 用Python玩个“小小的”大数据
用Python玩个“小小的”大数据
Google Ngram viewer是一个有趣和有用的工具,它使用谷歌从书本中扫描来的海量的数据宝藏,绘制出单词使用量随时间的变化。举个例子,单词Python(区分大小写):
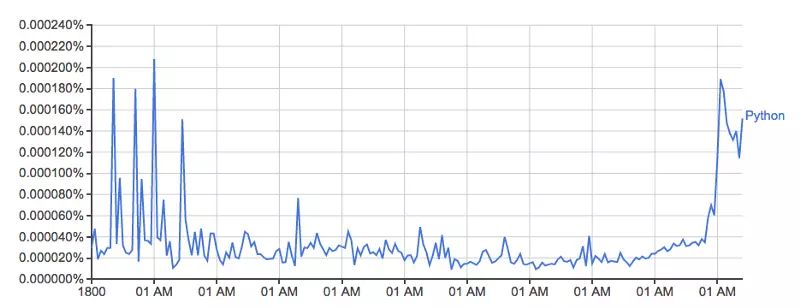
这幅图来自:books.google.com/ngrams/grap…,描绘了单词 'Python' 的使用量随时间的变化。
它是由谷歌的n-gram数据集驱动的,根据书本印刷的每一个年份,记录了一个特定单词或词组在谷歌图书的使用量。然而这并不完整(它并没有包含每一本已经发布的书!),数据集中有成千上百万的书,时间上涵盖了从 16 世纪到 2008 年。数据集可以免费从这里下载。
我决定使用 Python 和我新的数据加载库PyTubes来看看重新生成上面的图有多容易。
挑战
1-gram 的数据集在硬盘上可以展开成为 27 Gb 的数据,这在读入 python 时是一个很大的数据量级。Python可以轻易地一次性地处理千兆的数据,但是当数据是损坏的和已加工的,速度就会变慢而且内存效率也会变低。
总的来说,这 14 亿条数据(1,430,727,243)分散在 38 个源文件中,一共有 2 千 4 百万个(24,359,460)单词(和词性标注,见下方),计算自 1505 年至 2008 年。
当处理 10 亿行数据时,速度会很快变慢。并且原生 Python 并没有处理这方面数据的优化。幸运的是,numpy真的很擅长处理大体量数据。 使用一些简单的技巧,我们可以使用 numpy 让这个分析变得可行。
在 python/numpy 中处理字符串很复杂。字符串在 python 中的内存开销是很显著的,并且 numpy 只能够处理长度已知而且固定的字符串。基于这种情况,大多数的单词有不同的长度,因此这并不理想。
Loading the data
下面所有的代码/例子都是运行在8 GB 内存的 2016 年的 Macbook Pro。 如果硬件或云实例有更好的 ram 配置,表现会更好。
1-gram 的数据是以 tab 键分割的形式储存在文件中,看起来如下:
Python158742
Python162111
Python165122
Python165911
每一条数据包含下面几个字段:
1.Word
2.Year of Publication
3.Total number of times the word was seen
4.Total number of books containing the word
为了按照要求生成图表,我们只需要知道这些信息,也就是:
1. 这个单词是我们感兴趣的?
