 一种用于图像分类的卷积神经网络
一种用于图像分类的卷积神经网络
摘要:提出了一种用于图像分类的卷积神经网络,将不同池化方式对图像分类的影响进行了分析对比,采用重叠池化和dropout技术,较好地解决过拟合问题。与传统神经网络相比,该方法在CIFAR-10数据集上获得了较好的结果,在测试集上准确率比训练集上准确率高9%左右。
0 引言
随着互联网和多媒体技术的快速发展,图像数据呈现出爆发式的增长,如何对海量图像进行高效的分类和检索成了一项新的挑战。图像分类是图像检索、物体检测和识别等应用的基础,也是模式识别和机器学习中的研究热点。
深度学习是一种对数据进行表征学习的方法[1],起源于神经网络,已有几十年之久,但是一度发展缓慢。直至2012年,HOMTPM G和他的团队在ImageNet大型图像识别竞赛中取得极其优异的成绩,将top-5的错误率由26%降到15%,从此,深度学习引起了越来越多研究者的关注,进入快速发展时期。
深度学习技术在神经网络模型训练过程中常常会引起过拟合的问题。所谓过拟合(Overfitting),是指模型对训练集的数据拟合得很好,而对它未学习过的数据集拟合并不好,泛化能力较弱,即对学习过的样本效果很好,推广到更一般、更具普适性的样本上表现并不好。
本文针对神经网络模型中常见的过拟合问题,将不同池化方式对图像分类的影响进行了分析对比,提出了一种采用重叠池化和dropout技术的卷积神经网络,在一定程度上缓解了过拟合问题,能够应对更加复杂多变的数据环境。
1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是深度学习最常用的网络模型之一,在语音分析、图像识别等领域广泛应用。传统的神经网络是全连接的,参数数量巨大,训练耗时甚至难以训练,而卷积神经网络受到现代生物神经网络的启发,通过局部连接、权值共享等方式降低了模型复杂度,减少权重数量,降低了训练的难度。
1.1 卷积特征提取
图像卷积实际上是对图像的空间线性滤波,滤波本是频域分析常用的方法,图像中也经常使用空间滤波进行图像增强。滤波所用的滤波器也就是卷积中的卷积核,通常是一个邻域,比如一个3×3大小的矩阵。
卷积过程是把卷积核中的元素依次和图像中对应的像素相乘求和作为卷积后新的像素值,然后把该卷积核沿着原图像平移,继续计算新的像素值,直至覆盖整个图像。卷积过程如图1所示。
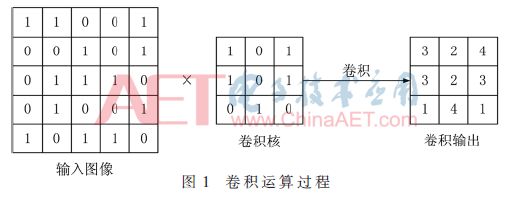
图1是忽略了偏置项的卷积过程,输入图像大小是5×5,卷积核大小是3×3,卷积后的输出大小也是3×3。具体运算过程是卷积核从输入图像的左上角开始进行线性求和运算,然后每次向右移动一个像素的距离,直至最右侧,再向下移动一个像素,依次进行,便可得到卷积输出。如果想让输出和输入大小相同,可以在原图像周围补一圈“0”变成7×7的大小,然后再进行卷积运算即可。
卷积的作用过程虽然很简单,但却能根据不同的卷积核对图像产生很多不同的效果。上述卷积过程实质上是一种相关作用,与严格的图像处理中的卷积稍有不同,严格的卷积需要把卷积核先旋转180°再进行相关运算。
对图像进行卷积操作,实际上是在对图像进行特征提取,卷积可以消除图像旋转、平移和尺度变换带来的影响[2]。卷积层特别擅长在图像数据中提取特征,并且不同层能提取不同的特征。
