 数据集使用的Kaggle中辨别狗狗种类的竞赛
数据集使用的Kaggle中辨别狗狗种类的竞赛
编者按:在人工智能的各个领域,深度学习框架正变得越来越高效,其中图像分类更是得益于此。在这篇文章中,作者devforfu尝试用Keras库将现成的ImageNet和预训练深度模型应用到图像分类框架上。他搭建了一款模型,可以辨别图片中狗狗的种类。
数据集
在这个项目中,数据集使用的Kaggle中辨别狗狗种类的竞赛,其中包含了将近10000张经过标记的图像,大约涵盖了120种狗狗,除此之外还有数量相当的测试数据。一般来说,这些图像的分辨率、缩放程度都是不同的,其中也可能不止有一只狗,光线也会有差别。下面是数据集中的几张图像。
数据集中各种种类的狗狗数量大致相同,平均每种狗狗有59张图像。以下是数据集中各种类狗狗的数量分布:
正如我们简单分析过的,经过分析的数据集对深度学习框架来说并不复杂,并且有很多简单结构。所以我们可以从数据集中得到各种类精确的结果。
Bottleneck特征
运用预训练深度学习模型最直接的策略之一是将它们看作特征提取器。在现代神经网络架构发展之前,图像特征是手动过滤的,例如Canny edge detectors中的Sobel operator。运算符(operator)是一个3×3的矩阵,向其中输入原始图像后,它会将其转化成一个正方形的图块,每个小方块都会转换成单一值。
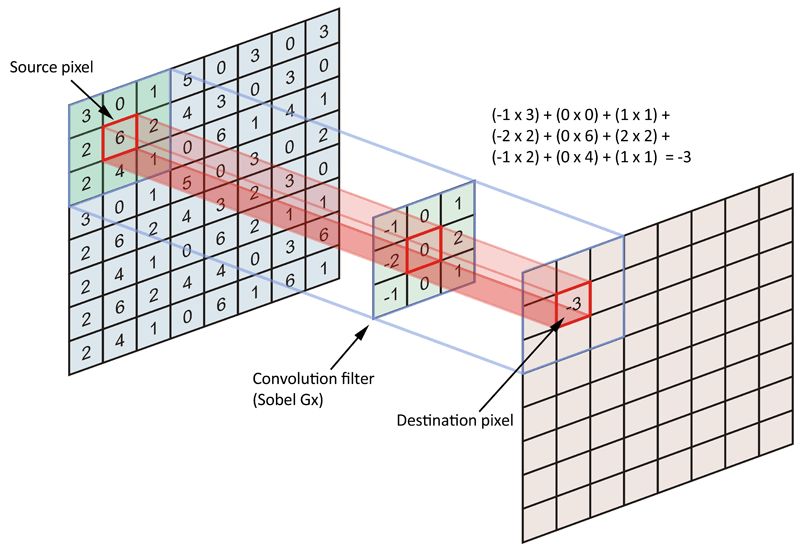
Sober运算符在单一图像通道上的大致表示
如今的技术可以从数据中直接自动提取特征。为此,我们用的是卷积层。每个卷积层都是具有随机初始值的正方形矩阵堆栈。这些值在训练过程中被更新,最终会收敛到适合数据集的特殊过滤器上。
下图展示了深度学习分类器作为特征模块序列的大致表示,将图像从原始的像素表示转换成更加抽象的表示:
如上图,一个没有顶层图层的深度学习网络为每张通过网络的图像生成了一套高水平的特征。这些特征被称为bottleneck特征。深度模型自动推理出这些抽象的图像特征,我们可以用它们以及任意“经典”的机器学习算法来预测目标。
注意:本文所提到的所有模型和特征提取器都是在单一1080Ti GPU上执行的。如果用CPU的话,在有数千张图片的数据集上提取特征可能要耗费好几个小时。
因此,想从图片集中提取特征,研究者需要下载一个有预训练权重的深度网络,但是没有顶层,之后为这些图像”做预测“。示例如下:
classFeaturesExtractor:
"""Runs pretrained model without top layers on dataset and saves generated
bottleneck features onto disk.