2. 发布的年份
3. 单词使用的总次数
通过提取这些信息,处理不同长度的字符串数据的额外消耗被忽略掉了,但是我们仍然需要对比不同字符串的数值来区分哪些行数据是有我们感兴趣的字段的。这就是 pytubes 可以做的工作:
import tubes
FILES = glob.glob(path.expanduser("~/src/data/ngrams/1gram/googlebooks*"))
WORD = "Python"
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.multi(lambda row: (
row.get(0).equals(WORD.encode('utf-8')),
row.get(1).to(int),
row.get(2).to(int)
))
)
差不多 170 秒(3 分钟)之后,onegrams_ 是一个 numpy 数组,里面包含差不多 14 亿行数据,看起来像这样(添加表头部为了说明):
╒═══════════╤════════╤═════════╕
│ Is_Word │ Year │ Count │
╞═══════════╪════════╪═════════╡
│ 0 │ 1799 │ 2 │
├───────────┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1805 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1811 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1820 │ ... │
╘═══════════╧════════╧═════════╛
从这开始,就只是一个用 numpy 方法来计算一些东西的问题了:
每一年的单词总使用量
谷歌展示了每一个单词出现的百分比(某个单词在这一年出现的次数/所有单词在这一年出现的总数),这比仅仅计算原单词更有用。为了计算这个百分比,我们需要知道单词总量的数目是多少。
幸运的是,numpy让这个变得十分简单:
last_year = 2008
YEAR_COL = '1'
COUNT_COL = '2'
year_totals, bins = np.histogram(
one_grams[YEAR_COL],
density=False,
range=(0, last_year+1),
bins=last_year + 1,
weights=one_grams[COUNT_COL]
)
绘制出这个图来展示谷歌每年收集了多少单词:
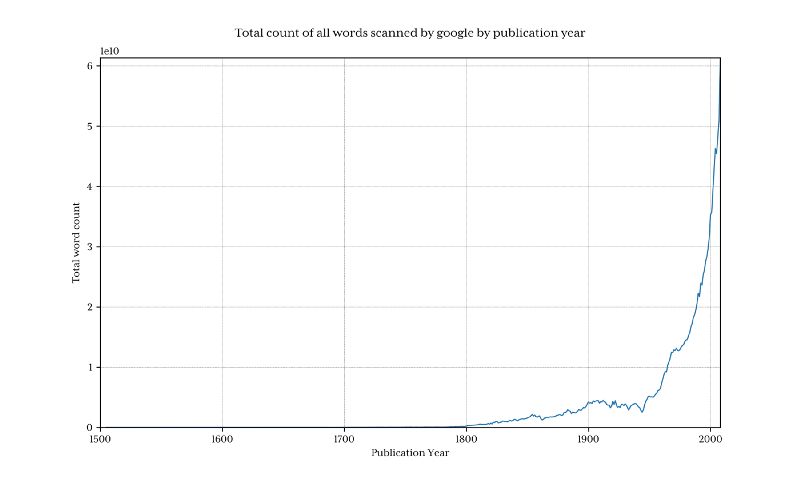
很清楚的是在 1800 年之前,数据总量下降很迅速,因此这回曲解最终结果,并且会隐藏掉我们感兴趣的模式。为了避免这个问题,我们只导入 1800 年以后的数据:
