 建立一个源于StackExchange的新数据集
建立一个源于StackExchange的新数据集
ACL、EMNLP、NAACL和COLING是NLP领域的四大国际顶会,其中ACL(Annual Meeting of the Association for Computational Linguistics)一直以受关注度更广、论文投递数量多著称。7月15日至20日,第56届年度ACL会议将在澳大利亚墨尔本举办,辛苦码论文的你,准备好了吗?
作为顶会,评选“最佳论文”和“终身成就奖”几乎已经是一项“标配”,ACL也不例外。往年会议通常会在正会上宣布获奖论文/嘉宾,但今年主办单位计算语言学协会却一反常态,在会议前一个月就提前放出了“最佳论文”的评选结果——三篇“最佳长论文”和两篇“最佳短论文”。
Best Long Papers

Best Short Papers

虽然Finding syntax in human encephalography with beam search(用集束搜索在人体脑电图中寻找语法)这篇论文从标题上看起来似乎更具吸引力,但考虑到这5篇论文中只公开了2、3两篇长论文,因此论智在这里只能简要介绍这两篇的内容。如果读者有条件看到会场海报,欢迎随时分享。
论文2:Learning to Ask Good Questions

询问是沟通的基础,如果一台机器连提问都不会,那它也绝对做不到高效地和人类沟通。在日常交流中,提问的主要目标是进一步澄清问题,填补信息空白,如当用户在论坛上向机器人询问Ubuntu操作系统使用问题时,为了筛选原因,机器人会根据条件产生几个提问选项:
(a) 您的系统是哪个版本的?
(b) 您的无线网卡有哪些功能?
(c) 您是在64位操作系统上运行的吗?
在这种情况下,机器人不该问(b),因为这是个无效问题;它也不该选(c),因为这个问题的答案面太狭窄了,如果用户的回复是“不是”“不知道”,这也成了个无效问题。所以这三个选项中唯一符合人类风格的只有(a)。
本文主要做了两方面工作,一是构建了一个新型神经网络模型,它能基于获得完美信息的期望值为问题排序;二是建立了一个源于StackExchange的新数据集,它是模型的学习基础。
新型神经网络模型
这个神经模型的灵感来自完全信息期望值(EVPI),即拥有此随机事件的完全信息时的最大期望值与未拥有此随机事件完全信息时的最大期望值之差。当然这里不用算最大,通俗来讲,本文关注的是如果我们对Ubuntu操作问题有一个已知信息X,那X的用处到底有多大?
因为现在没有这个X,所以我们要先找出所有可能的X,并根据似然值加权计算。在提问场景中,对于模型的给定问题qi(前提是能回答),用户可能有A个可能的回答;对于每个可能的回答aj∈A,模型有概率从中抽取信息,能为得出最终答案提供作用。因此qi的期望值是:

其中,
p是用户发表的提问帖;
qi是候选问题集Q中的一个可能的问题;
aj是针对Q的候选回答集A里的一个答案;
P[aj|p, qi]计算了对于帖子p和提问qi,模型获得回答aj的概率;
U(p+aj)是微观经济学中常见的效用函数,用来描述获得答案aj后,它对帖子p的信息补充程度;
下图展示了模型在测试期间的逻辑:

给定一个帖子p,模型先检索10个类似p的帖子,并生成相应的问题集Q和答案集A。然后输入p和提问qi,获得神经网络的输出,也就是回答表征F(p, qi),计算P[aj|F(p, qi)]和P[aj|p, qi]的接近程度。之后,用U(p+aj)计算把回答改成aj后,p的信息补充提升效果。最后,再根据这个期望效果对问题集Q里的问题一一排序。
看到这里,这个模型要解决的问题就只剩下两个了:
概率分布P[aj|p, qi];
效用函数U(p+aj)。
那么它们背后的原理是什么呢?考虑到篇幅有限,小编这里不再展开介绍了,如果好奇,请大家去读原文——结构清晰美观,强烈推荐。
新数据集
关于这个数据集,内容不多。它的原型是StackExchange上的评论数据,共77,097条内容。论文作者围绕【帖子】【问题】【答案】三个内容创建了一个数据集,其中帖子都是未经编辑的原帖,问题是包含问题的评论,答案是作者对帖子的修改和他对其他留言的评论。
实验结果
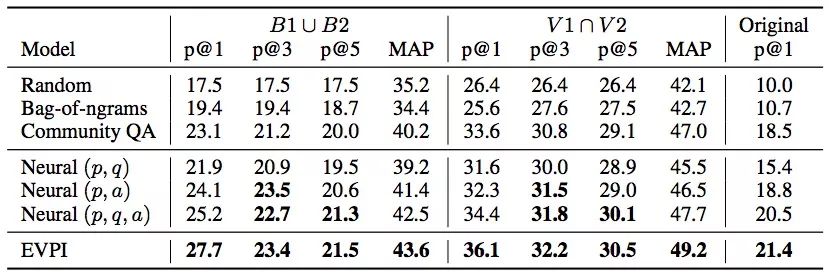
从上图数据可以看出,论文提出的EVPI模型表现不错,它在问题生成任务上非常有前景,能切实帮助机器人在论坛上写出高质量回复。
论文地址:arxiv.org/pdf/1805.04655.pdf
论文3:Let’s do it “again”

