 DeepMind分享了他们在多智能体学习方面的进展
DeepMind分享了他们在多智能体学习方面的进展
继OpenAI之后,DeepMind也在多智能体强化学习方面秀肌肉:首次在第一人称射击游戏的多人模式中完胜人类,而且没有使用大量训练局数,轻松超过了人类水平。
就在OpenAI宣布在5v5 DOTA 2中战胜人类玩家后没多久,今天,DeepMind也分享了他们在多智能体学习(multi-agent learning)方面的进展。
CEO Hassabis在Twitter上分享:“我们最新的工作展示了智能体在复杂的第一人称多人游戏中达到人类水平,还能与人类玩家合作!”
Hassbis说的这个游戏,就是《雷神之锤III竞技场》,这也是很多现代第一人称射击游戏的鼻祖,玩家或独立或组队在地图中厮杀,死亡后数秒在地图某处重生。当某一方达到胜利条件(在DeepMind的实验里就是抢夺更多的旗帜),或者游戏持续一定时间后即宣告回合结束。胜利条件取决于选择的游戏模式。
虽然Hassbis在Twitter里说他们的AI“达到了人类水平”,实际上,从实验结果看,他们的AI已经超越了人类:在与由40个人类玩家组成的队伍对战时,纯AI的队伍完胜纯人类的队伍(平均多抢到16面旗),并且有95%的几率战胜AI与人混合组成的队伍。
这个AI名叫“为了赢”(For the Win,FTW),只玩了将近45万场游戏,理解了如何有效地与人和其他的机器合作与竞争。
研究人员对AI的唯一限定是,在5分钟时间里尽可能取得多的旗帜。对战的游戏地图是随机生成的,每场都会变,室内与室外的地形也不相同。组队的时候,AI可能与人组队,也可能与其他AI组队。对战的模式分为慢速和高速两种。
在训练过程中,AI发展出了自己的奖励机制,学会了基地防守、尾随队友,或者守在敌人营地外偷袭等策略。
DeepMind在他们今天发表的博客文章中写道,从多智能体的角度说,玩《雷神之锤III》这种多人视频游戏,需要与队友合作,与敌方竞争,还要对遭遇到的任何对战风格/策略保持鲁棒性。
分析发现,游戏中,AI在“tagging”(碰触对方,将其送回地图上的初始地点)上比人类更加高效,80%的情况下能够成功(人类为48%)。
而且有趣的是,对参与对战的人类玩家进行调查后发现,大家普遍认为AI是更好的team player,更善于合作。
第一人称射击游戏多人模式重大突破
启元世界首席算法官、前Netflix资深算法专家王湘君告诉新智元:
之前第一人称射击(FPS)游戏的研究更多是单人模式,这次DeepMind在FPS多人模式做出了重大突破,在没有使用大量训练局数的情况下就超过了人类水平。和之前OpenAI Five相比,DeepMind的Capture the Flag (CTF) 模型直接从pixel学习,没有作feature engineering和为每个agent单独训练模型,得益于以下创新:
去年DeepMind Max Jaderberg 提出的Population-based training 的应用极大提高了训练效率,并且提供了多样化的exploration,帮助模型在不同地形队友环境中的适应性,实验结果显示比self-play的结果更好更高效。
