 谷歌在Kaggle发布了一项地标检索挑战赛
谷歌在Kaggle发布了一项地标检索挑战赛
四个月前,谷歌在Kaggle发布了一项地标检索挑战赛,在这场比赛中,参赛者会得到一些图像,他们需要在所有图像数据集中找到含有给定图像中地标的图片。
图像检索是计算机视觉领域的基础问题,对于包含地标的图像更是非常重要,因为这是用户拍摄的热门对象。本次挑战赛的数据集是世界最大的图像检索数据集,其中有超过一百万张图像,覆盖了全球1.5万个不同景点。
同时,这项挑战赛也是CVPR 2018的地标辨认研讨会的一部分。下面就是本次竞赛排名第一的解决方案,参赛队伍是由anokas带领的团队,论智对其进行了编译。
解决方案包括两个主要元素:
首先,创建一个高性能的全局描述符(global descriptor),它可以将数据库中的图像用奇异向量表示;
然后,创建一个高效的框架,能将这些向量和最可能的图片联系起来,最后提交到积分榜上。
下面是总体框架的流程图,其中每一步应用后都有对应的LB分数。
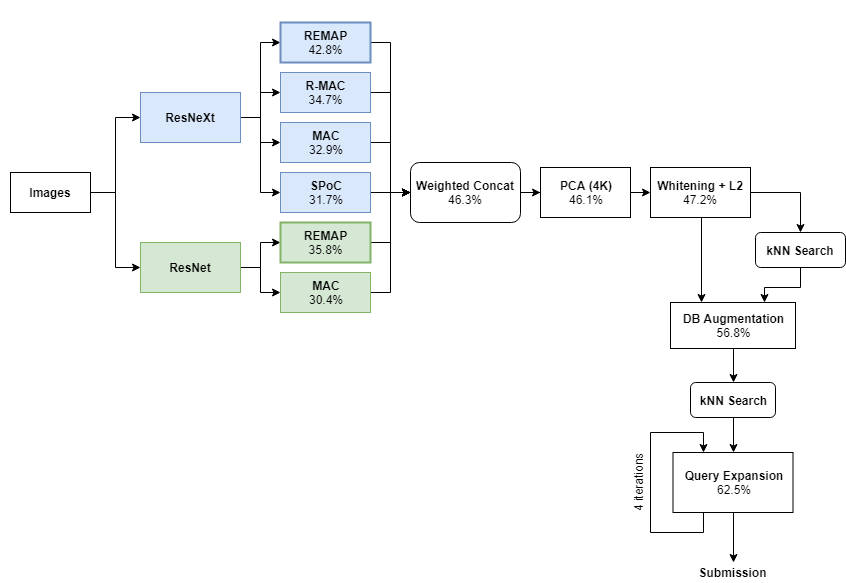
注:下文中所有分数都以百分数表示,即62.5%=0.625
方案详细讲解
全局描述符(Global Descriptors)
我们的方案中最主要的部分就是几个全局描述符,这些向量描述了图片的全部内容。我们从两个预训练的CNN模型开始(ResNet和ResNeXt),并用四种目前最先进的集结方法(aggregation methods)生成全局描述符。下面是四种集结方法各自的细节以及它们“原始”的表现性能(也就是没有进行检索词扩展和数据库扩展):
基于区域熵的多层抽象池化(REMAP)[42.8% mAP]:我们之前设计的一个全局描述符聚合了不同CNN层的深度特征,之后经过训练可以表示多个水平的可视化抽象对象。我们将在之后的CVPR研讨会上进一步展示REMAP的细节架构。
最大卷积激活值(MAC)[32.9% mAP]:MAC描述符将每个CNN的最后一层卷积过滤的最大局部回应进行编码。在它的架构中,ResNeXt的最后一个卷积层后面有一个最大池化层、L2-正则化层和PCA+白化层。
卷积的池化和(SPoC)[31.7% mAP]:在SPoC这一过程中,ResNeXt的最后一个卷积层后接池化和层、L2-正则化层和PCA+白化层。
卷积的区域最大激活值(RMAC)[34.7% mAP]:在RMAC中,ResNeXt最后的卷积特征是在多个规模重叠区域中进行的最大池化。这些区域同样是基于有L2-正则化层和PCA+白化层的描述符。最后把所有描述符汇总到一个单一的描述符中。
基础的CNN网络(ResNet和ResNeXt)是在ImageNet上进行的训练,之后再一个地标数据集的子集中进行调整。该子集来自Babenko等人的研究成果,其中包括大约12万张图片和650个著名景点。
这一数据集中的图像最初是在图片搜索引擎中用文字搜到的,没有经过检验,所以其中可能含有很多不相关的图片,这需要我们过滤掉。删除图片的过程是半自动的,利用带有密集SIFT特征的Hessian-affine检测器以及RVD-W描述符进行聚合。处理完图像后,还剩下25000张左右的图片,都属于一种地标,我们想用它对模型进行调整。
我们没有用其他类似竞赛中的数据集作为训练数据,因为我们想看看在新的数据集下,我们的方案生成的效果如何。
合并描述符
通过用上述方法训练的六个全局描述符合并,就得到了最终的全局描述符(括号中的是LB分数):
ResNeXt+REMAP(42.8%)
ResNeXt+RMAC(34.7%)
ResNeXt+MAC(32.9%)
ResNeXt+SPoC(31.7%)
ResNet+REMAP(35.8%)
ResNet+MAC(30.4%)
接着我们将每个描述符缩放到固定的L2 norm上,为每个描述符分配权重,按以下方式连接描述符:
XG = [2× ResNeXt+REMAP; 1.5× ResNeXt+RMAC; 1.5× ResNeXt+MAC; 1.5× ResNeXt+SPoC; ResNet+MAC; ResNet+REMAP]
权重的选择是点对点的,以反映每种方法相应的性能。之后,我们用PCA将描述符的维度降到4K,同时应用白化,让所有维度的方差相同。虽然PCA和白化只能改善一小部分,但是它将查询扩展的结果提升了几个百分点。
最近邻搜索
创建好描述符后,每张图片都由一个4096维的描述符表示。接下来,我们用复杂的k-最近邻搜索找到每张图前2500个近邻和L2距离。这一阶段提交每张图片的前100个最近邻得到了47.2%的分数。
这一步骤使用优化过的NumPy代码实现,用了2小时对每个1.2M的图片找出了前2500个最近邻。
数据库增强
接下来要做的是数据库增强(DBA),即把数据库中每张图片的描述符换成它本身和前10个最近邻的加权结合。目的就是利用它们近邻的特征提高图像表示的质量。更准确的是,我们进行描述符的加权求和,其中权重按以下代码计算:
weights = logspace(0, -1.5, 10)
有趣的是,在其他数据集上我们发现只要用大于两个近邻进行增强就会让分数下降,但10个近邻对数据集增强和图片是最好的。
需要注意的是,DBA是整个过程中添加的最后一步,虽然它能让分数得到大幅提升,但是将它和查询扩展结合起来时,提升只有1%—2%。我们认为这是由于数据库扩展与查询扩展方法的第一步很相似。
查询扩展
查询扩展是图像检索问题中的基础技术,通常对模型的性能有很大提升。它工作的原理是:如果A与B匹配,B与C匹配,那么A与C匹配。我们可以在下面的实例中看到这种原理的优势,图中三个区域相互重叠:
在这一案例中,查询扩张系统可以将A和C联系起来,判断它们属于同一场景,即使它们全局描述符可能不相符。这在一些光线不同或视角不同的图像中也很有用。
在这次比赛中,我们设计了一种新的、快速的技术用于查询扩展,它可以通过递归运行捕捉图像之间的长距离连接。这种特点非常适合这一问题,因为含有某个地标的图像有很多,只有一张图像才能成为查询结果,其他的只能归为top 100的结果中。
第一次迭代后,查询扩展提升了约11%,进行了30分钟的递归运行后,提升了14%,加入数据增强后这一结果有所下降。
简化模型
在产品级机器学习环境中,由于收益递减原则,几乎不会使用大规模的多模型集成。通常使用较小的子集就能达到理想性能。我们想得到原来方案的简化版本,只需要不到12个小时,仅仅用ResNeXt-REMAP和查询扩展就能得到56%—57%的分数。