"""
def __init__(self, build_fn, preprocess_fn, source,
target_size=(299, 299, 3), batch_size=128):
self.build_fn = build_fn
self.preprocess_fn = preprocess_fn
self.source = source
self.target_size = target_size
self.batch_size = batch_size
def __call__(self, folder, filename, pool='avg'):
model = self.build_fn(weights='imagenet', include_top=False, pooling=pool)
stream = self.source(
folder=folder, target_size=self.target_size,
batch_size=self.batch_size, infinite=False)
batches = []
with tqdm.tqdm_notebook(total=stream.steps_per_epoch) as bar:
for x_batch, y_batch in stream:
x_preprocessed = self.preprocess_fn(x_batch)
batch = model.predict_on_batch(x_preprocessed)
batches.append(batch)
bar.update(1)
all_features = np.vstack(batches)
np.save(filename, all_features)
return filename
代码的第15行创造了一个没有顶层的Keras模型,但是具有预先安装的ImageNet权重。之后,22—25行对所有图片进行了迭代,并将它们转化成特征数组。之后在第29行,数组被永久存储。注意,我们并不一次性下载所有可用图片,而是创造一个生成器,替代从硬盘中读取文档。这样操作可以允许在没有足够RAM的情况下处理大型数据集,因为图片从JPEG转换成PNG格式会消耗很大内存。
之后,我们可以用FeatureExtractor:
from keras.applications import inception_v3
extractor = FeatureExtractor(
build_fn=inception_v3.InceptionV3,
preprocess_fn=inception_v3.preprocess_fn,
source=create_files_iterator_factory())
extractor(folder_name, output_file)
Bootstrapped SGD
随机梯度下降(SGD)是一种简单高效的在凸形损失函数对线性分类器进行判别学习的方法。简单地讲,将图片特征的数组和他们的标签输入算法中,训练一个多种类的分类器,从而判断狗狗的种类。
虽然现在已有了一个特殊的SGD分类器,但是还不够稳定。对算法运行多次之后可能会得到不同精度的结果,因为算法在学习开始时对参数进行了随机初始化。
为了让训练过程更加稳定并且可重复,为了达到最佳精度,我们将用bagging扩展SGD,这种方法可以训练SGD分类器的集合,并且能从多个估算器中对反馈取平均值,得出最终的预测。下图是这一过程的展示:
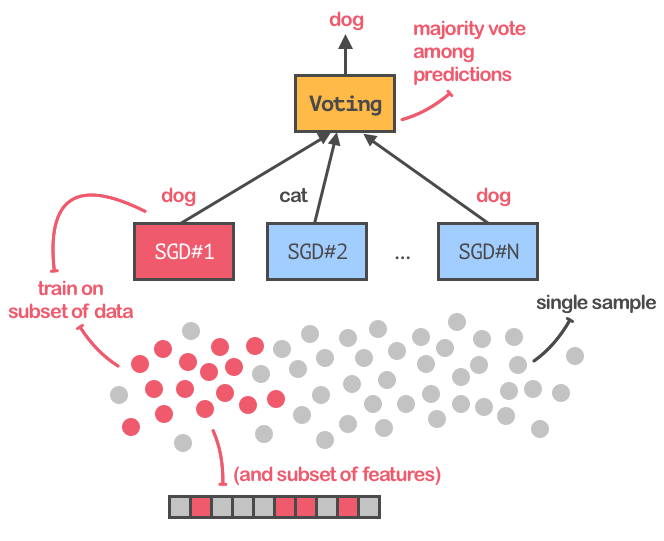
在SGD分类器上应用bagging技术
注意,我们不仅仅是将原始数据集拆分成子集,而是将不同特征的自己放入不同分类器训练。另外,我们还应用了一个“变量阈值转换器(variance threshold transformer)”,将值接近于0的bottleneck特征过滤掉,因为深度学习网络提取的特征向量似乎非常稀疏。