卷积神经网络的特点是逐层提取特征,第一层提取的特征较为低级,第二层在第一层的基础上继续提取更高级别的特征,同样,第三层在第二层的基础上提取的特征也更为复杂。越高级的特征越能体现出图像的类别属性,卷积神经网络正是通过逐层卷积的方式提取图像的优良特征。
1.2 池化下采样
图像经过卷积之后会产生多个特征图,但是特征图的大小与原始图像相比并没有改变,数据量仍然很大,计算量也会很大,为了简化运算,常常会把特征图进行下采样。卷积神经网络采取池化(Pooling)的方式进行下采样,常见的池化方法有两种:最大值池化(MaxPooling)和平均值池化(AvgPooling),两种池化过程如图2所示。
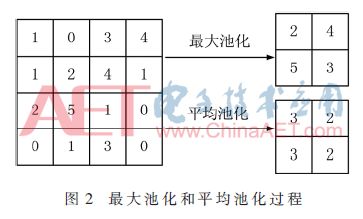
图2中,窗口大小是2×2,步长是2。最大值池化是在窗口覆盖的4个像素内选择最大的像素值作为采样值;平均值池化是计算窗口内4个像素的平均值,每次把窗口向右或者向下移动2个像素的距离,所以4×4的特征图池化后大小变为2×2。
2 用于图像分类的CNN模型设计
本文参考VGGNet中卷积块[3]思想设计了一种卷积神经网络模型,在卷积层和全连接层加入了dropout层,一定程度上缓解了过拟合问题,还对不同池化方式和池化窗口对分类效果的影响进行了分析对比。
2.1 基础神经网络结构
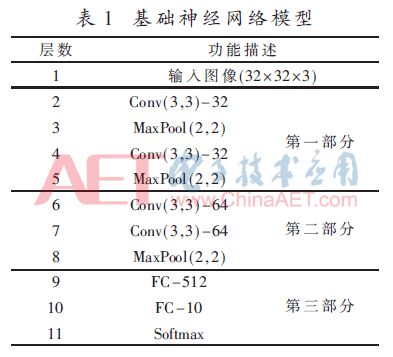
该网络模型如表1所示,共有11层,包括4个卷积层,3个池化层,主要包括3个部分。首先第一层是输入层,本文使用的数据集有10个种类,是大小为32×32的彩色图像,使用RGB颜色空间,所以输入层大小是32×32×3。第一部分包括2个卷积层和2个池化层,2个卷积层的特征图数量都是32;第二部分包括2个卷积层和1个池化层,2层卷积的特征图都是64个;第三部分是稠密连接层,即全连接层,第1层全连接层是512个神经元,第2层是10个,即划分到10个种类,然后使用Softmax回归进行分类。表1中的Conv(3,3)-32代表该层是卷积层,且卷积核大小是3×3有32个特征图;MaxPool(2,2)是指最大值池化,且窗口大小是2×2;FC-512是指该层是全连接层,神经元数目是152个。
2.2 存在问题分析
针对本模型使用CIFAR-10数据集进行试验测试,部分样例如图3所示。

使用CIFAR-10数据集结合Rmsprop优化方法训练该网络,把所有训练集中的图像训练一遍为一个周期(epoch)。在训练100个周期后,训练过程准确率变化如图4所示。
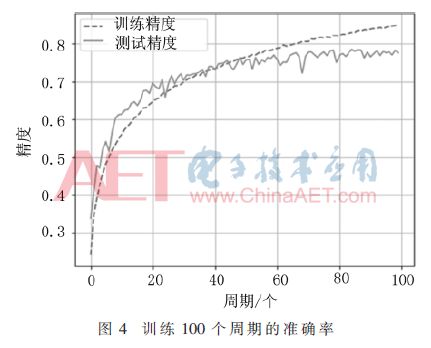
在训练过程中每一个周期都会计算训练数据集和测试数据集的准确率,可以看出在40个周期之前,测试集的准确率随着训练集的准确率一起上升,在第40个周期时达到0.74;之后训练集的准确率继续上升,而测试集的准确率上升很小,而且有小幅波动;在70个周期之后,训练集准确率仍继续上升,而测试集准确率保持平稳,变化很小。本次训练的损失函数如图5所示。
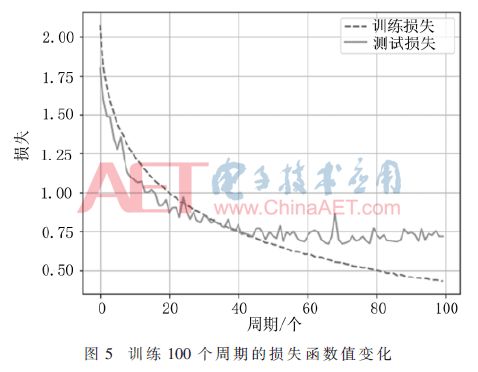
