 BatchNorm是一种旨在通过固定层输入的分布来改善神经网络训练的技术
BatchNorm是一种旨在通过固定层输入的分布来改善神经网络训练的技术
由于BatchNorm可以加速训练并获得更加稳定的结果,近年来成为了一项在深度学习优化过程中被广泛使用的技巧。但目前人们对于它是如何在优化过程中起作用的还没有达成共识。MIT的研究人员从优化过程中对应空间的平滑性这一角度为我们带来的全新的视角。

在过去的十年中,深度学习在计算机视觉、语音识别、机器翻译和游戏博弈等众所周知的各种艰巨任务中都取得了令人瞩目的进步。这些进步离不开硬件、数据集、算法以及网络结构等方面重大进展,批标准化/规范化(Batch Normalization,简称BatchNorm)的提出更是为深度学习的发展作出了巨大贡献。BatchNorm是一种旨在通过固定层输入的分布来改善神经网络训练的技术,它通过引入一个附加网络来控制这些分布的均值和方差。BatchNorm可以实现深度神经网络更快更稳定的训练,到目前为止,无论是在学术研究中(超过4,000次引用)还是实际应用配置中,它在大多数深度学习模型中都默认使用。
尽管BatchNorm目前被广泛采用,但究竟是什么原因导致了它这么有效,尚不明确。实际上,现在也有一些工作提供了BatchNorm的替代方法,但它们似乎没有让我们更好地深入理解该问题。目前,对BatchNorm的成功以及其最初动机的最广泛接受的解释是,这种有效性源于在训练过程中控制每层输入数据分布的变化以减少所谓的“Internal Covariate Shift”。那什么是Internal Covariate Shift呢,可以理解为在神经网络的训练过程中,由于参数改变,而引起层输入分布的变化。研究人员们推测,这种持续的变化会对训练造成负面影响,而BatchNorm恰好减少了Internal Covariate Shift,从而弥补这种影响。
虽然这种解释现在被广泛接受,但似乎仍未出现支持的具体证据。尤其是,我们仍不能理解Internal Covariate Shift和训练性能之间的联系。在本文中,作者证明了BatchNorm带来的性能增益与Internal Covariate Shift无关,在某种意义上BatchNorm甚至可能不会减少Internal Covariate Shift。相反,作者发现了BatchNorm对训练过程有着更根本的影响:它能使优化问题的解空间更加平滑,而这种平滑性确保了梯度更具预测性和稳定性,因此可以使用更大范围的学习速率并获得更快的网络收敛。
作者证明了在一般条件下,在具有BatchNorm的模型中损失函数和梯度的Lipschitzness(也称为β-smoothness)得到了改善。最后,作者还发现这种平滑效果并非与BatchNorm唯一相关,许多其他的正则化技术也具有类似的效果,甚至有时效果更强,都能对训练性能提供类似的效果改善。
研究人员表示深入理解BatchNorm这一基本概念的根源有助于我们更好地掌握神经网络训练潜在的复杂性,反过来,也能促进广大学者们在此基础上进一步地研究深度学习算法。
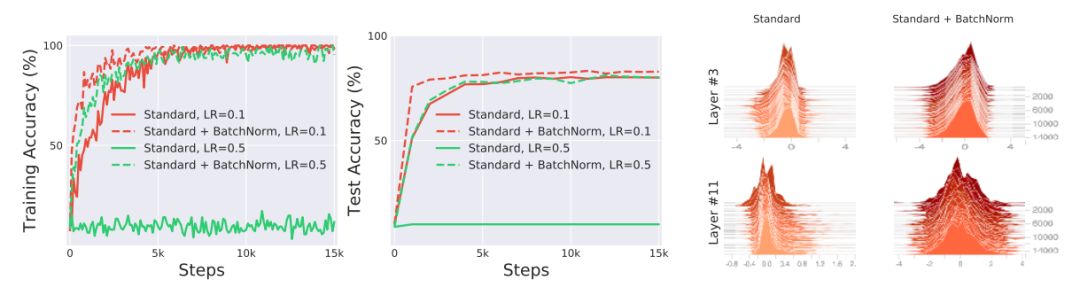
作者探讨了BatchNorm,优化和Internal Covariate Shift三者之间的关系。作者在CIFAR-10数据集上分别使用和不使用BatchNorm来训练标准的VGG网络,如上图显示用BatchNorm训练的网络在优化和泛化性能方面都有着显著改进。但是,从上图最右侧我们发现在有和没有BatchNorm的网络中,分布(均值和方差的变化)的差异似乎是微乎其微的。那么,由此引发以下的问题:
1)BatchNorm的有效性是否确实与Internal Covariate Shift有关?