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.skip_unless(lambda row: row.get(1).to(int).gt(1799))
.multi(lambda row: (
row.get(0).equals(word.encode('utf-8')),
row.get(1).to(int),
row.get(2).to(int)
))
)
这返回了 13 亿行数据(1800 年以前只有 3.7% 的的占比)
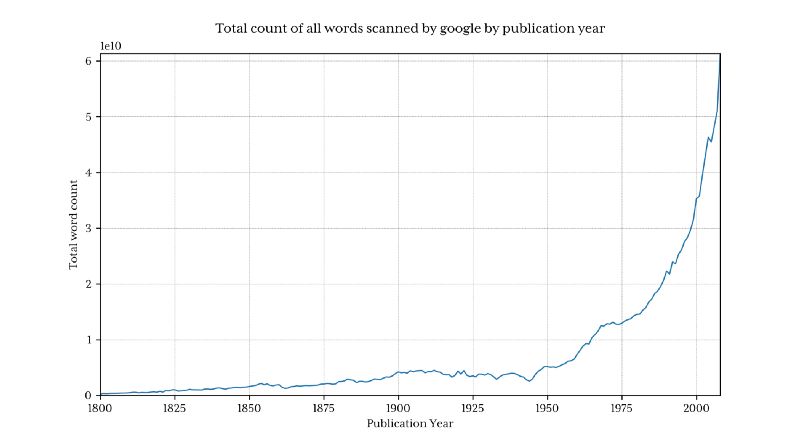
Python 在每年的占比百分数
获得 python 在每年的占比百分数现在就特别的简单了。
使用一个简单的技巧,创建基于年份的数组,2008 个元素长度意味着每一年的索引等于年份的数字,因此,举个例子,1995 就只是获取 1995 年的元素的问题了。
这都不值得使用 numpy 来操作:
word_rows = one_grams[IS_WORD_COL]
word_counts = np.zeros(last_year+1)
for _, year, count in one_grams[word_rows]:
word_counts[year] += (100*count) / year_totals[year]
绘制出 word_counts 的结果:
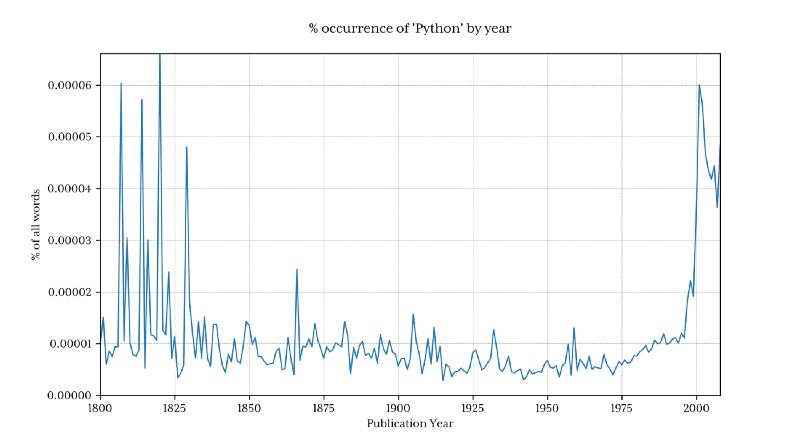
形状看起来和谷歌的版本差不多
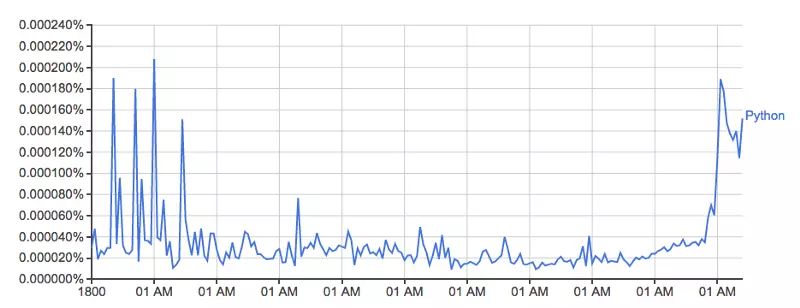
实际的占比百分数并不匹配,我认为是因为下载的数据集,它包含的用词方式不一样(比如:Python_VERB)。这个数据集在 google page 中解释的并不是很好,并且引起了几个问题:
人们是如何将 Python 当做动词使用的?
'Python' 的计算总量是否包含 'Python_VERB'?等
幸运的是,我们都清楚我使用的方法生成了一个与谷歌很像的图标,相关的趋势都没有被影响,因此对于这个探索,我并不打算尝试去修复。
性能
谷歌生成图片在 1 秒钟左右,相较于这个脚本的 8 分钟,这也是合理的。谷歌的单词计算的后台会从明显的准备好的数据集视图中产生作用。
举个例子,提前计算好前一年的单词使用总量并且把它存在一个单独的查找表会显著的节省时间。同样的,将单词使用量保存在单独的数据库/文件中,然后建立第一列的索引,会消减掉几乎所有的处理时间。
这次探索确实展示了,使用 numpy 和 初出茅庐的 pytubes 以及标准的商用硬件和 Python,在合理的时间内从十亿行数据的数据集中加载,处理和提取任意的统计信息是可行的,
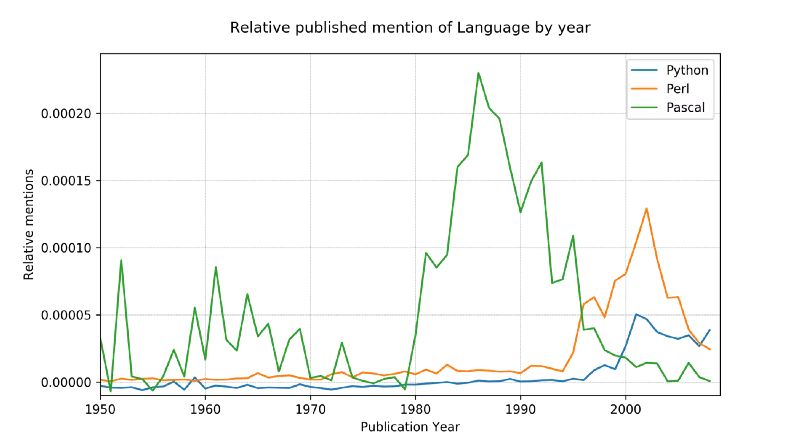
语言战争
为了用一个稍微更复杂的例子来证明这个概念,我决定比较一下三个相关提及的编程语言:Python,Pascal,和Perl.