不足之处
局部描述符:这可能是我们在比赛中最意想不到的事。我们试了好几种基于多种局部描述符的方法,包括使用和不使用几何验证的方法,例如用它对我们的结果重新排名,或者用它从上到下浏览几千个全局近邻,找找有没有遗漏掉的局部匹配。不知道其他队伍使用局部描述符的情况如何,也许是基于CNN的全局描述符太好用了以至于局部的时代终结了?
处理旋转图像:在数据集中我们发现很多图片都是旋转的。我们用好几种方法处理这个问题,例如在k-最近邻方法中比较旋转和不旋转的描述符,并为每组图像进行最近匹配。但是分数依然没有变化。有可能是因为这个数据集有太多干扰项了,误报率太高,即使真正匹配对整体分数的影响也不大。
集成:我们试了好几种方法将不同模型和方法的结果结合起来,例如排序平均和交错预测等,然而成效不大。似乎早期将模型结合比结束时结合要好一些。
-
图像检索
+关注
关注
0文章
28浏览量
8036 -
计算机视觉
+关注
关注
8文章
1698浏览量
45965 -
数据集
+关注
关注
4文章
1208浏览量
24683
原文标题:Kaggle地标图片检索挑战赛冠军方案讲解
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
芯华章持续助力EDA精英挑战赛
EDA精英挑战赛赛果公布!思尔芯“战队”薪火相承斩获“麒麟杯”

e络盟社区携手恩智浦发起智能空间楼宇自动化挑战赛

2024年ICPC与华为挑战赛冠军杯圆满落幕
PI助力aCentauri车队在太阳能车挑战赛中大放异彩
50万奖金池!开放原子大赛——第二届OpenHarmony创新应用挑战赛正式启动
NVIDIA为AI城市挑战赛构建合成数据集
AI4Science黑客松光子计算挑战赛成功举办
思尔芯赛题正式发布,邀你共战EDA精英挑战赛!
开放原子开源大赛OpenHarmony智能化应用生态挑战赛决赛路成功举办
NVIDIA和谷歌云宣布开展一项新的合作,加速AI开发

思尔芯助力中国EDA创新,精英挑战赛评选揭晓
第五届EDA挑战赛赛果公布!思尔芯“战队”成绩斐然





 工商网监
工商网监
评论