 如何很容易地将数据共享为Kaggle数据集
如何很容易地将数据共享为Kaggle数据集
Kaggle,对于很多学习并从事数据科学和机器学习的同学们来说应该一点也不陌生。除了每年举办一次的 Kaggle 竞赛被大家广泛关注着,相信老司机们更是经常使用 Kaggle 的数据集并在上面进行实践练习。李飞飞也对 Kaggle 评论道:“Kaggle 是搜寻、分析公共数据集,开发机器学习模型,和提高数据科学专业水平的最佳场所。” 去年 Google 收购 Kaggle ,并提出 “推动 AI 技术的分享和推广” 的使命。
在研究和工业界中,除了提升模型能力外,高质量的结构化数据对结果也会产生不可忽视的影响。因此,人工智能头条今天特别给大家分享一篇在 Kaggle 上发表的关于共享数据集收集工作的困难和重要性的文章,希望今后可以有更多的数据集被收集与共享。文章的最后还为大家分享了关于 Kaggle 搜索的Tips,希望对大家的学习和使用数据集有所帮助。
▌前言
本文由斯坦福大学研究计算和斯坦福医学院的研究软件工程师Vanessa Sochat 撰写。
我们都知道,数据共享是一件很难的事,但在发现与奖励方面具有很大的潜力。一个典型的 “共享操作” 可能看起来像是在移动硬盘上传递信息,将压缩档案放在某个大学或云服务器上,或批量存储在一个安全的大学集群中。这是最佳方法吗?这是容易的事吗?要回答这些问题,首先考虑一下数据采集的可能经历的旅程。它看起来像下面这样:

因为数据的生成更像是一个流,这一过程流经常是周期性的,数据从步骤 1 到 步骤 6 的过程中停止的唯一原因就是我们决定停止收集。在最理想的情况下,我们希望将这些步骤完全自动化。第 1 步 我们可能是在 MRI 扫描仪上生成图像,第 2 步可能是用自动化脚本将初始文件格式转化为研究人员所需的格式,第 3 步移动到专用集群存储,第 4 步用于研究组进行使用,第 5 步和第 6 步 (如果两步全部发生)是额外的工作,进行再次处理并将数据传输到共享位置。
通常我们在第 4 步时就停止了,因为进行到此处已经可以满足实验室的需求,分析完成并写入文件。有点讽刺的是,在第 5 和 6 步有可能会开启潜在的发现之门。但不言而喻的是,如果我分享了我的数据集,但你先发布,那么我就输了。数据就像橙子一样,在把它的所有汁液榨干之前,我当然不想分享出去。但是,如果共享数据集本身可以生成一篇论文(或者类似的东西),并且,如果步骤4和步骤5很容易,我们就将会有更多的数据共享。这也是我今天要讨论的主题,虽然没有可用的生产解决方案,但我将展示如何很容易地将数据共享为 Kaggle 数据集。
▌动态数据
之前我谈到了关于living data的想法,概括的讲因为新数据的出现,我们可以更新我们对世界的理解,关于有趣问题的答案。知识表示为静态PDF还不够好,因为它只表示了一个时间点。相反,动态数据证实了我们积累的用来证实或否认假设的,知识是一种有生命的、不断变化的东西。为了使这个充满生机和变化的东西成为现实,要求提供时需要很容易。
现在,共享数据是在发布过程之后的手工操作。许多期刊已经鼓励或要求进行数据共享,研究人员可以把某个时间点的数据集上传至不同的平台。我不认为这是了解世界的最佳方式,但是这种做法总比什么都不做好。我们不应该使用静态文章,而应该使用数据提要,这些数据代入算法中并得到新的答案。我们希望数据共享在数据生成时可以自动进行,并且对所有想要研究它的研究人员开放。就目前而言,这可能是一个过于崇高的目标,但我们可以想象在两个极端之间有可能会发生什么。
一个自动生成和共享数据集的简单管道又是怎么样的? 可能像下面这样:

