 一种针对深度强化学习运动任务的自动环境
一种针对深度强化学习运动任务的自动环境
编者按:通常我们看到的深度强化学习的实现都是在模拟环境中,例如OpenAI的Gym。但这次,迪士尼研究院的科学家们将DL应用到了模块化机器人上,并创建了一个自动学习环境,可以直接将控制策略应用到实体机器人上。论智将原论文编译如下。
在这篇论文中,迪士尼研究院的研究者们提出了一种自动学习环境,直接在硬件(模块化有腿机器人)上建立控制策略。这一环境通过计算奖励促进了强化学习过程,计算过程是利用基于视觉的追踪系统和将机器人从新放回原位的重置系统进行的。我们应用了两种先进的深度学习算法——Trust Region Policy Optimization(TRPO)和Deep Deterministic Policy Gradient(DDPG),这两种算法可以训练神经网络做简单的前进或者爬行动作。利用搭建好的环境,我们展示了上述两种算法都能在高度随机的硬件和环境条件下有效学习简单的运动策略。之后我们将这种学习迁移到了多腿机器人上。
问题概述
自然界中,很多生物都能根据环境做出适应性动作。在最近一项对盲蜘蛛(也称长脚蜘蛛)的研究发现,当它们遇到敌人时,会自动伸出脚,过一段时间后又会恢复行走速度和转向控制。即使不会自动变化,很多生物也会在改变身体结构之后调整动作姿态,这都是长期学习适应的结果。那么我们能否从借鉴生物将这种学习运动的技巧应用到机器人身上呢?
之前有科学家依赖先验知识手动为机器人设计合适的步态,虽然经验丰富的工程师能让机器人随意移动,但在可以组装的机器人身上这种方法就不切实际了。
最近,研究者又表示可以用深度强化学习技术提高采样策略,从而在虚拟环境中完成很多任务,例如游泳、跳跃、行走或跑步。但是对于真实的有腿机器人来说,深度强化学习技术却很少应用,因为在我们的经验中,即使一个简单的爬行动作对真实硬件来说也是很困难的,因为涉及到多变的未经模式化的动作。
在这篇论文中,迪士尼研究院的科学家们提出了一种针对深度强化学习运动任务的自动环境,其中包括一个视觉追踪器和一个重置机制。在这一环境之上,科学家们在可组装的有腿机器人上应用了两种学习算法——TRPO和DDPG。之后训练神经网络策略在单腿机器人和多腿机器人上的运动,结果证明算法能在硬件上有效地学习控制策略。
实验装置说明
实验所用机器人如图所示:
这类似蜘蛛的机器人是可以灵活拆卸的,中间的本体是一个六边形的形状,每一面都可以利用磁铁吸附上一条“机械腿”,不过在实验中研究人员最多只用了三条腿。除此之外,这三条腿也各不相同,分别可以实现不同的前进方向。
实验的环境布局如下图所示:
环境主要由两部分组成:视觉追踪系统和让机器人复位的重置装置。视觉系统是用消费级摄像头实现的,距离平面约90cm,它追踪的是机器人身上的绿色和红色两个点,从而重现全局的位置并为机器人导航。
重置装置是全自动学习环境中的重要组成部分。我们用只有一个自由度的杠杆结构即可将机器人拉回到初始位置。该装置距离机器人25cm,两个1.5m长的线分别连接机器人本体上的两点。
设置完毕后,研究人员将控制问题用部分可观察马尔科夫决策过程(POMDP)表示,它可以用无法观察到的状态变量来解释决策问题。具体的数学公式可参考原论文。
学习算法
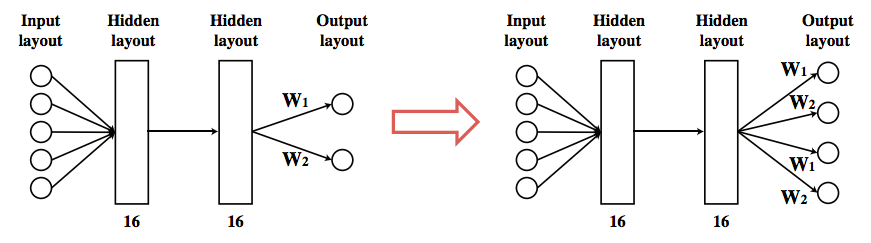
模型的策略用一个神经网络表示,该网络由两个完全连接的隐藏层组成,每层有16个tanh活动神经元。当在单腿机器人上训练好策略,我们也许能将所学到的知识转移到多腿机器人上。假设所有的腿都有同样的接头形状,我们可以通过复制输出神经元和对应的链接进行多腿运动。
实验结果
在实验中,研究人员主要研究了两个问题:
目前最先进的深度强化学习算法能否直接在硬件上训练策略?