从图5也可以看出,开始时测试集随着训练集的损失值一起下降,40个周期之后测试集的损失值一直在0.72~0.75之间波动,而训练集的损失值还一直保持着下降的趋势,第80个周期下降到0.50,最后下降到0.42。损失函数的变化也从侧面印证了该模型出现了较为严重的过拟合问题。
3 本文提案的模型
使用重叠池化可以缓和过拟合问题,使用正则化也可以解决过拟合问题。HINTON G E于2012年提出了dropout技术[4],针对神经网络的过拟合问题有了较大改善。dropout是指在训练网络的过程中按照一定的比例随机丢弃部分神经元,即把某层中的神经元随机选取一部分使其输出值为0,这样会使得这部分被选中的神经元对下一层与其相连的神经元输出没有贡献,失去作用。
多次实验发现,针对该网络模型最大值池化比平均值池化效果相对较好,使用重叠池化也可以改善效果,训练100个周期训练集和测试集的准确率如表2所示。
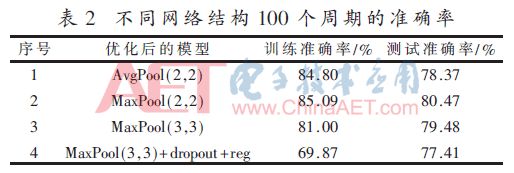
表2记录的是针对不同网络结构在100个周期内训练集和测试集的最高准确率。第1种和第2种模型分别采用平均值和最大值的非重叠池化,可以看出最大值池化相对平均值池化效果更好,但是二者都有过拟合问题;第3种模型是最大值重叠池化,一定程度上缓解了过拟合问题;第4种模型使用了最大值重叠池化和dropout技术并加上了适量正则化,可以看出训练集的准确率远低于测试集,其准确率上升还有较大潜力。因此,选择第4种作为优化后的网络结构,完整的网络结构如表3所示。

优化后的网络结构与原结构相比分别在第5层和第9层最大值重叠池化层后加入了0.25比例的dropout层,在第11层全连接层后加入了0.5比例的dropout层。另外对卷积层和全连接层的网络权重使用了L2正则化,正则化因子较小只有0.000 1,仍然使用Rmsprop学习方法训练300个周期之后的准确率如图6所示。
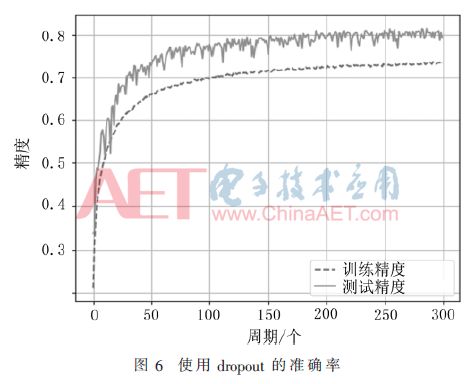
从图6的训练过程可以看出,dropout技术较好地解决了过拟合问题,测试集准确率随着训练集的准确率一起上升,而且训练集准确率一直都低于测试集,300个周期内训练集准确率最高是73.49%,测试集最高准确率可以达到82.15%,可见dropout技术大大改善了过拟合问题。
dropout在训练过程中随机丢弃部分神经元,每一批次的数据训练的都是一个不同的网络结构,相当于训练了多个网络,把多个不同结构的网络组合在一起,集成多个训练的网络于一体,可以有效防止单一结构网络的过度拟合。
4 结束语
本文提出了一种用于图像分类的卷积神经网络模型,针对传统卷积神经网络出现的过拟合问题,使用不同的池化方式和dropout技术,优化了网络结构,提高了模型的图像分类性能,在CIFAR-10数据集上取得较好的分类效果。
-
神经网络
+关注
关注
42文章
4771浏览量
100712 -
图像分类
+关注
关注
0文章
90浏览量
11914 -
深度学习
+关注
关注
73文章
5500浏览量
121111
原文标题:【学术论文】基于深度学习的图像分类方法
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论