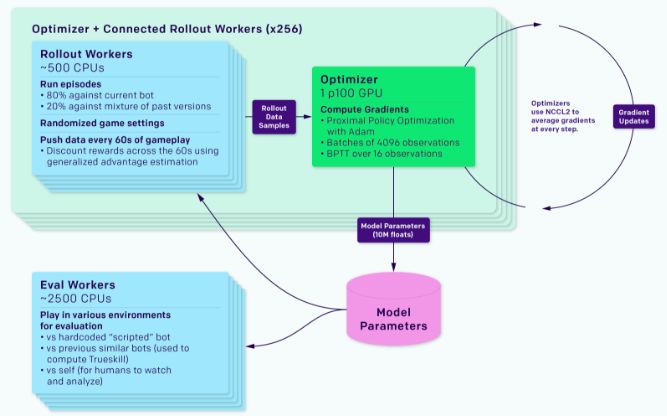
训练系统分为运行游戏副本的rolloutworker和收集经验的agent,以及optimizer节点,这些节点在整个GPU队列中执行同步梯度下降。 rollout worker通过Redis将它们的经验同步到optimizer每个实验还包括训练好的agent进行评估,以及监控软件,如TensorBoard,Sentry和Grafana。
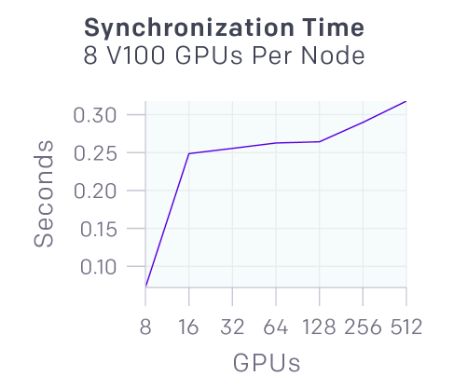
在同步梯度下降过程中,每个GPU计算batch部分的梯度,然后对梯度进行全局平均。下图显示了不同数量的GPU同步58MB数据的延迟。
我们为Rapid实施了Kubernetes,Azure和GCP后端。
游戏结果
到目前为止,OpenAI Five已经(在我们的限制下)与这些对手进行了比赛:
最佳OpenAI员工团队:2.5k MMR(46th percentile)
观看OpenAI员工比赛的最佳观众(包括第一次OpenAI员工比赛的解说员Blitz):4-6k MMR(90th-99th percentile),尽管他们从来没有作为一个团队参赛。
Valve employee团队:2.5-4k MMR(46th-90th percentile)。
业余团队:4.2k MMR(93rd percentile),训练为一支队伍。
半专业团队:5.5k MMR(99th percentile),训练为一支队伍。
4月23日版的OpenAI Five是第一个击败我们的脚本基线的版本。5月15号的OpenAI Five与第一队旗鼓相当,赢了一场比赛,又输了一场。6月6日的OpenAI Five战胜了1-3对。我们和4队、5队建立了非正式的比赛,预计出现很差的表现,但是OpenAI Five在前三场比赛中均赢了两场。
“机器人的团队合作方面简直势不可挡,感觉就像五个无私的玩家一样,知道一个很好的总体战略。”——— Blitz
我们发现OpenAI Five:
为了换取控制敌人的优势路safelane,多次牺牲自己的优势路(上路是夜魇,下路是天辉),迫使战斗向敌人更难防御的一边进行。这种策略在过去几年出现在专业领域,现在被认为是流行的策略。Blitz说他是在经过8年的比赛后才知道这一点的,当时Team Liquid告诉他这件事。
从比赛初期到赛季中期的转场比对手更快。 它是这样做的:(1)当玩家在他们路上过度扩张时,建立成功的Ganks;(2)在对手组织对抗之前组队占领塔。
在少数领域偏离了目前的游戏风格,比如给予支持英雄许多早期经验和黄金。 OpenAI Five的优先级使得它的伤害更早达到顶峰,并使它的优势更加强大,赢得团队战斗并利用错误来确保快速的胜利。
与人类的不同之处
OpenAI Five可以访问与人类相同的信息,但是它可以立即看到诸如位置、健康状况和物品清单等数据,这些数据是人类必须手动检查的。我们的方法与观察状态没有本质的联系,但是仅仅从游戏中渲染像素就需要数千个GPU。
