 2018年的“最佳论文奖”和“最佳论文提名奖”的论文分享
2018年的“最佳论文奖”和“最佳论文提名奖”的论文分享
机器学习顶会ICML 2018将于7月10日在瑞典斯德哥尔摩举办,今年会议共收到2473篇投递论文,比去年的1676篇提高47.6%,增幅显著。最终入围的论文一共621篇,接受率25%,和去年的26%基本持平。
今天,会议官网公布了2018年的“最佳论文奖”和“最佳论文提名奖”:
最佳论文奖(Best Paper Awards)
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Anish Athalye (MIT), Nicholas Carlini (UCB), David Wagner(UCB)
Delayed Impact of Fair Machine Learning
Lydia Liu, Sarah Dean, Esther Rolf, Max Simchowitz, Moritz Hardt (全员UCB)
最佳论文提名奖(Best Paper Runner Up Awards)
The Mechanics of n-Player Differentiable Games
David Balduzzi (DeepMind), Sebastien Racaniere (DeepMind), James Martens (DeepMind), Jakob Foerster (Oxford), Karl Tuyls (DeepMind), Thore Graepel (DeepMind)
Near Optimal Frequent Directions for Sketching Dense and Sparse Matrices
Zengfeng Huang (复旦大学)
Fairness Without Demographics in Repeated Loss Minimization
Tatsunori Hashimoto (Stanford), Megha Srivastava (Stanford), Hongseok Namkoong (Stanford), Percy Liang (Stanford)
其中,复旦大学的论文Near Optimal Frequent Directions for Sketching Dense and Sparse Matrices十分引人注目,这篇斩获“最佳提名奖”的论文由大数据学院副教授黄增峰独立完成,研究的是流模型(streaming model)中的协方差情况。文章提出了一种新型空间优化算法,把流模型运行时间缩短到极致。
下面是对两篇最佳论文的编译概述:
最佳论文:Obfuscated Gradients Give a False Sense of Security