下面的代码展示了如何创建一个SGD分类器,以及如何计算能反映模型质量的预测标准:
def sgd(x_train, y_train, x_valid, y_valid, variance_threshold=0.1):
threshold = VarianceThreshold(variance_threshold)
sgd_classifier = SGDClassifier(
alpha=1./len(x_train),
class_weight='balanced',
loss='log', penalty='elasticnet',
fit_intercept=False, tol=0.001, n_jobs=-1)
bagging = BaggingClassifier(
base_estimator=sgd_classifier,
bootstrap_features=True,
n_jobs=-1, max_samples=0.5, max_features=0.5)
x_thresh = threshold.fit_transform(x_train)
bagging.fit(x_thresh, y_train)
train_metrics = build_metrics(bagging, x_thresh, y_train)
x_thresh = threshold.transform(x_valid)
valid_metrics = build_metrics(bagging, x_thresh, y_valid)
return bagging, train_metrics, valid_metrics
def build_metrics(model, X, y):
probs = model.predict_proba(X)
preds = np.argmax(probs, axis=1)
metrics = dict(
probs=probs,
preds=preds,
loss=log_loss(y, probs),
accuracy=np.mean(preds == y))
return namedtuple('Predictions', metrics.keys())(**metrics)
第四行是创建一个SGD分类器的示例,其中有一对正则化参数和运用CPU训练模型的权限。第十行创建了一组分类器,15—20行训练了分类器,并计算了几个表现标准。
SGD基准
现在有很多可用的预训练深度学习结构,它们在我们的数据集上用作特征提取器时是否表现得同样好?下面让我们来看看。
我们选取了以下三种结构来训练SGD分类器:
InceptionV3
InceptionResNetV2
Xception
Keras中都包含这三种架构,每个分类器在9200个样本上进行训练并在1022个图像上进行验证。下表展示了训练和验证自己的预测结果。
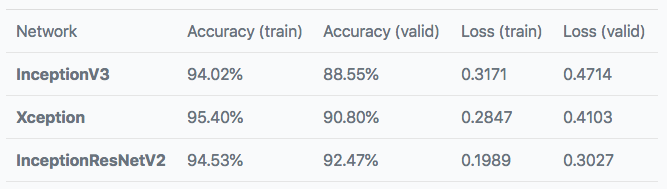
这个分数还不错!对于如此简单的实现过程,这个结果已经很令人满意了。
对预训练模型进行微调
在SGD分类器上对bottleneck特征的训练已经表示,这些特征能达到良好的预测效果。然而,我们能够通过重新训练顶层、对模型进行微调来提高分类器的精度呢?同样,我们能否通过对训练集的预处理,让模型在过拟合上更稳定,并且提高它的泛化能力?
微调的目的是让预训练模型适应数据。大多数情况下,重新使用的模型都会在含有不同种类的数据集上训练。所以,你需要将网络顶端的分类层替换掉。如图所示:
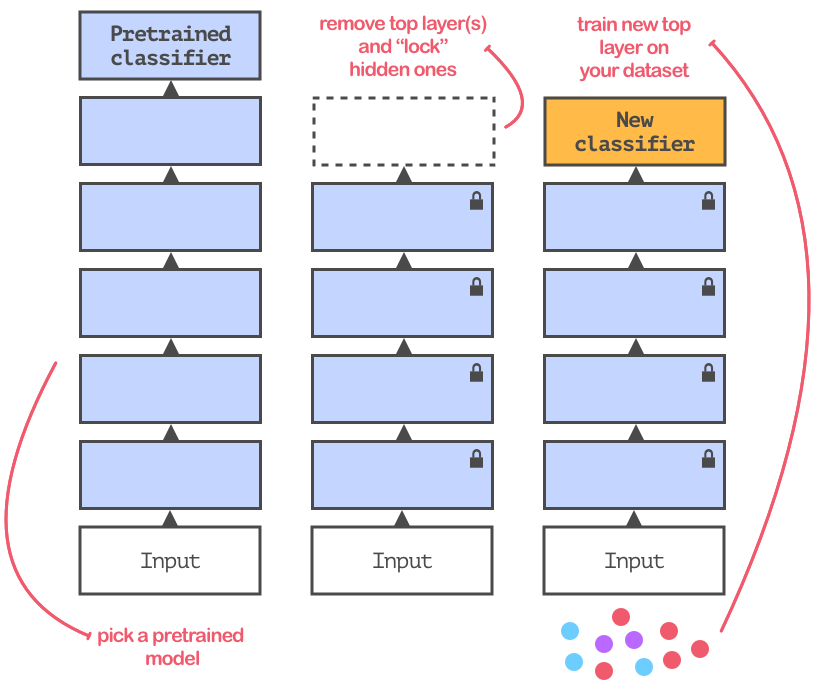
微调过程示意
新顶层的训练过程和之前的并没什么不同,我们只用了不同的分类器。但是,我们可以用数据增强的方式提高网络的泛化能力。每个微调过的网络都用稍微改动过的图像训练(例如稍微旋转、缩放等)。