OpenAI Five的平均动作速度约为每分钟150-170个动作(理论上最大动作速度为450个,因为每隔4帧就观察一次)。对于熟练的玩家来说,帧完美的时机对于OpenAI Five来说是微不足道的。 OpenAI Five的平均反应时间为80ms,比人类快。
这些差异在1v1中最为重要(我们的机器人的响应时间为67ms),但是我们已经看到人类从机器人身上学习并适应机器人,所以竞技场相对比较公平。数十位专业人士在去年TI的几个月里使用我们的1v1机器人进行训练。根据Blitz的说法,1v1机器人改变了人们对1v1的看法(机器人采用了快节奏的游戏风格,现在每个人都适应了)。
一些惊人的发现
二元奖励能够带来好的表现。我们的1v1模型有一个有形的奖励,包括对最后命中目标、杀戮等等的奖励。我们做了一个实验,只奖励那些获胜的agent或只奖励失败的agent,它训练一个数量级更慢,并且在中间有一些停滞,这与我们通常看到的平滑的学习曲线形成了对比。实验运行在4500个内核和16个k80 GPU上,训练到半专业级(70个TrueSkill),而不是我们最好的1v1机器人的90个TrueSkill。
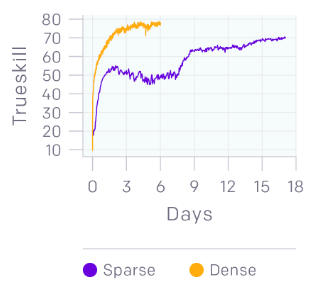
Creep blocking可以从头开始学习。对于1v1,我们学习了使用传统RL进行creep blocking并带有“creep block”奖励。我们的一个团队成员在休假时离开了2v2模型的训练,打算看看还需要多久的训练才能提高性能。令他惊讶的是,这个模型学会了没有任何特别的指导或奖励的情况下creep block。
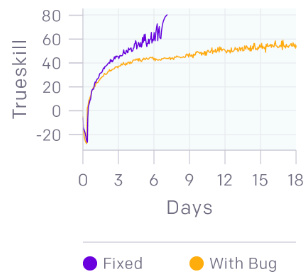
我们还在修复bug。上面的图表显示了击败业余玩家的代码的训练运行情况,相比之下,我们只是修复了一些bug,比如在训练中偶尔发生的崩溃,或者达到25级时导致一个大的负面奖励的错误。事实证明,这个系统有可能击败人类高手,但同时也可能隐藏着严重的bug!
接下来是什么?
我们的队伍正集中精力完成我们8月份的目标。我们不知道这个目标能否实现,但我们相信,只要努力工作(还有点运气),我们就能实现。
这篇文章描述了6月6日我们系统的快照。在超越人类性能的过程中,我们将发布更新,并在项目完成后就最终系统编写报告。请在7月28日加入我们,届时我们将与一组顶级球员比赛!
我们的目标是超越Dota。现实世界人工智能的部署将需要处理Dota提出的挑战,而这些挑战并不反映在国际象棋、围棋、雅达利游戏或Mujoco基准测试任务中。最后,我们将衡量Dota系统在实际任务中的应用成功程度。
-
cpu
+关注
关注
68文章
11364浏览量
226319 -
神经网络
+关注
关注
42文章
4845浏览量
108341 -
强化学习
+关注
关注
4文章
275浏览量
12012
原文标题:【攻克Dota2】OpenAI自学习多智能体5v5团队战击败人类玩家
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论