GitHub:github.com/anishathalye/obfuscated-gradients
基于神经网络的分类器通常被用于图像分类,它们的水平通常接近人类。但是,这些相似的神经网络特别容易受到对抗样本和细微的干扰输入的影响。下图是一个典型的对抗样本,对原图增加一些肉眼看不见的扰动后,InceptionV3分类器把猫分类成了鳄梨酱。根据Szegedy等人2013年的研究显示,这种“愚蠢的图像”仅用梯度下降法就能合成,这类发现为物体检测研究敲响了警钟。
在这篇论文中,作者评估了ICLR 2018接受的9篇论文,并测试了它们面对对抗样本的稳健性。实验结果证实,在8篇有关对抗样本的防御机制的论文中,有7篇的防御机制都抵挡不住论文提出的新型攻击技术,防御水平有限。
简介
虽然人们对对抗样本已经有了更多了解,甚至找到了抵御攻击的方法,但却还没有一个彻底的解决方案能让神经网络不受对抗样本的干扰。据我们所知,目前发表的对抗样本防御系统在强大的优化攻击面前同样非常脆弱
经过研究,我们认为防御系统能在受到迭代攻击时仍然保持较强的鲁棒性的共同原因是“混淆梯度”(obfuscated gradients)的存在。没有良好的梯度信号,基于优化的方法就不能成功。我们定义了三种混淆梯度——破碎梯度(shattered gradients)、随机梯度(stochastic gradients)以及消失/爆炸梯度(vanishing/exploding gradients),同时针对这三种现象分别提出了解决方案。
混淆梯度
上文中我们提到了防御机制造成混淆梯度的三种方式,接下来让我们一一介绍各种情况。
破碎梯度(shattered gradients)是当防御不可微分时产生的,它会引起数值不稳定或者导致真正的梯度信号发生错误。造成梯度破碎的防御措施往往是通过引入可微分的操作无意产生的,但实际上剃度并不指向最大化分类损失的方向。
随机梯度(stochastic gradients)是由随机防御引起的,其中要么网络本身是随机的,要么输入的内容是随机的。多次评估梯度会得到不同的结果,这可能会产生单步方法(single-step methods)以及优化方法,即利用单个随机样本错误地估计真正的梯度方向,并且无法收敛到随机分类器的最小值。
爆炸和消失梯度(Exploding & Vanishing gradients)通常是由多次迭代的神经网络评估构成的防御造成的。因为这可以看作是一个非常深的神经网络评估,很容易看出为什么梯度会爆炸或消失。
找到混淆梯度(identifying obfuscated gradients)
在一些情况下,防御机制包含着不可微的操作,但是在其他情况下,可能不会立即找到。以下是几种检查混淆机制的几种方法,也许不一定适用于每种情况,但是我们发现每个含有混淆梯度的防御机制都至少有一个无法通过的测试。
检查迭代攻击比单步方法更好。在白盒中应用基于优化的迭代攻击应明显强于单步攻击,并且表现得必须相当好。如果单步方法的性能优于多不方法,那么多步攻击有可能陷入局部最小值的最优搜索中。
证明白盒攻击比黑盒效果好。黑盒威胁模型是白盒威胁模型的子集,所以百合设置中的攻击应该表现得更好。然而,如果防御正在混淆梯度,那么不需要梯度信号的黑盒通常比白盒攻击的效果好。
确保攻击达到100%的成功。如果对图片无限进行干扰,任何分类器应该对对抗样本有0%的鲁棒性(只要分类器不是一个常数函数)。如果攻击没有达到100%的成功率,这表明防御机制正在以微妙的方式打败攻击,实际上可能不会增加鲁棒性。
暴力随机抽样。识别混淆梯度的最后一个简单方法是在每张图像的某个ε-球内暴力搜索对抗样本。如果用优化方法进行的随机搜索没有找到对抗样本,防御很可能是混淆梯度。
攻击混淆梯度的技术
既然已经找到了混淆梯度,那么应该用什么方法解除样本的防御系统呢?通过基于优化的方法产生对抗样本的例子需要通过反向传播获取有用的梯度。因此,许多防御有意或无意地造成梯度下降,最终失败。我们讨论了一些技术,能解决混淆梯度的问题。
后向传递可微近似(Backward Pass Differentiable Approximation):破碎的梯度可能是无意产生的(如数值不稳定)或者有意产生的(使用不可微分的操作)。为了攻击那些梯度不易获得的防御,我们引入后向传递可微近似(BPDA)的技术。
对随机性求导:使用随机分类器之前对输入使用随机变换时会产生随机梯度,当对采用这些技术的防御系统进行基于优化的攻击时,有必要估计随机函数的梯度。
重新调整参数:针对梯度消失或爆炸,我们通过重新调整参数来解决。
案例研究:ICLR 2018中的防御机制
为了了解混淆梯度的影响,我们研究了ICLR 2018接收的论文中研究白盒威胁模型中鲁棒性(稳健性)的成果。我们发现除了一篇之外,其他论文中的防御机制都依赖于这一现象来保证对抗样本的鲁棒性,而且我们的技术可以使那些依赖于混淆梯度的技术失效。下表总结了实验结果:

虽然Madry等人的方法不会生成混淆梯度的三种情况。但是,我们发现了这种方法的两个重要特征:
对抗性在训练在ImageNet上有困难;
只在l∞对抗样本上进行的训练只在其他干扰的度量下对对抗样本提供有限的鲁棒性。
除此之外,其他七篇论文或多或少地都依赖于混淆梯度。
最佳论文:Delayed Impact of Fair Machine Learning

机器学习的基础理念之一是用训练减少误差,但这类系统通常会因为敏感特征(如种族和性别)产生歧视行为。其中的一个原因可能是数据中存在偏见,比如在贷款、招聘、刑事司法和广告等应用领域中,机器学习系统会因为学习了存在于数据中的历史偏见,对现实中的弱势群体造成伤害,因而受到批评。
在这篇论文中,我们探讨了近期BAIR将机器学习系统决策和长期社会福利目标结合起来的工作。和银行的信用评分系统类似,这些系统通常会生成一个统计个人信息的分数,然后依据这个分数对他们做出决策。我们提出了一种名为“结果曲线”的模型,它为系统的公平性提供了直观的检测手段,下面是以银行贷款为例的说明。
如下图所示,任何一批人在信用评分上都有特定分布。每个圆点代表一个客户,深色的按时还贷,浅色的有违约记录;信用分越高,客户还贷几率越高。