For The Win agent 的分层reward机制来解决credit assignment问题。
用fast and slow RNN 和内存机制达到类似Hierarchical RL的作用。
不过,FPS在策略学习上面的难度还是比Dota,星际这种RTS游戏小很多,CTF模型在长期策略游戏上效果还有待观察。
在和人类对战模式之外,CTF模型同时在人机协作上有很好的效果。值得一提的是,启元世界在今年4月份北大ACM总决赛期间发布的基于星际争霸2的人机协作挑战赛,其智能体也率先具备了与人和AI组队协作的能力。人机协作在未来的人工智能研究领域将成为非常重要的一环。
掌握策略,理解战术和团队合作
在多人视频游戏中掌握策略、战术理解和团队合作是人工智能研究的关键挑战。现在,由于强化学习取得的新进展,我们的智能体已经在《雷神之锤III竞技场》(Quake III Arena)游戏中达到了人类级别的表现,这是一个经典的3D第一人称多人游戏,也是一个复杂的多智能体环境。这些智能体展现出同时与人工智能体和人类玩家合作的能力。
我们居住的星球上有数十亿人,每个人都有自己的个人目标和行动,但我们仍然能够通过团队、组织和社会团结起来,展现出显著的集体智慧。这是我们称之为多智能体学习(multi-agentlearning)的设置:许多个体的智能体必须能够独立行动,同时还要学会与其他智能体交互和合作。这是一个极其困难的问题——因为有了共适应智能体,世界在不断地变化。
为了研究这个问题,我们选择了3D第一人称多人视频游戏。这些游戏是最流行的电子游戏类型,由于它们身临其境的游戏设计,以及它们在策略、战术、手眼协调和团队合作方面的挑战,吸引了数以百万计的玩家。我们的智能体面临的挑战是直接从原始像素中学习以产生操作。这种复杂性使得第一人称多人游戏成为人工智能社区一个非常活跃而且得到许多成果的研究领域。
我们的这项工作关注的游戏是《雷神之锤III竞技场》(我们对其进行了一些美术上的修改,但所有游戏机制保持不变)。《雷神之锤III竞技场》是为许多现代第一人称视频游戏奠定了基础,并吸引了长期以来竞争激烈的电子竞技场面。我们训练智能体作为个体学习和行动,但必须能够与其他智能体或人类组成团队作战。
CTF(Capture The Flag)的游戏规则很简单,但是动态很复杂。在Quake3里分成蓝红两队在给定的地图中竞赛。竞赛的目的是将对方的旗子带回来,并且碰触未被移动过的我方旗子,我队就得一分,称作一个capture。为了获得战术上的优势,他们可以会碰触地方的队员(tagging),把他们送回自己的地盘。在五分钟内capture到最多旗子的队伍获胜。
从多智能体的角度看,CTF要求队员既要成功地与队友合作,又要与对方敌手竞争,同时在可能遇到的任何比赛风格中保持稳健性。
FTW智能体:等级分远超基线方法和人类玩家
为了使事情更有趣,我们设计了CTF的一种变体,令地图的布局在每一场竞赛中发生改变。这样,我们的智能体被迫要采用一般性策略,而不是记住地图的布局。此外,为了让游戏更加公平,智能体要以类似于人类的方式体验CTF的世界:它们观察一系列的像素图像,并通过模拟游戏控制器发出动作。