第 4 步到第 6 步仍然会发生(研究人员正在做分析),但不是有一组人渴望得到这些数据,而是为了有成千上万的人可以使用它们。不同的是我们在步骤 3 中添加了一个助手,即持续集成,用以简化处理和共享数据的过程。我们通常认为持续集成(CI)用于测试或部署,但它也可能是数据共享的有用工具。因此我们把这个概念叫做"连续数据"。一旦数据被处理并传输到研究组的存储中,它也可能具有这个连续的数据步骤,将其打包以便共享。
▌Kaggle API
虽然一个更大的、机构层面的努力是理想的,但与此同时,我们也可以利用开源,免费使用Kaggle 这样的资源。我认为 Kaggle 有可能做 Github 在早期科学重现性方面所做的事情。如果共享数据集既简单又有趣,有潜在的回报,Kaggle 将会对规模化的发现和协作产生影响。但我们需要一个开始!我决定从显示我可以使用的 Kaggle API 来上传数据集开始。它在 Web 界面中很容易实现,利用命令行也很容易实现。简单来说,我们需要的只是一个包含数据文件和元数据(json文件)的目录,我们可以将API客户端指向该目录。例如,这是我上传的一个数据集:

datapackage.json 描述正在上传的内容
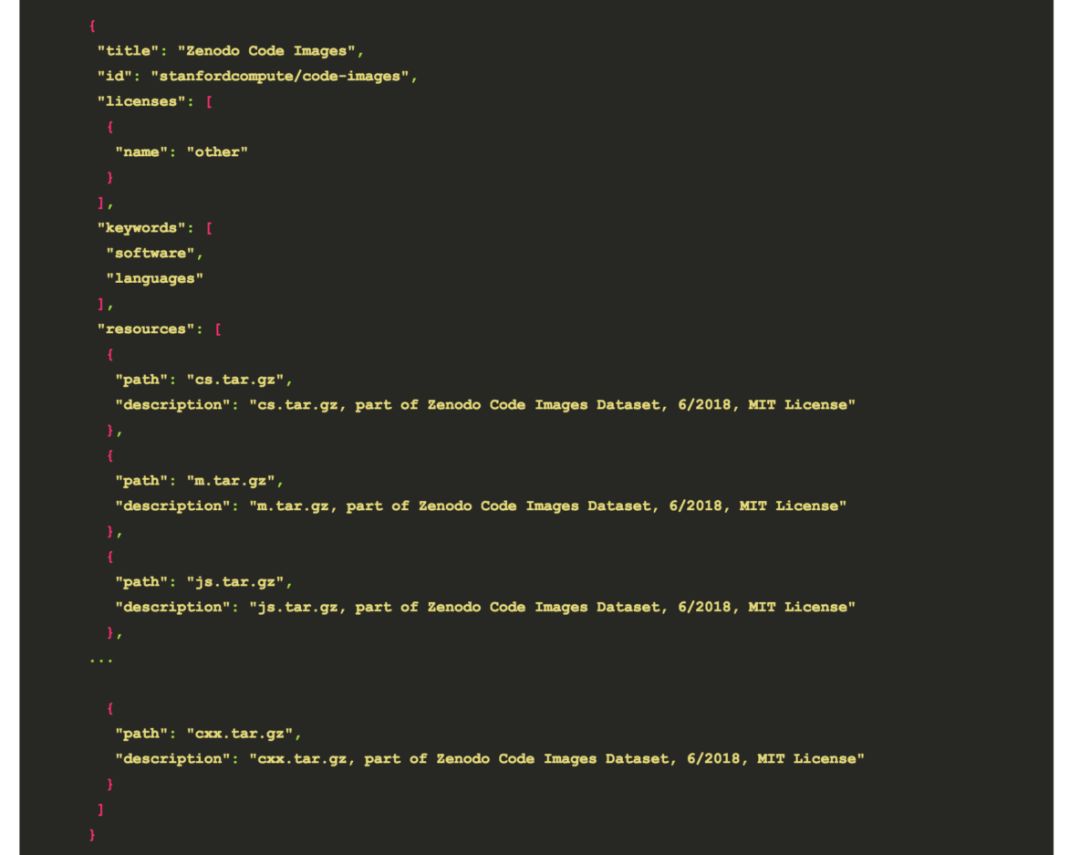
那么,分享你的数据集供给他人使用和发现有多难呢?你可以下载一个文件证书来认证服务。然后把文件(.tar.gz or .csv)放入文件夹中,创建一个 json 文件,并将工具指向它。这些操作很简单,你几乎可以不用任何额外的帮助就完成所有这些事情。将这样的脚本插入到一些连续集成中,以便在将数据集添加到存储时更新数据集。
▌Tools
在这里我创建了一个 Docker 容器,提供了一个之前与 Kaggle API 交互并生成一些数据集的简短的示例。我在这里介绍一下脚本的基本逻辑。Kaggle 命令行客户端在很多任务上都做得很好,但是作为一名开发人员,我希望更多地控制元数据规范和文件的创建。我还希望对它进行 Dockerized,这样我就可以执行一个与主机隔离的创建操作。
▌创建容器
此映像提供在 Docker Hub 上,你也可以自己构建:

我没有将创建脚本公开为入口点,因为我希望这是一个“shell到容器中,并了解发生了什么”的交互,你可以这样做:

▌创建数据集
create_dataset.py 脚本位于工作目录中,此方法接收您希望生成数据集的参数。你可以不带参数运行该脚本来查看细节:
对于这篇文章,更容易看到一个例子,在 /tmp/data/ARCHIVE,我有我的数据集文件(.tar.gz files),所以我首先准备了一份空白的完整路径列表:

然后我想把它们上传到一个叫做 vanessa/code-images.命令行如下:

上述涉及的参数说明如下:
关键字:以逗号分隔的关键字列表(无空格!)
文件:要上传的数据文件的完整路径
标题:数据集标题(有空格需要加上引号)
命名:数据集本身的名称(不能包含空格或特殊字符以及引号)
用户名:你的 kaggle 用户名,或数据集所属组织的名称
接下来将会生成一个包含数据包的临时目录:

然后将文件添加到其中,例如,这是我的临时文件夹的结果:

回顾上述过程,我不需要在此复制文件,因为一般我不喜欢对原始数据执行任何类型的操作(以防出错)。然后,该工具将显示元数据文件(上面已经显示过的文件),然后启动上载。此过程需要一些时间,完成后会显示一个 URL!

重点提示!有一些后期处理发生,这可能需要很多额外的时间(考虑到上传的大小,这对我来说确实如此)。我的数据集实际上直到第二天早上才存在于给定的 URL 中,所以这个过程应该需要耐心。在完成之前,你会得到一个 404。你可以去跑步,或者今天就到此为止。
机构需要优先考虑数据,并帮助研究人员管理自己的数据。研究者应该能够得到支持来管理他们的数据,然后让它以编程的方式访问。这必须超越传统库提供的 “归档”,深入研究api、通知、部署或分析触发器。虽然我们没有这些生产系统,但一切都是从简单的解决方案开始的,以便轻松创建和共享数据集。我的设想是,在进行计算的地方 (我们的研究计算集群)和数据存储的地方(以及通过上载或API自动共享的地方)之间建立牢固的关系。类似这样:

通知的范围可以从任何地方发出:
(1)进入一个提要以告诉另一研究人员新数据;
(2)触发 CI 作业从存储重新上载到共享位置;
(3)触发某个容器的新版本的构建和部署,该容器将数据作为依赖项
▌What We Need:数据工程师 & 协作平台
一个机构需要分配资源和人员来帮助研究人员提供数据。我相信,在未来,研究人员可以通过协作平台,通过其他研究人员提供的数据源,共同合作进行研究。
更多内容可访问原文链接
http://blog.kaggle.com/2018/06/21/open-source-datasets-with-kaggle/
通过上面的介绍,大家肯定已经感受到收集数据集这项工作的艰难和重要意义。而作为学习者,Kaggle,一个神一般的资源,面对成千上万并每天都会更新添加的数据,我们又该如何找到数据集呢?接下来大为家介绍一些技巧和窍门,希望可以帮助大家更好的学习并利用 Kaggle,找到对自己有用处,感兴趣的数据集。
原文链接:
http://blog.kaggle.com/2017/09/11/how-can-i-find-a-dataset-on-kaggle/
▌从数据集页面搜索
点击 Kaggle 页面顶部显示的 “数据集” 标签,即可进入数据集页面
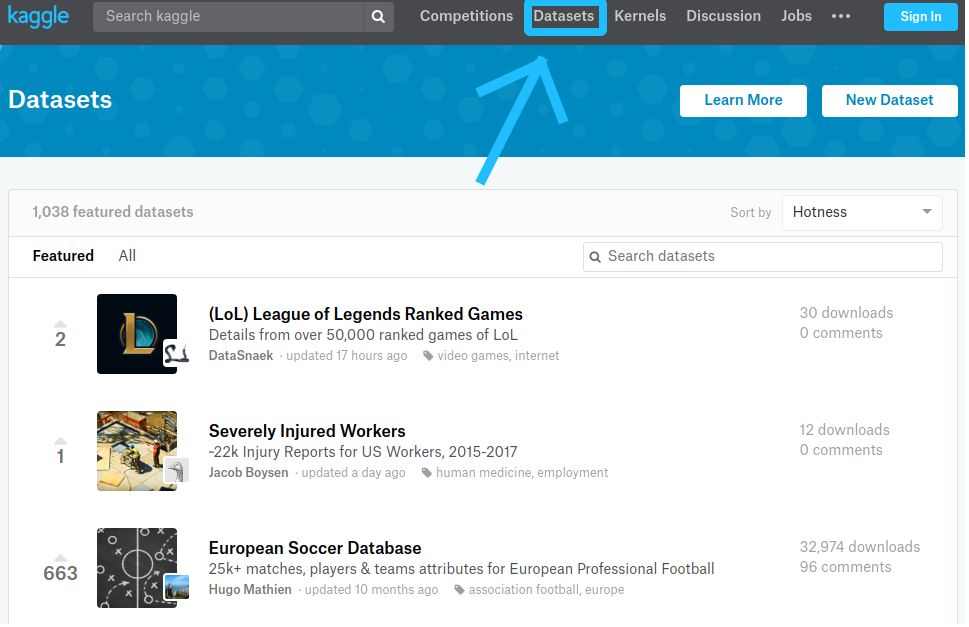
▌数据集搜索
当您在数据集页面中使用搜索栏时,与使用页面顶部的搜索栏不同,您将获得包含所有搜索结果的新页面
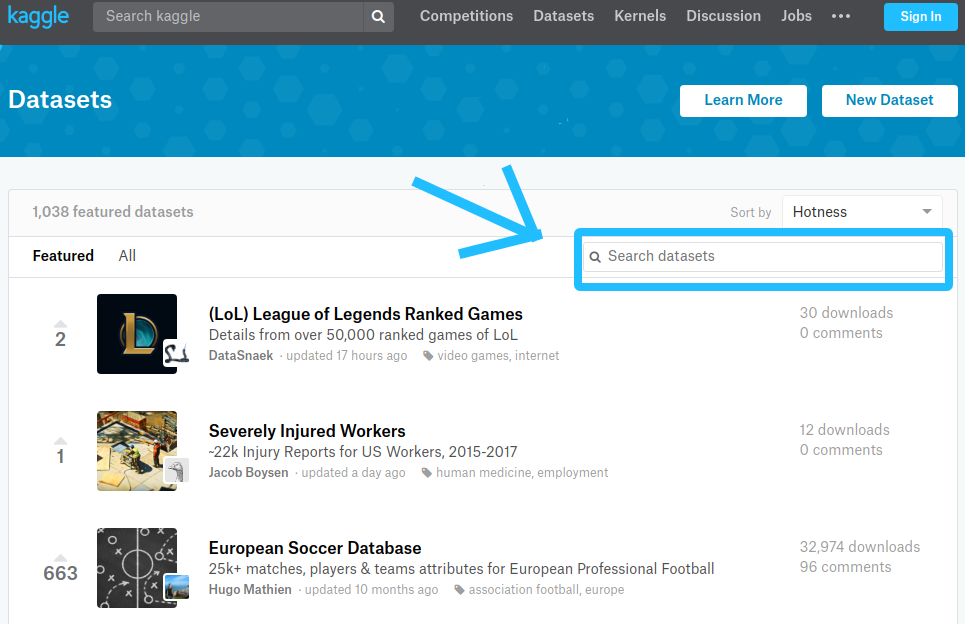
▌搜索提示
Kaggle 的搜索支持一些额外的搜索语法。这意味着您可以使用以下修改来更准确地进行搜索。
“”:将搜索文本放在双引号(“”)中将搜索引号中的确切短语。“巧克力蛋糕” 将返回关于巧克力蛋糕的结果,但不包括巧克力棒或红色天鹅绒蛋糕。
+:在两个单词之间加上一个(+),中间没有空格,将返回具有第一个词和第二个词的搜索结果。“巧克力 + 蛋糕” 将返回巧克力和蛋糕的结果,但它们不必一起同时出现。
|:在两个单词之间放置一个(|)将返回结果中包含第一项或第二项。“蛋糕 |巧 克力” 将返回关于蛋糕或巧克力的结果。
*:如果您要查找多种拼写的内容,可以使用星号(*)表示 “此处有任何字符”。“choc *” 将返回以 “choc” 开头的结果,如 “choclate”,“chocked” 或 “chockablock”。
-:将减号(-)放在单词前面会返回不包含该单词的结果。“蛋糕 - 巧克力” 将返回不包含 “巧克力” 一词的蛋糕的结果。
▌在搜索结果中找到特定内容
如果您的搜索有很多结果,在搜索结果页面中使用浏览器的 “在页面查找” 功能返回有时会有所帮助。
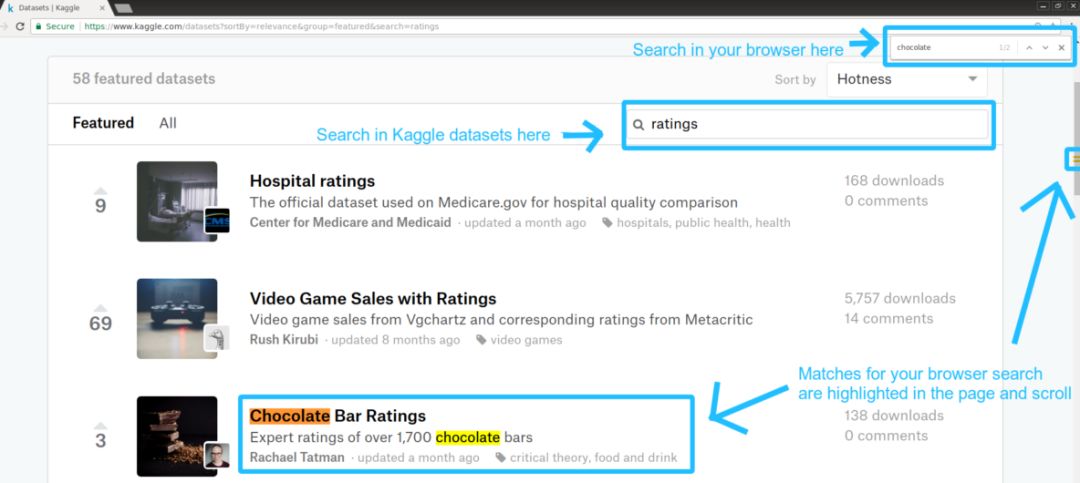
▌排序结果
还可以用不同的方式对搜索结果进行排序:
热度:这是结果排序的默认方式。热度由许多因素决定,包括整体受欢迎程度以及某段时间内活动增加。
投票数最多:根据他们收到的最高票数排序。
最近更新[我的推荐]:根据最近更新的结果(创建或添加新版本)对结果进行排序。这是我个人最喜欢的排序搜索结果的方式:其他人更可能提出流行的,较旧的数据集。我更喜欢看到较新的数据集。除其他优点之外,我发现最近更新数据集的数据集上传者更可能对问题做出回应并对内核发表评论。
最近活动:根据最近任何人与数据集进行交互的情况对结果进行排序,包括评论,启动或运行内核。
相关性:根据它们对查询的相关程度对结果进行排序。