2)BatchNorm固定层输入的分布是否能够有效减少Internal Covariate Shift?
首先我们训练网络时,刻意在BatchNorm层后注入随机噪声,由此产生明显的covariate shift。因此,层中的每个单元都会在各个时刻经历不同的输入分布。然后,我们测量这种引入的分布不稳定性对BatchNorm性能的影响。下图显示了标准网络、加上BatchNorm层的网络以及在BatchNorm层后加噪声的网络的训练结果。我们发现,后两者的性能差异可以忽略,并且都比标准网络要好。在标准网络中加BatchNorm之后,即便噪声的引入使得分布不稳定,但在训练性能仍比标准网络好。所以,BatchNorm的有效性与Internal Covariate Shift并没有什么联系。
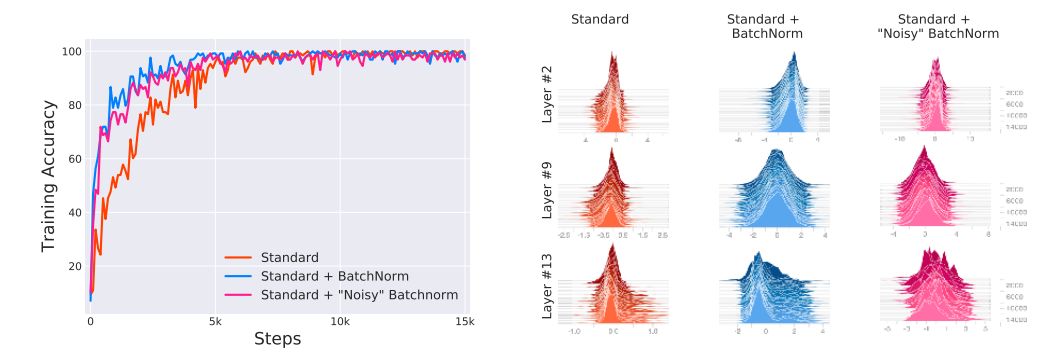
仅从输入分布的均值和方差来看,Internal Covariate Shift似乎与训练性能并没有直接联系,那么从更广泛的概念上理解,Internal Covariate Shift是否与训练性能有着直接的联系呢?如果有,BatchNorm是否真的有效减少了Internal Covariate Shift。把每层看作是求解经验风险最小化的问题,在给定一组输入并优化损失函数,但对任何先前层的参数进行更新必将改变后面层的输入,这是Ioffe和Szegedy等研究人员关于Internal Covariate Shift理解的核心。此处,作者更从底层的优化任务角度深入探究,由于训练过程是一阶方法,因此将损失的梯度作为研究对象。
为了量化每层中参数必须根据先前层中参数更新“调整”的程度,我们分别测量更新前和更新后每层梯度的变化。作者通过实验测量了带有和不带BatchNorm层的Internal Covariate Shift程度。为分离非线性效应和梯度随机性,作者还对使用全批梯度下降训练的(25层)深度线性网络(DLN)进行分析。最终,我们发现,在网络中添加BatchNorm层应该是增加了更新前和更新后层梯度之间的相关性,从而减少Internal Covariate Shift。但令人惊讶的是,我们观察到使用BatchNorm的网络经常表现出Internal Covariate Shift的增加(参见下图),DLN尤其显著。从优化的角度来看,BatchNorm可能甚至不会减少Internal Covariate Shift。
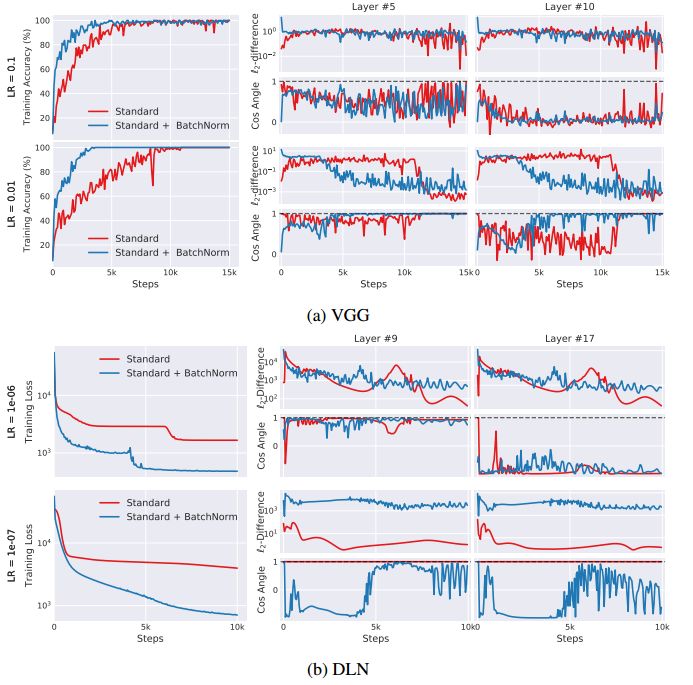
