 神经网络惊人的脆弱性和灵活性
神经网络惊人的脆弱性和灵活性
对抗攻击通常会使得神经网络分类错误,但谷歌大脑团队的Ian Goodfellow 等人的新研究提出一个更加复杂的攻击目标:对神经网络重新编程,诱导模型执行攻击者选定的新任务。该研究首次表明了神经网络惊人的脆弱性和灵活性。
对抗样本(adversarial examples)的研究一般是为了预防攻击者通过对模型的输入进行微小的修改,从而导致模型的预测产生偏差。这样的攻击者可能通过一张贴纸(一个小的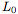 扰动)就让无人驾驶汽车对停车标志产生反应,或者通过精巧地修改损害情况的照片(一个小的
扰动)就让无人驾驶汽车对停车标志产生反应,或者通过精巧地修改损害情况的照片(一个小的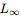 扰动)导致保险公司的损失模型高估了事故的赔偿值。考虑到这些,研究人员们提出了很多方法来构建以及抵抗这种对抗性攻击(adversrial attacks)。
扰动)导致保险公司的损失模型高估了事故的赔偿值。考虑到这些,研究人员们提出了很多方法来构建以及抵抗这种对抗性攻击(adversrial attacks)。
迄今为止,大多数的对抗性攻击主要由无目标攻击(untargeted attacks)和有目标攻击(targeted attacks)组成。无目标攻击旨在降低模型的性能,但不一定需要产生一个特定的输出;而有目标攻击旨在对模型设计一个对抗性干扰的输入,从而产生一个特定的输出。例如,对一个分类器的攻击可能是为了针对每张图像得到特定的输出类别,或者,对一个强化学习智能体的攻击可能是为了诱导该智能体进入一个特定的状态。
近日,谷歌大脑的 Gamaleldin F. Elsayed、Ian Goodfellow 和 Jascha Sohl-Dickstein 等人的新研究考虑了一个更加复杂的攻击目标:在不需要攻击者计算特定期望输出的情况下,诱导模型执行攻击者选定的一个任务。
对抗性重编程
考虑一个训练用来执行一些原始任务的模型:对于输入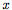 ,它将产生输出
,它将产生输出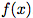 。考虑一个敌人(adversary),它希望执行一个对抗的任务:对于输入
。考虑一个敌人(adversary),它希望执行一个对抗的任务:对于输入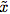 (不一定和x在同一个域),敌人希望计算一个函数
(不一定和x在同一个域),敌人希望计算一个函数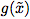 。我们证明敌人可以通过学习对抗性重编程函数( adversarial reprogramming functions)
。我们证明敌人可以通过学习对抗性重编程函数( adversarial reprogramming functions)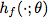 和
和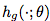 来实现这一点,这两个函数是两个任务之间的映射。这里,hf 将来自x˜的域的输入转换成
来实现这一点,这两个函数是两个任务之间的映射。这里,hf 将来自x˜的域的输入转换成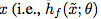 的域。
的域。
在这项工作中,为了简单起见,并且为了获得高度可解释的结果,我们将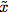 定义为小图像(small images),g是处理小图形的函数,
定义为小图像(small images),g是处理小图形的函数,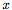
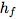 只包括在大图像的中心绘制
只包括在大图像的中心绘制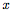 ,在边框中绘制θ,而
,在边框中绘制θ,而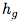 只是输出类标签之间的硬编码映射。
只是输出类标签之间的硬编码映射。
然而,这个想法更具通用性;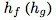 可以是在两个任务的输入(输出)格式之间转换的任何一致性转换,并使模型执行对抗性任务。
可以是在两个任务的输入(输出)格式之间转换的任何一致性转换,并使模型执行对抗性任务。