图一 信用评分和还贷分布
通过定义一个阈值,信用评分可被用来执行决策,比如银行会为超过分数阈值的客户发放贷款,而拒绝低于阈值的客户的贷款申请。这种决策规则被称为阈值策略(threshold policy)。
从机器学习角度看,这个分值可以被看作是对客户违约概率的编码。例如,在信用评分为650的群体中,客户愿意按时贷款的比例高达90%,银行就能通过向这批人贷款来预测自己期望获得的利润。同理,信用评分越高,银行利率的预测越准确,风险也越小。

图二 贷款阈值和营收结果
如果没有其他考虑因素,银行总是把利润最大化放在第一位的。就贷款来看,银行的利润取决于它从按时还贷中得到的利息和在拖欠贷款中损失的金额之比。在上图中,这个利息和损失的比率范围是1到-4,由于客户违约带来的损失比客户守约带来的利息更高,银行发放贷款会更谨慎,贷款阈值也更高。我们把这部分信用评分高于贷款阈值的客户比例称为选择率(selection rate)。
结果曲线
贷款决策影响的不只是金融机构,它对个人也有一定影响。如果借款人未能偿还贷款,这类违约事件不仅降低了银行利润,也恶化了借款人信用评分。相反地,如果借款人按时还贷,对人对己这是种双赢的选择。在我们的示例中,借款人信用评分的变化区间是-2到1,-2表示拖欠贷款,1表示已还贷。
阈值策略的结果,也就是客户信用评分预期变化,可以被作为选择率函数中的一个参数。我们把这个函数称为结果曲线(outcome curve)。不同的选择率会导致不同的结果,而这个结果不仅取决于客户还款的可能性(阈值),也取决于银行贷款决策的成本和收益(选择率)。

图三
上图显示的是典型人群的结果曲线。如果一批人中有足够多的人获得了银行贷款,并且能按时还款,这批人的信用评分会增加,这是由银行利润最大化驱动的(实线黄色区域)。如果这时我们开始偏离利润最大化而向更多人发放贷款,这批人的平均信用评分会达到一个最高值,也就是曲线最高点,我们把这个点称为利他最优(altruistic optimum)(蓝色区域)。
我们也可以调整选择率,让平均信用评分保持在低于最高值,但同样可以获得贷款的水平(虚线黄色区域)。因为分数确实是降低了,我们称这里的选择率正在导致相对危害(relative harm)。最后,如果太多借款人没有能力还贷,这批人的信用评分会一起下降(红色区域)。

图四 贷款阈值和结果曲线
不同群体
那么这些给定的阈值策略是怎么影响到不同群体中的个人的呢?信用评分分布不同的两组人会有不同的结果。
设存在两个信用评分分布不同的小组,其中第一组人数少,我们可以认为这个群体是一个历史上处于弱势地位的少数群体。我们把它表示为蓝色,目标是确保银行贷款策略不会对它构成歧视。

图五 不同群体的贷款策略
可以看出,为了公平起见,银行可以为这两个小组划分不同的贷款阈值,但这其实产生了另一种歧视,而且涉嫌违法。
剩下的方法是改进蓝色小组的信用评分分布。正如我们之前提到的,如果不加约束,银行策略肯定会朝着利润最大化发展:计算一个盈亏持平的阈值,超过阈值发放贷款,低于阈值拒绝贷款。事实上,两组的利润最大化阈值(信用评分580)是相同的。
公平标准
对于具有不同分布的小组,它们的结果曲线也不同。作为利润最大化的替代方案,我们可以考虑添加公平性约束(fairness constraints),使小组间的决策相对于某个目标函数相等,从而保护弱势群体。通过结果模型,我们现在可以具体回答这些公平性约束是否真的造成了实际上的积极影响。