微调基准
为了测试微调后的精确度,我们将添加一个结构:
ResNet50
InceptionV3
Xception
InceptionResNetV2
每个模型进行100次迭代测试,每次有128个样本:
from keras.optimizers import SGD
sgd = SGD(lr=0.001, momentum=0.99, nesterov=True)
下面是数据增强中参数的选择:
from keras.preprocessing.image importImageDataGenerator
transformer = ImageDataGenerator(
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
rotation_range=30,
vertical_flip=False,
horizontal_flip=True)
最后,模型训练过程的实现:
from keras.models importModel
from keras.layers importDense
base = create_model(include_top=False)
x = Dense(120, activation='softmax')(x)
model = Model(inputs=base.inputs, outputs=x)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
train_gen = create_training_generator()
valid_gen = create_validation_generator()
model.fit_generator(train_gen, validation_data=valid_gen)
下表是训练后模型的表现:
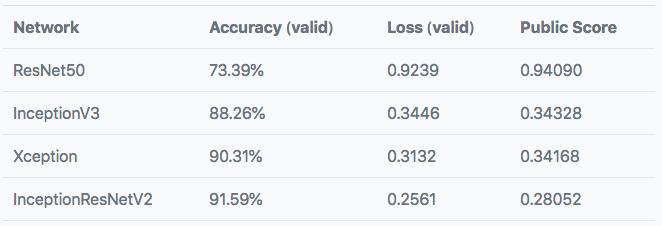
与之前的表现相比并没有很大的提升,但是数据增强和预训练InceptionResNetV2网络顶部单一密集层的表现却是最好的。
实际案例
让我们看看模型在陌生图像上的表现到底如何吧,下图是数据集之外的网络图片,模型预测了五种最可能的狗狗品种:
模型对有些猫或狗的种类并不完全肯定,也就是说我们可以用它当做狗狗探测器。
结论
现成的模型在这个项目中的表现十分不错,在狗狗分类数据集上训练之后就能达到精确的结果。我相信如果再增加更多的顶层、“解锁”更多隐藏层、加入正则化技术和更多优化,模型的表现会更好。
但是这一实验的缺点是选择的数据集是从ImageNet上挑选的狗类图片,也就是说我们的网络可能之前就见过它们了。关于这一问题论智君也曾报道过数据集的重复使用所带来的副作用,可能会引起一些偏差。
-
人工智能
+关注
关注
1797文章
47909浏览量
240955 -
数据集
+关注
关注
4文章
1211浏览量
24890 -
深度学习
+关注
关注
73文章
5521浏览量
121679
原文标题:拉布拉多还是巴哥?用Keras轻松识别狗子的品种
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Kaggle机器学习/数据科学现状调查

Hfut | 集电竞赛
如何辨别各种类型的接口
用这个可以知道你的狗狗每天的活动
Kaggle没有否认将被谷歌收购
如何很容易地将数据共享为Kaggle数据集

Kaggle创始人Goldbloom:我们是这样做数据科学竞赛的
腾讯宣布其人工智能球队获首届谷歌足球Kaggle竞赛冠军
Kaggle神器LightGBM的最全解读
如何从13个Kaggle比赛中挑选出的最好的Kaggle kernel
PyTorch教程-5.7. 在 Kaggle 上预测房价






 工商网监
工商网监
评论