我们指的是一类攻击,在这种攻击中,机器学习算法被重新用于执行一项新的任务,即对抗性重编程(adversarial reprogramming)。我们将θ称为对抗程序( adversarial program)。与以往大多数对抗样本的研究相比,这种扰动的幅度不需要受到限制。这种攻击不需要使人类察觉不到,或是需要很微妙才被认为是成功的。对抗性重编程的潜在后果包括:从公共服务中窃取计算资源,或将AI驱动的助理改造成间谍机器人或垃圾邮件机器人。
在这篇文章中,我们介绍了对抗性重编程的第一个实例。我们提出一种设计对抗程序的训练过程,对抗程序将导致神经网络执行新的任务。在实验部分,我们演示了针对用于ImageNet数据分类的几个卷积神经网络的对抗程序。这些对抗程序将网络的功能从ImageNet分类改变成:对图像中的方块进行计数;对MNIST的数字进行分类,对CIFAR-10图像进行分类。我们还研究了训练好的和未训练的网络对对抗性重编程的易感性。
方法
我们提出的攻击场景如下:当执行一个特定任务时,敌人已经获取了神经网络的参数,并希望通过使用一个可以加入到网络输入中的攻击程序来操纵网络的函数,以此来执行一个新的任务。在这里,我们假设原始的网络是用来执行ImageNet分类的,但是本文讨论的方法是具有可扩展性的。
我们的对抗性程序将作为网络输入的附加贡献。值得注意的是,不像其他大多数对抗性干扰,我们的对抗性程序并不针对单一的图像。同样的对抗性程序将应用到所有的图像中。我们将对抗性程序定义为:

其中,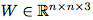 是将要学到的对抗性程序的参数,n是ImageNet图像的宽度,M是一个masking矩阵。值得注意的是,M并不是必需的。
是将要学到的对抗性程序的参数,n是ImageNet图像的宽度,M是一个masking矩阵。值得注意的是,M并不是必需的。
让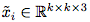 作为我们所希望应用到对抗性任务中数据集的一个样本,其中
作为我们所希望应用到对抗性任务中数据集的一个样本,其中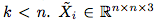 。那么相应的对抗性图像可表示为:
。那么相应的对抗性图像可表示为:
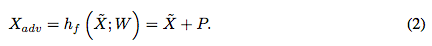
给定一个输入图像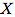 ,使
,使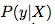
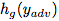 ,它是将对抗性任务
,它是将对抗性任务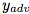 中的一个标签映射到一个ImageNet标签集合。至此,我们对抗性的目标就是将概率
中的一个标签映射到一个ImageNet标签集合。至此,我们对抗性的目标就是将概率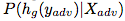 最大化。于是,我们将优化问题设置为:
最大化。于是,我们将优化问题设置为:
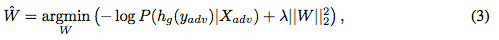
实验结果
1. 计算图像中的方格数
首先从简单的对抗性任务开始,即计算图像中的方格数。结果如图所示:
图1:对抗性重编程的说明。
(a)将ImageNet标签映射到对抗性任务的标签(图像中的方块)。
(b)对抗性任务中的图像(左侧)是嵌入在一个对抗性问题中的(中间),产生对抗性图像(右侧)。
(c)利用对抗性图像进行推测的说明。
2. MNIST分类
图2:为MNIST分类进行对抗性编程的例子。
对抗性程序导致6个ImageNet模型转而用作MNIST分类器。
3. CIFAR-10分类
图3:CIFAR-10分类中对抗性图像的例子(图注)
对抗性程序重新利用一个Inception V3 模型作为CIFAR-10分类器的替代函数。
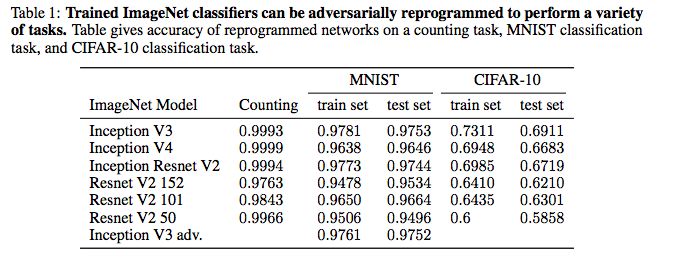
表:训练好的ImageNet分类器可以对抗性地再编程来执行多种任务
4. 再次编程未训练以及对抗性训练过的网络
图4:对抗性程序不论在网络还是任务中都表现出质的相似性和不同性。
(a)顶部:将在ImageNet上预训练的网络重新利用来计算图像中方块数量的对抗性程序。
中部:将在ImageNet上预训练的网络作为MNIST分类器函数的对抗性程序。
底部:对抗性程序将相同的网络作为CIFAR-10分类器。
(b)针对具有随机初始化参数的重组网络,对抗性程序将其作为MNIST分类器。
-
谷歌
+关注
关注
27文章
6168浏览量
105394 -
神经网络
+关注
关注
42文章
4771浏览量
100775 -
图像
+关注
关注
2文章
1084浏览量
40469
原文标题:Ian Goodfellow最新论文:神经网络无比脆弱,对抗攻击重新编程
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络如何使用
如何设计BP神经网络图像压缩算法?
如何构建神经网络?
嵌入式Linux的灵活性
网络脆弱性扩散分析方法





 工商网监
工商网监
评论