图六 用公平性约束模拟贷款决策
在贷款问题中,一个最常见的公平标准是人口平等(demographic parity)。它要求银行以同样的选择率向两个小组提供贷款。根据这一要求,银行将尽可能地继续实现利润最大化。另一个公平标准则是机会均等(equality of opportunity),即使两个组的真实盈利率(true positive rates)相等,要求银行依据每个组按时偿还贷款的客户比例分别制定选择率。
尽管这些公平标准是考虑均衡静态决策的一种自然方式,但他们经常忽略这些策略对人口结果的未来影响。与最大利润相比,人口平等和机会均等都降低了银行利率,同时也没有真正改善蓝色小组的弱势地位。

利润最大化
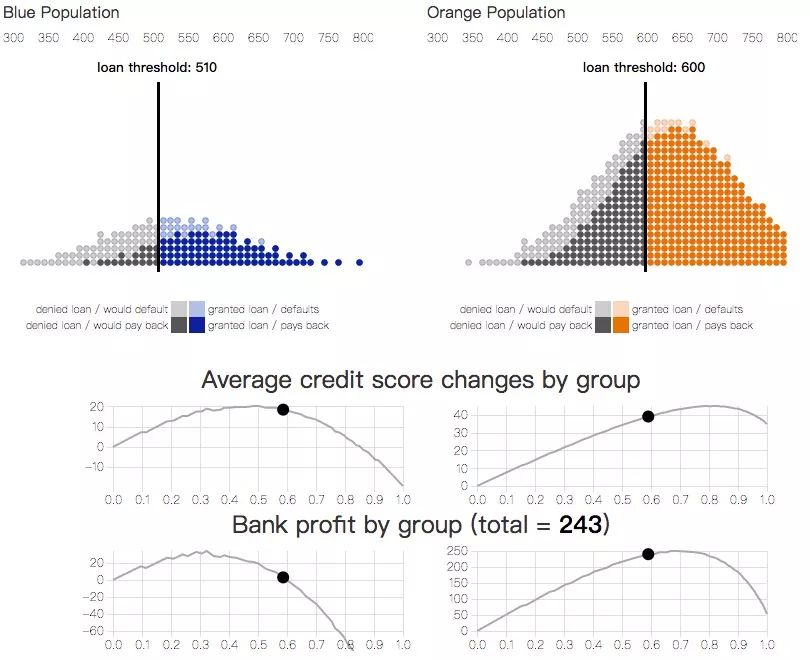
人口平等

机会均等
如果采用公平标准的目标是增加或平衡所有人群的长期福祉,上述图已经表明,有时候公平标准实际上违背了这一目标。换句话说,公平性限制也会减少已经处于不利地位的人群的福利。构建一个准确的模型来预测决策对人口结果的影响可能有助于缓解应用公平标准可能造成的未预料到的危害。
-
神经网络
+关注
关注
42文章
4767浏览量
100668 -
图像分类
+关注
关注
0文章
90浏览量
11914 -
机器学习
+关注
关注
66文章
8397浏览量
132518
原文标题:ICML 2018最佳论文公布,复旦成果入围最佳论文提名奖
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一博科技荣获Cadence用户大会杰出论文奖
ICLR 2019在官网公布了最佳论文奖!

ICLR 2019最佳论文日前揭晓 微软与麻省等获最佳论文奖项
Vishay的IHSR-1616AB-01荣获电子工业奖“年度最佳产品”提名
CVPR 2019最佳论文公布了:来自CMU的辛书冕等人合作的论文获得最佳论文奖
来自清华、中科院、南京等15篇获奖 10篇论文奖5篇提名奖
浙大与电子工程学院发表的研究荣获最佳论文奖
ICLR 2021杰出论文奖出炉 让我们看看前八位优秀论文有哪些
紫光同创荣获“2021中国年度最佳雇主提名奖”
北工大校友Cheng Zhang获SIGGRAPH最佳博士论文奖!

FPL 2023最佳论文奖!

中科驭数联合处理器芯片全国重点实验室获得FPL 2023最佳论文奖!






 工商网监
工商网监
评论