 身体的运动可以通过音乐信号进行计算预测吗?
身体的运动可以通过音乐信号进行计算预测吗?
根据音乐信号预测身体的运动是一个极具挑战性的计算问题。来自Facebook、斯坦福大学和华盛顿大学的研究人员开发了一种基于深度学习的方法,该方法可以将乐器的声音转换成对骨骼关键点的预测,并可以用于制作动画角色。
钢琴家在弹奏钢琴曲时,他们的身体会对音乐产生反应。他们的手指在琴键上敲击,他们挥动手臂在不同的八度音阶上演奏。小提琴演奏者用一只手在琴弦上拉弓,另一只手的手指轻触或拨动琴弦。弓法越快,产生音乐节奏也越快。
一个有趣的问题是:身体的运动可以通过音乐信号进行计算预测吗?这是一个极具挑战性的计算问题。我们需要有一套很好的训练视频,需要能够准确地预测这些视频中的身体姿势,然后建立一个能够找到音乐和身体之间的相关性的算法,以进一步预测运动。
来自Facebook、斯坦福大学和华盛顿大学的研究人员开发了一种基于深度学习的方法,该方法可以将乐器的声音转换成对骨骼关键点的预测,并可以用于制作动画角色。
受唇语预测和视频对象检测启发
人体动力学是很复杂的,尤其是考虑到学习音频相关性所需要的质量。传统上,通过视频序列(而不是音频)来预测人体自然运动的最优方法是采用实验室状态下拍摄的动作捕捉序列。在我们的场景中,我们需要带一位钢琴家到实验室,在他们的手指和身体关节处安装传感器,然后请他们演奏几个小时。
这种方法在实践中很难执行,也不容易推广。如果我们能够利用优秀钢琴家演奏的公开视频,我们就有可能在数据上实现更高程度的多样性。但直到最近,从视频中准确地估计身体姿势才成为可能。今年出现了几种方法,可以让我们从“自然状态下”的数据中学习。
此外,有一些方法显示出预测唇语的显著结果。也就是说,给定一个人说话的音频,他们可以预测出这个人说话时嘴唇的运动。
这两个方向取得的进步启发了我们,我们试图去解决仅仅从音乐中预测身体和手指运动的挑战。这篇论文的目标是探索是否有可能,以及我们是否能从音频中创造出自然和符合逻辑的身体运动。注意,我们没有使用MIDI文件之类的信息,而是试图了解钢琴琴键和音乐之间的关系。我们专注于创造一个能像钢琴家那样运动他的手和手指的角色(avatar)。
我们考虑了两组数据,钢琴和小提琴独奏(如图3)。我们分别收集了这两类音乐的视频,通过视频每一帧里的上半身和手指来处理视频。每一帧共50个关键点,其中21个点表示每只手的手指,8个点表示上半身。
图3:训练数据
除了预测点之外,我们的另一个目标是通过动画形象的方式来可视化这些点,让动画人物根据给定的音频输入自主活动。为了解决这个问题,我们提出两个步骤。首先,构建一个长短期记忆(LSTM)网络,学习音频特征和身体骨架界标(body skeleton landmarks)之间的相关性。其次,我们使用预测的landmark自动给一个动画形象赋予生命。最后的输出是能根据音频输入活动的动画人物。
关键点估计
我们对两种关键点感兴趣:身体和手指。通常情况下,由于相机、灯光和快速运动产生的巨大变化,在自然的视频中估计关键点的估计是具有挑战性的。不过,最近出现了许多方法可以更好地处理自然的视频。
我们获取相对精确的关键点的过程如下:
我们首先通过三个库来运行视频:提供脸部、身体和手的关键点的OpenPose,MaskRCNN,以及人脸识别算法DeepFace。这三个库在基准测试上表现很好,但是在我们的视频中,它们在某些帧上会失败。
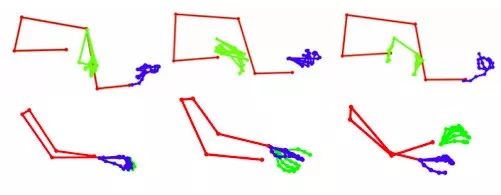
图4:在预处理步骤中自动删除的关键点检测器的失败案例
从音频到身体关键点的预测
我们的目标是学习音频特征和身体运动之间的关联性。为此,我们构建了一个LSTM(长短期记忆)网络。架构如图5所示:
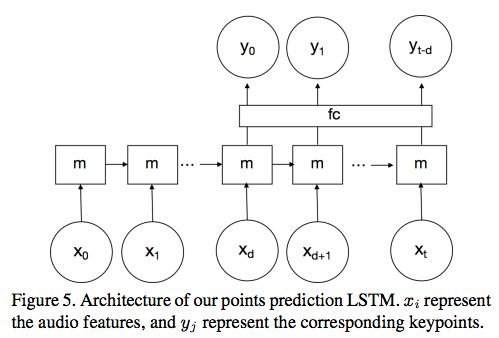