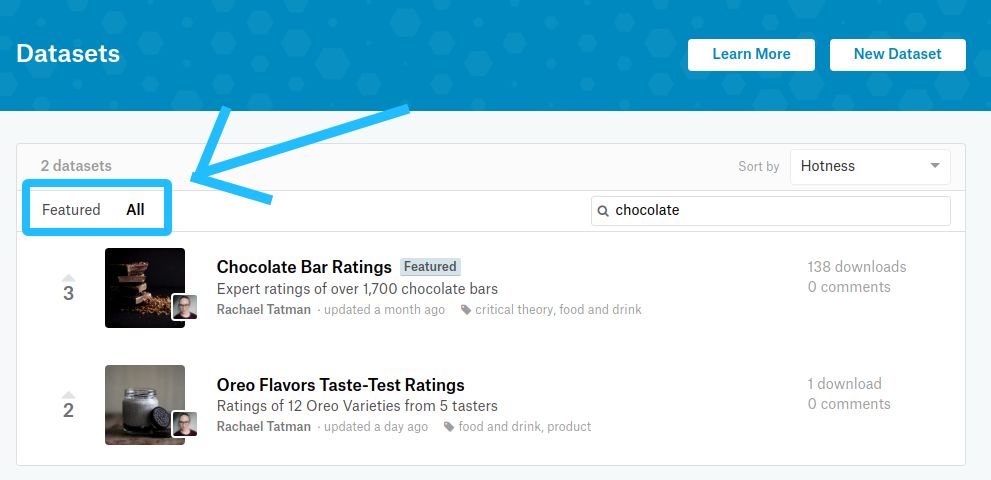
▌特色 VS. 所有 数据集
默认情况下,只在数据集页面上显示 “Featured” 数据集。该数据集是由 Kaggle团队成员精选的。特色数据集应该记录完整,进行过数据清洗并且可以随时使用。但是,并非所有数据集都具有特征,并且还有几个高质量数据集可能尚未提供。如果您希望看到所有数据集,而不仅仅是那些已被选为特色的数据集,您可以通过单击 “All” 一 词从 “Featured” 选项卡切换到 “All” 选项卡来执行此操作。您还将看到精选数据集,这些数据集将通过标题旁灰色 “Featured” 标记进行区分。
▌数据集标签
另一种查找数据集的方法是使用标签(一个相对较新的功能)。您可以通过两种方式搜索特定标签。首先是通过点击数据集列表中的标签或数据集页面上的标签。这将返回具有匹配标签的数据集列表。第二个是在搜索框中搜索标签。您可以通过添加 “tag” 来完成此操作,然后在单引号中添加标签的名称。如果标签中有空格,请包含它们。
标签:'食物和饮料':搜索标签为“食物和饮料”的数据集
标签:'internet':搜索标签为“internet”的数据集
数量众多的标签涵盖了数据发布者用于使数据更容易被发现的各种主题。目前,用户无法添加自己的单独标签。建议点击标签以了解更多有关标签的信息,而不是使用文本搜索并试图猜测某个标签是否存在。