CTF是在程序生成的环境中执行的,因此,智能体必须要适应不可见的地图。
智能体必须从头开始学习如何在不可见(unseen)的环境中观察、行动、合作和竞争,所有这些都来自每场比赛的一个强化信号:他们的团队是否获胜。这是一个具有挑战性的学习问题,它的解决方法基于强化学习的三个一般思路:
我们不是训练一个智能体,而是训练一群智能体,它们通过组队玩游戏来学习,提供了多样化的队友和敌手。
群体中的每个智能体都学习自己的内部奖励信号,这些信号使得智能体能够产生自己的内部目标,例如夺取一面旗子。双重优化过程可以直接为了获胜优化智能体的内部奖励,并使用内部奖励的强化学习来学习智能体的策略。
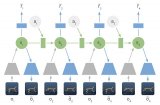
智能体在两个时间尺度上运行,快速和慢速,这提高了它们使用内存和产生一致动作序列的能力。
图: For The Win (FTW)智能体架构的示意图。该智能体将快速和慢速两个时间尺度的循环神经网络(RNN)相结合,包括一个共享记忆模块,并学习从游戏点到内部奖励的转换。
由此产生的智能体,我们称之为For The Win(FTW)智能体,它学会了以非常高的标准玩CTF。最重要的是,学会的智能体策略对地图的大小、队友的数量以及团队中的其他参与者都具有稳健性。
下面演示了FTW智能体互相竞争的室外程序环境游戏,以及人类和智能体竞争的室内程序环境的游戏。
图:交互式CTF游戏浏览器,分别有室内和室外的程序生成环境。室外地图游戏是FTW智能体相互之间的竞赛,而室内地图上的游戏则是人类与FTW智能体之间的竞赛(见图标)。
我们举办了一场比赛,包括40名人类玩家。在比赛中,人类和智能体都是随机配对的——可以作为敌手或者作为队友。
一场早期的测试比赛,由人类与训练好的智能体一起玩CTF。
FTW智能体学会的比强大的基线方法更强,并超过人类玩家的胜率。事实上,在一项对参与者的调查中,它们被认为比人类参与者更具有合作精神。
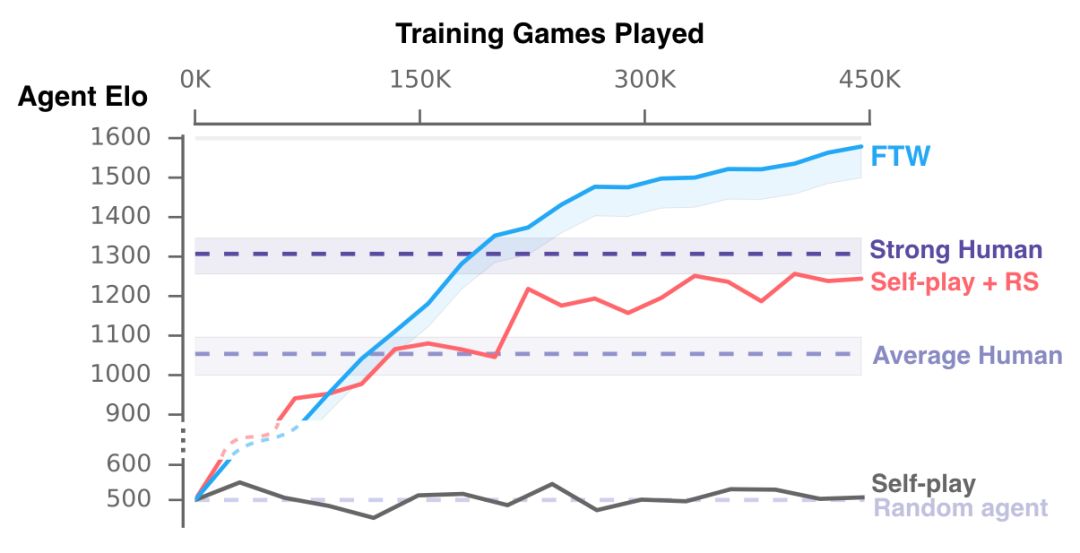
训练期间我们的智能体的表现。我们新的FTW智能体相比人类玩家和Self-play + RS和Self-play的基线方法获得了更高的Elo等级分——获胜的概率也更高。
除了性能评估之外,理解这些智能体的行为和内部表示的复杂性是很重要的。
为了理解智能体如何表示游戏状态,我们研究了在平面上绘制的智能体的神经网络的激活模式。下图中的点表示游戏过程中的情况,近处的点表示类似的激活模式。这些点是根据高级CTF游戏状态进行着色的,在这些状态中智能体要问自己:智能体在哪个房间?旗子的状态是怎样的?可以看到哪些队友和敌手?我们观察到相同颜色的集群,表明智能体以类似的方式表示类似的高级游戏状态。
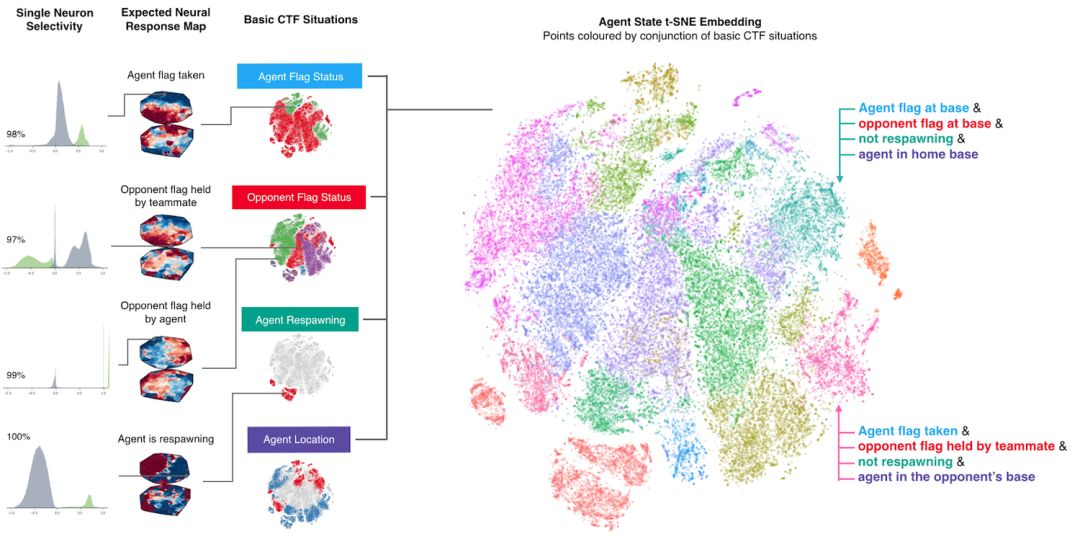
智能体如何表示游戏世界。不同的情形在概念上对应于同一游戏情境,并由智能体相似地表示出来。训练好的智能体甚至展示了一些人工神经元,这些神经元直接为特定情况编码。