我们能否通过迁移策略将学习转化到复杂场景中?
科学家们首先训练了一条腿的机器人,最终动作类似于爬行。A、B、C三种腿型的结果如图:
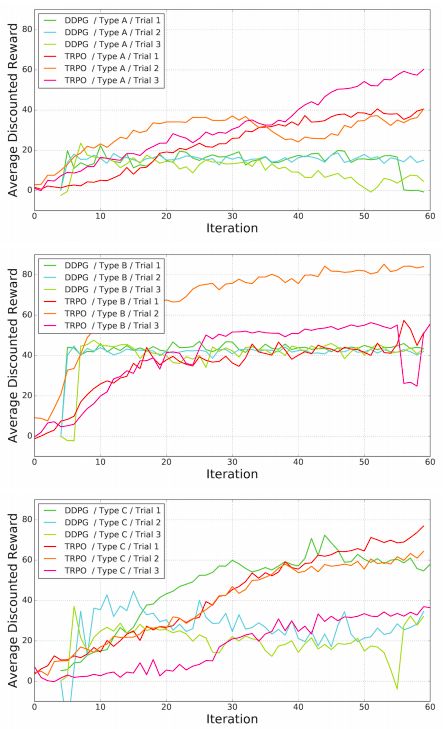
可以看到,TRPO和DDPG两种算法都能成功地在硬件上进行训练,同时表现得要比其他手动设计的步态优秀。
接下来科学家测试了学习框架在多腿运动上的表现。首先是用两个Type B的腿进行爬行动作。下图是两种算法在迁移学习和无迁移下的表现:
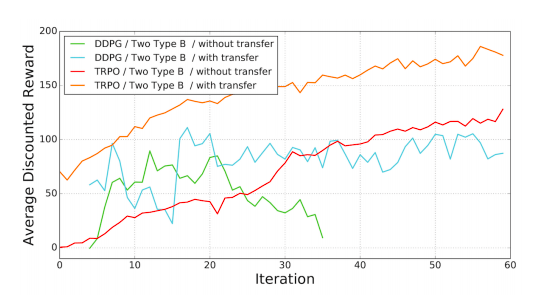
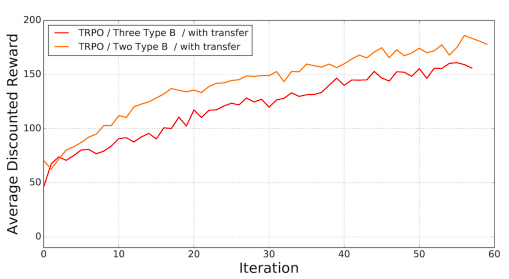
结果符合预期,迁移学习能作为一个很好地初始解决政策。接着研究人员又测试了三条腿前进的表现,结果显示中间的那条腿作用并不大。
结语
由于传感器能力有限,研究者在这项实验中仅对简单的开环爬行运动进行了实验。如果有更复杂的控制器和奖励的话,也许会得到更复杂的行为。例如,可以用基于IMU的反馈控制器训练机器人走路或跑步。或者可以使用深度相机收集机器人的高度,当它们从爬行转变成走路时给予奖励。
除此之外,虽然研究者展示了迁移学习在初始策略上的重要作用,但都是应用在相同种类的腿上,动作也都类似。未来,他们计划将动作分解成不同难度水平的,应用于不同任务上。
自动学习过程有时会生成意想不到的行为。例如,在做空翻动作时,追踪系统会出现bug,因为机器人会挡住标记从而对其位置进行误判。虽然这不会对这次实验中的机器人造成损坏,但是对于体型庞大的机器人却是致命的。所以,想在硬件系统上进行直接学习可能也需要传统算法的帮助,保证机器人的安全,而不是一位追求采样的高效。
-
机器人
+关注
关注
212文章
28887浏览量
209513 -
神经网络
+关注
关注
42文章
4789浏览量
101528 -
深度学习
+关注
关注
73文章
5527浏览量
121833
原文标题:迪士尼创建新框架,将深度学习直接应用到实体机器人上
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是深度强化学习?深度强化学习算法应用分析

深度学习DeepLearning实战
将深度学习和强化学习相结合的深度强化学习DRL
强化学习环境研究,智能体玩游戏为什么厉害
如何使用深度强化学习进行机械臂视觉抓取控制的优化方法概述
一种基于多智能体协同强化学习的多目标追踪方法
基于深度强化学习仿真集成的压边力控制模型
《自动化学报》—多Agent深度强化学习综述






 工商网监
工商网监
评论