▌页面顶部搜索栏进行搜索
当知道某些数据集已经存在,可以在 Kaggle 网页顶部的搜索栏进行搜索,这是一个方便的捷径,但对于深入搜索,个人偏好还是喜欢在数据集页面内进行搜索

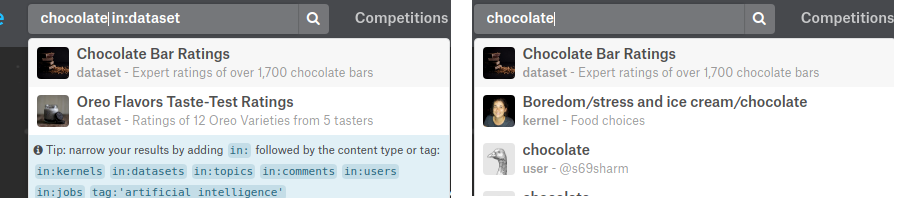
在右侧,可以看到当搜索 “巧克力“ 时,在数据集的最佳结果都是数据集。
在左边,可以看到,当搜索 “巧克力” 时,显示结果依次是:数据集,内核和用户。
以上是关于 Kaggle 数据集的搜索 Tips,如果此时您需要使用特定类型的数据,可以上传您的数据,也为这项艰难伟大的工程贡献一份力量。
-
数据集
+关注
关注
4文章
1208浏览量
24710 -
ai技术
+关注
关注
1文章
1276浏览量
24329
原文标题:如何在Kaggle上受到万人敬仰?
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Kaggle机器学习/数据科学现状调查


谷歌的Dataset Search开放至今,为什么还搜不到我的数据集?
是否在没有扩展指令集的情况下乘以16x16u的汇编程序例程?
BI分享秀——高度开放的数据分析经验共享
HiSpark AI Camera HarmonyOS :3.深度学习探索[一] :鱼脸识别&资料整理与数据共享
Kaggle利于数据科学领域新手学习的几点特征,并带你学习ML相关知识
Kaggle创始人Goldbloom:我们是这样做数据科学竞赛的
最全自动驾驶数据集分享系列一:目标检测数据集






 工商网监
工商网监
评论