源数据比较嘈杂(它包含了所有使用过的英文单词,不仅仅是编程语言的提及,并且,比如,python 也有非技术方面的含义!),为了这方面的调整, 我们做了两个事情:
只有首字母大写的名字形式能被匹配(Python,不是 python)
每一个语言的提及总数已经被转换到了从 1800 年到 1960 年的百分比平均数,考虑到 Pascal 在 1970 年第一次被提及,这应该有一个合理的基准线。
结果:
对比谷歌 (没有任何的基准线调整):
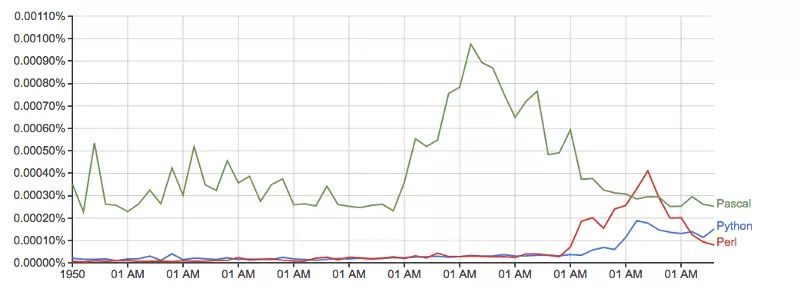
运行时间: 只有 10 分钟多一点
代码:gist.github.com/stestagg/91…
以后的 PyTubes 提升
在这个阶段,pytubes 只有单独一个整数的概念,它是 64 比特的。这意味着 pytubes 生成的 numpy 数组对所有整数都使用 i8 dtypes。在某些地方(像 ngrams 数据),8 比特的整型就有点过度,并且浪费内存(总的 ndarray 有 38Gb,dtypes 可以轻易的减少其 60%)。 我计划增加一些等级 1,2 和 4 比特的整型支持(github.com/stestagg/py…)
更多的过滤逻辑 - Tube.skip_unless() 是一个比较简单的过滤行的方法,但是缺少组合条件(AND/OR/NOT)的能力。这可以在一些用例下更快地减少加载数据的体积。
更好的字符串匹配 —— 简单的测试如下:startswith, endswith, contains, 和 isoneof 可以轻易的添加,来明显地提升加载字符串数据是的有效性。
一如既往,非常欢迎大家patches!
-
谷歌
+关注
关注
27文章
6211浏览量
106486 -
python
+关注
关注
56文章
4813浏览量
85301 -
大数据
+关注
关注
64文章
8929浏览量
138263
原文标题:使用 Python 分析 14 亿条数据
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何从零学大数据?
大数据运用的技术
学习Python大数据与机器学习必会Matplotlib知识
用 Python 实现一个大数据搜索引擎
一个python脚本看透Linux程序对库的依赖

用Python做几个表情包
小小的采样电阻,还真有点门道!资料下载

♥51单片机也可以实现一个小小的智能家居√(smart-home)♥





 工商网监
工商网监
评论