图中蓝色线为添加了BatchNorm的结果,右侧描述了对应Internal covariate shift的变化。
那BatchNorm究竟发挥了什么作用呢?
事实上,我们确定了BatchNorm对训练过程的关键影响:它对底层优化问题再参数化,使其解空间更加平滑。首先,损失函数的Lipschitzness得到改进,即损失函数能以较小的速率变化,梯度的幅度也变小。然而效果更强,即BatchNorm的再参数化使损失函数的梯度更加Lipschitz,就有着更加“有效”的β-smoothness。这些平滑效果对训练算法的性能起到主要的影响。改进梯度的Lipschitzness使我们确信,当我们在计算梯度的方向上采取更大步长时,此梯度方向在之后仍是对实际梯度方向的精准估计。
因此,它能使任何基于梯度的训练算法采取更大的步长之后,防止损失函数的解空间突变,既不会掉入梯度消失的平坦区域,也不会掉入梯度爆炸的尖锐局部最小值。这也就使得我们能够用更大的学习速率,并且通常会使得训练速度更快而对超参数的选择更不敏感。因此,是BatchNorm的平滑效果提高了训练性能。
为了证明BatchNorm对损失函数稳定性的影响,即Lipschitzness,对训练过程中每步,我们计算损失函数的梯度,并测量当我们朝梯度方向移动时损失函数如何变化。见下图中(a),我们看到,与用BatchNorm的情况相反,vanilla网络的损失函数的确有着大幅波动,特别是在训练的初始阶段。同样为了证明BatchNorm对损失函数的梯度稳定性/ Lipschitzness影响,我们在下图中(b)绘制了vanilla网络和BatchNorm 整个训练过程中的“有效”β-smoothness(“有效”在这里指,朝梯度方向移动时测量梯度的变化),结果差异性很大。
为了进一步说明梯度稳定性和预测性的增加,我们测量在训练给定点处的损失梯度与沿着原始梯度方向的不同点对应的梯度之间的L2距离。如下图中(c)显示了vanilla网络和BatchNorm网络之间的这种梯度预测中的显着差异(接近两个数量级)。我们还考察了线性深度网络,BatchNorm也有着很好的平滑效果。要强调的是,即使我们值集中探索了沿着梯度方向的损失解空间情况,对于其他任意方向,也有一致的结论。
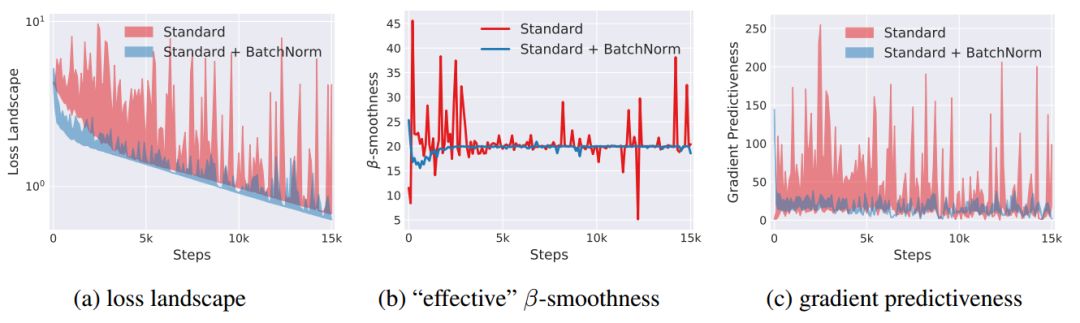
文中从理论上论证了增加BatchNorm可以降低参数的灵敏度,并很好的改善优化问题的解空间。

不同norm下VGG网络的激活直方图
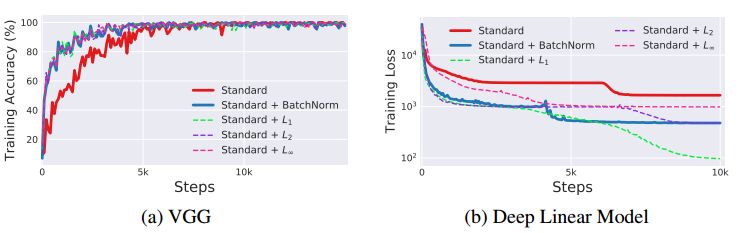