这同样是一篇有趣的论文,它在2010年Layth Muthana Khaleel那篇An Analysis of Presupposition Triggers in English Journalistic Texts的基础上再次研究了语用学中的“预设”(Presupposition)问题。
什么是语用预设?
预设一词来自英国著名哲学家Strawson的《逻辑理论导论》:“一个命题S预设P,而且仅当P是S有真值或价值的必要条件。”在语用学中,预设指的是参与对话者在言语交流时都已经知道的信息和假设,同时这些共知信息无需被说出来。它在日常自然对话中随处可见,如:
(1) John is going to the restaurant again.
(2) John has been to the restaurant.
在这个例子中,因为存在一个“again”,所以只有当(2)为真时,(1)的表述才是合理的。表示因为John之前去过一次饭店,所以他能“再”去一次。语用预设和语义预设不同,其中最明显的是它不会因在句子中添加否定而改变,如John is not going to the restaurant again,(2)同样是这句话的预设。
我们把像“again”这样表示预设存在的表达称为预设触发语,它可以是实际的副词、动词,也可以是一段明确的表述。而本文的研究内容则是一个可以检测状语预设触发语的模型。
新数据集
为了训练模型,论文作者也自制了数据集。他们从Penn Treebank(PTB)和English Gigaword第三版子集这两个语料库里提取数据,其中PTB里的22、23两章和Gigaword里的700-760章是测试集,剩余数据里的90%是训练集,最后的10%则被用来提升模型。

对于每个数据集,他们的关注目标是这5个副词:too、again、also、still和yet。由于它们在英语中一般就充当预设触发语,这就相当于整个学习问题被简化成了副词预设触发语是否存在——一个二元分类问题。他们把包含这些副词的句子标记为positive,不包含的则是negative。
学习模型
这是一个引入了注意力机制的模型,从某种程度上来说,它扩展了双向LSTM模型,通过计算每个时间步的隐藏状态之间的相关性,在这些相关性上应用注意力机制。
下图是论文提出的加权池化(WP)神经网络架构:

模型输入序列u = {u1, u2,..., uT}在数据集原始序列基础上经过one-hot编码而来,时间步长为T;
输入网络后,序列中的每个单词ut会嵌入预训练的嵌入矩阵We∈R|V|×d,其中V表示数据集V中的单词数,d则是嵌入空间大小;
嵌入后所得的单词向量xt∈Rd可以简单地用xt= utWe来表示,其中,因为xt可能还包含单词的词性标注,所以其实这个等式还应该加上经one-hot编码的词性标注pt:xt= utWe||pt(||:向量级联运算符)。
我们获得了双向LSTM的输入,之后用LSTM进行编码;
将编码馈送进注意力机制,计算出注意力权重后,对编码状态进行加权平均;
将输出依次连接到全连接层,预测状语预设触发语。
(上述过程中的双向LSTM和注意力机制运算非常常规,请看原文)
实验结果

从结果上看他们的模型还是不错的,但考虑到我们使用的是中文,语用预设更加复杂,英语语境下的这种二元分类方法可能并不适用,但这也为其他语言研究提供了一个比较可行的思路。
-
神经网络
+关注
关注
42文章
4771浏览量
100714 -
数据集
+关注
关注
4文章
1208浏览量
24689
原文标题:ACL 2018:最佳论文评选结果提前出炉
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一个benchmark实现大规模数据集上的OOD检测
中国建立自主可控技术体系的一个机遇
一个完整的MNIST测试集,其中包含60000个测试样本
Facebook AI发布了一个包含编码问题和代码片段答案的数据集
数据科学平台cnvrg.io携手NetApp用深度学习改变MLOps数据集缓存
GitHub上开源了个集众多数据源于一身的爬虫工具箱——InfoSpider
如何用PHP做一个机器学习数据集
建立计算模型来预测一个给定博文的抱怨强度
最全自动驾驶数据集分享系列一:目标检测数据集






 工商网监
工商网监
评论