图5:关键点预测LSTM的架构。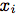 表示音频特征,
表示音频特征,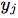 表示相应的关键点。
表示相应的关键点。
我们选择使用具有时间延迟的单向的单层LSTM。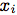 表示在特定时间i的音频MFCC,
表示在特定时间i的音频MFCC,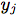 表示身体关键点的PCA系数,m表示memory。我们还添加了一个完全连接层“fc”,发现它可以提高性能。
表示身体关键点的PCA系数,m表示memory。我们还添加了一个完全连接层“fc”,发现它可以提高性能。
我们进行了300 epochs的训练。该网络在Caffe2上实现,并使用ADAM优化器。输入和输出都是通过减去平均值并除以方差而归一化的。
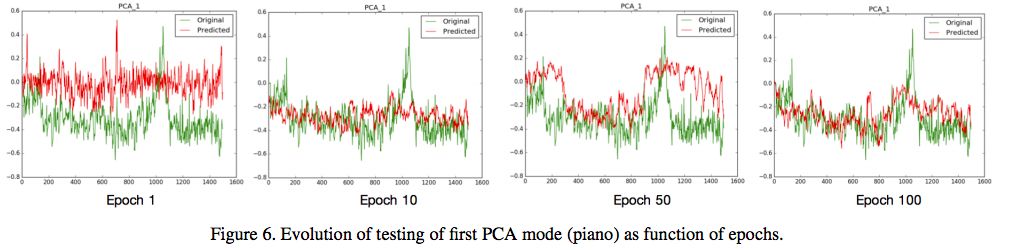
图6:第一个PCA mode(piano)
从身体关键点到动画形象
当身体的关键点预估出来后,我们用一个动画形象来使用这些点。我们使用ARkit构建了一个增强现实应用程序,它可以在手机上实时运行。给定一系列2D预测点和身体的动画化身,动作便被应用到化身上。我们使用的化身是带有人体骨骼装置的3D人体模型。
实验
评估:
我们在网络中尝试了不同的参数选择,并在表1和表2中提供了比较。为了找到最优参数,我们进行了超参数搜索。表中的误差以像素表示,越低越好。
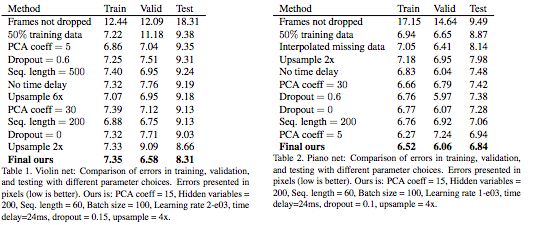
为了获得好的结果,过滤掉训练数据中的所有糟糕的帧(错误的骨架、错误的人体检测、错误的人体识别)是很重要的。可以看到,只要过滤掉坏数据,误差就会显著减少。
通过使用较少的PCA系数,可以更好地适应训练数据,但测试误差大于使用较多的系数。在我们的案例中,使用dropout并不能改善结果。时间延迟有助于改善结果。
结果:
图8和图9给出了有代表性的结果。我们展示了不同身体姿势的预测关键点,以及上下文的原始框架。对于关键点,我们将它们叠加在groud truth点上进行视觉对比。注意,我们并不期望这些点能完全一致,但是手指和手可以产生类似的令人满意的运动,这是本文的目标。
图8
图9
在我们的案例中,groud truth是2D身体姿势检测器的结果,这可能是错误的。最后,我们在图12中展示了失败案例,第一行是钢琴的,第二行是小提琴的。这些失败案例表明我们的系统有局限性:目前我们的系统是训练2D的姿势,而训练视频中的实际姿势是3D的。因此,被遮挡和看不见的点不能很好地预测。在视频的高速度和高频率部分,身体姿态检测器可能会产生错误,运动模糊也是如此。
-
人脸识别
+关注
关注
76文章
4005浏览量
81764 -
增强现实
+关注
关注
1文章
712浏览量
44925 -
深度学习
+关注
关注
73文章
5492浏览量
120975
原文标题:神“乐”马良:AI直接将音频转换成动画
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Xsens携手ST展示3D身体运动跟踪系统
支持 BLE 连接的接触式身体成分测量仪参考设计
夏天运动不孤单,我有三星iconx运动私教
智能手环是如何收集身体数据的和相关工作原理
身体运动传感器技术需求
身体运动传感器
【HarmonyOS HiSpark AI Camera】运动身体姿态分析
荣耀智能体脂秤2评测 什么是身体运动智能

运动听音乐用什么耳机、适合运动听歌使用的运动耳机推荐

通过生物信号采集处理系统来分析胃肠运动





 工商网监
工商网监
评论