那么BatchNorm是平滑解空间最好且唯一的方法吗?答案当然不是,作者研究了一些基于自然数据统计的正则化策略,类似BatchNorm修正激活函数一阶矩的方案,用p范数均值进行正则化。不同的是,对于这些正则化方案,层输入的分布不再是高斯(见上图)。因此,用这种p范数进行正则化并不能保证对分布矩和分布稳定性有任何控制。实验结果如下图所示,可以观察到所有的正则化方法都提供了与BatchNorm相媲美的性能。事实上,对于深度线性网络来说,'L1正则化表现的要比BatchNorm更好。
值得注意的是,p范数正则化方法会导致更大的分布covariate shift。但所有这些技术都提高了解空间的平滑度,这点与BatchNorm的效果相似。以上表明BatchNorm对训练的积极影响可能实属偶然。因此,对类似的正则化方案的设计进行深入探索十分有必要,可以为网络训练更好的性能。
综上所述,作者研究了BatchNorm能提高深度神经网络训练有效性的根源,并发现BatchNorm与internal covariate shift之间的关系是微不足道的。特别是,从优化的角度来看,BatchNorm并不会减少internal covariate shift。相反,BatchNorm对训练过程的关键作用在于其重新规划了优化问题,使其Lipschitzness稳定和β-smoothness更有效,这意味着训练中使用的梯度更具有良好的预测性和性能,从而可以更快速、有效地进行优化。
这种现象同时也解释了先前观察到的BatchNorm的其他优点,例如对超参数设置的鲁棒性以及避免梯度爆炸或消失。作者也展示了这种平滑效果并不是BatchNorm特有的,其他一些自然正则化策略也具有相似的效果,并能带来可比较的性能增益。我们相信这些新发现不仅可以消除关于BatchNorm的一些常见误解,而且还会使我们在真正意义上理解这种基本技术以及更加好的处理深度网络的训练问题。
最后,作者表明虽然重点在于揭示BatchNorm对训练的影响,但其发现也可能揭示BatchNorm对泛化能力的改进。具体来说,BatchNorm重新参数化的平滑效应可能会促使训练过程收敛到更平坦的极小值,相信这样的极小值会促进更好的泛化。
-
神经网络
+关注
关注
42文章
4774浏览量
100899 -
计算机视觉
+关注
关注
8文章
1698浏览量
46032 -
深度学习
+关注
关注
73文章
5508浏览量
121295
原文标题:深度 | BatchNorm是如何在深度学习优化过程中发挥作用的?
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论