智能体从未被告知游戏的规则,但是它可以学习基本的游戏概念,并能有效地建立CTF直觉。事实上,我们可以找到一些特定的神经元,它们可以直接编码一些最重要的游戏状态,比如当智能体的旗子被夺走时激活的神经元,或者当它的队友夺到对方的旗子时激活的神经元。我们在论文中进一步分析了智能体对记忆和视觉注意力的使用。
除了这种丰富的表示,智能体还会如何行动呢?首先,我们注意到这些智能体的反应时间非常快,tagging也非常准确,这可以解释为它们的性能。但是,通过人为地降低tagging的准确度和反应时间,我们发现这只是它们成功的因素之一。
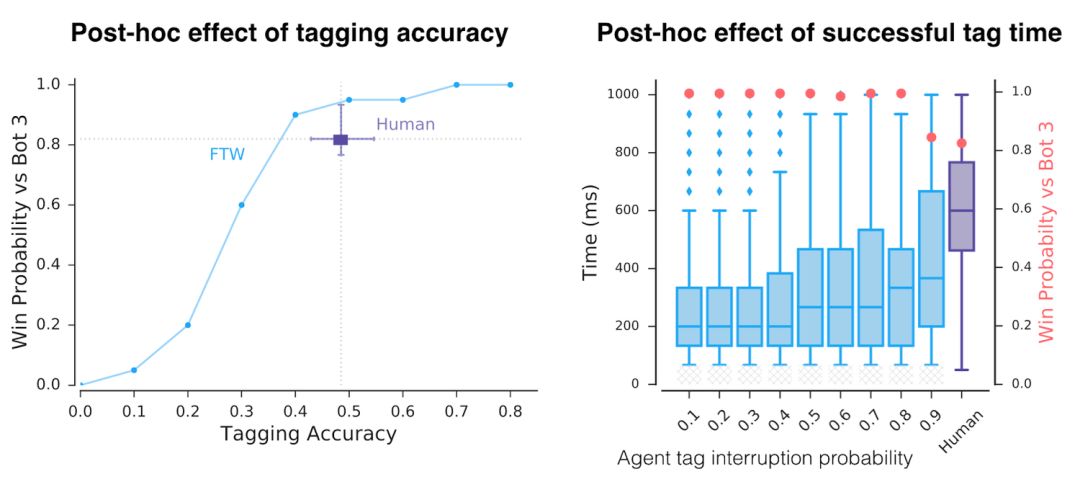
训练后人为地降低了智能体的tagging精度和tagging反应时间。即使在具有于人类相当的准确度和反应时间下,智能体的性能仍高于人类。
通过无监督学习,我们建立了智能体和人类的原型行为( prototypical behaviours),发现智能体实际上学习了类似人类的行为,例如跟随队友并在对手的基地扎营。

训练好的智能体表现出来的自动发现行为的3个例子。
这些行为出现在训练过程中,通过强化学习和群体层面的进化,一些行为——比如跟随队友——随着智能体学会以更加互补的方式合作而减少。
左上方显示的是30个智能体在训练和发展过程中的Elo等级分。右上角显示了这些进化事件的遗传树( genetic tree)。下方的图表显示了整个智能体训练过程中知识的发展,一些内部奖励,以及行为概率。
总结和展望
最近,研究界在复杂游戏领域做出了非常令人印象深刻的工作,例如星际争霸2和Dota 2。我们的这篇论文聚焦于《雷神之锤III竞技场》的夺旗模式,它的研究贡献是具有普遍性的。我们很希望看到其他研究人员在不同的复杂环境中重建我们的技术。未来,我们还希望进一步改进目前的强化学习和群体训练方法。总的来说,我们认为这项工作强调了多智能体训练对促进人工智能发展的潜力:利用多智能体训练的自然设置,并促进强大的、甚至能与人类合作的智能体的开发。
-
人工智能
+关注
关注
1793文章
47590浏览量
239486 -
智能体
+关注
关注
1文章
163浏览量
10603 -
DeepMind
+关注
关注
0文章
131浏览量
10906
原文标题:【DOTA之后新里程碑】DeepMind强化学习重大突破:AI在多人射击游戏完胜人类!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
未来的AI 深挖谷歌 DeepMind 和它背后的技术
介绍多智能体系统的解决方案以及应用
华为公司在3G专利方面的进展
机器学习简单运用方面的基础知识

袁进辉:分享了深度学习框架方面的技术进展
意法半导体展示其在功率GaN方面的研发进展
谷歌在量子计算机学习任务方面取得新进展
谷歌、DeepMind重磅推出PlaNet 强化学习新突破
DeepMind 综述深度强化学习 智能体和人类相似度竟然如此高
DeepMind阿尔法被打脸,华为论文指出多项问题

内存计算IMC用于人工智能加速方面的研究进展
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路






 工商网监
工商网监
评论